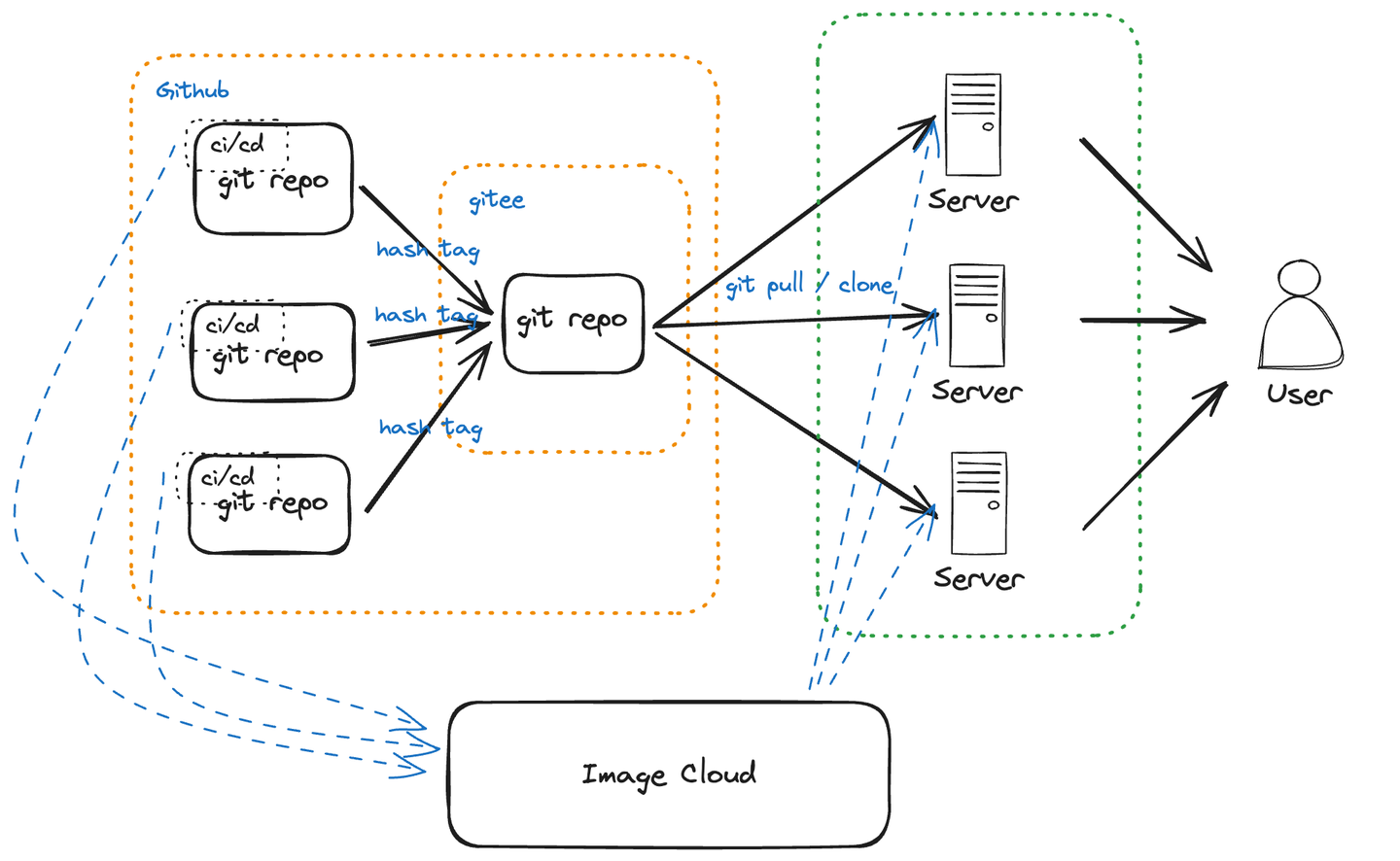
AI视野·今日CS.Robotics 机器人学论文速览
Tue, 5 Mar 2024
Totally 63 papers
👉上期速览✈更多精彩请移步主页

Interesting:
📚双臂机器人拧瓶盖, (from 伯克利)
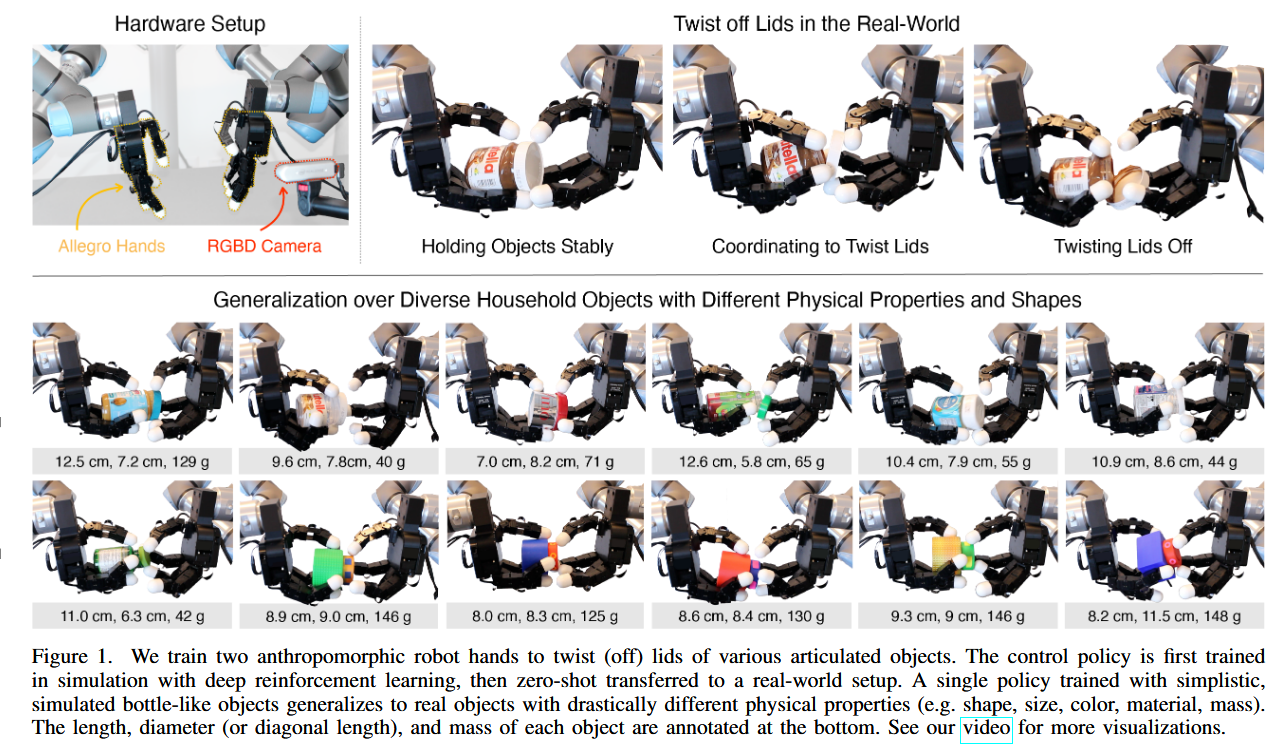
website: https://toruowo.github.io/bimanual-twist
📚水下抓取器, (from TUM eAviation Group )
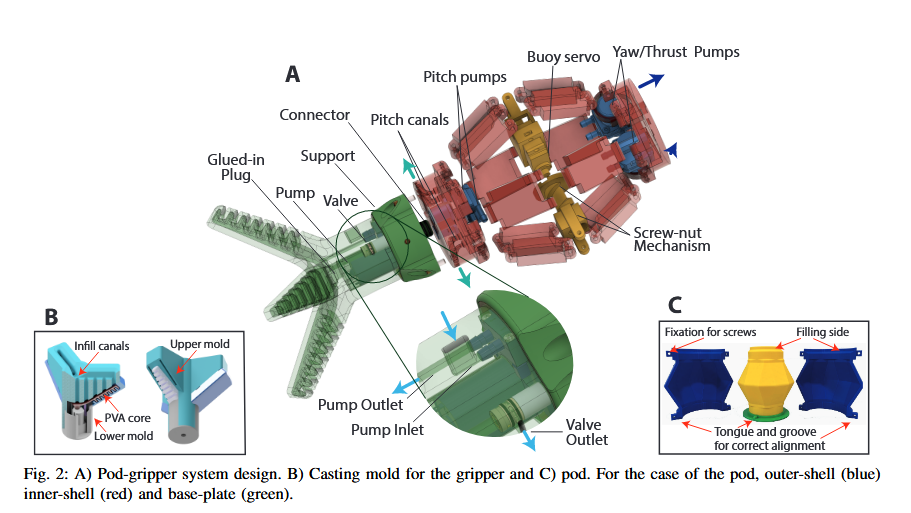
📚鼠鼠机器人脊柱对于运动的辅助, (from TUM)
Daily Robotics Papers
| Twisting Lids Off with Two Hands Authors Toru Lin, Zhao Heng Yin, Haozhi Qi, Pieter Abbeel, Jitendra Malik 用两只多指手操纵物体一直是机器人技术中长期存在的挑战,这归因于许多操纵任务的接触丰富性以及协调高维双手系统固有的复杂性。在这项工作中,我们考虑了用两只手扭转各种瓶子类物体的盖子的问题,并证明使用深度强化学习进行模拟训练的策略可以有效地转移到现实世界。凭借对物理建模、实时感知和奖励设计的新颖工程见解,该策略展示了跨各种看不见的物体的泛化能力,展示了动态和灵巧的行为。 |
| Designing Library of Skill-Agents for Hardware-Level Reusability Authors Jun Takamatsu, Daichi Saito, Katsushi Ikeuchi, Atsushi Kanehira, Kazuhiro Sasabuchi, Naoki Wake 为了在新环境中使用新的机器人硬件,有必要开发适合该环境中特定机器人的控制程序。考虑机器人之间软件的可重用性对于最大限度地减少此过程中涉及的工作量并最大限度地提高不同环境中不同机器人之间的软件重用至关重要。本文提出了一种通过考虑硬件级可重用性、使用从观察 LfO 范式和预先设计的技能代理库中学习来弥补这一过程的方法。 LfO 框架以独立于硬件的表示(称为任务模型)表示所需的操作,通过观察人类演示,捕获环境与机器人之间交互的必要参数。当从任务模型执行所需的动作时,采用一组技能代理将表示转换为机器人命令。本文重点关注 LfO 框架的后半部分,利用该集合从任务模型生成机器人动作,并探索这些技能代理的硬件独立设计方法。考虑到机器人手部位置与环境之间的相对关系,这些技能代理以独立于硬件的方式进行描述。因此,只需交换逆运动学求解器,就可以在具有不同硬件配置的机器人上执行这些动作。本文首先定义了一个必要且充分的技能代理集,以覆盖所有可能的动作,并考虑了库中这些技能代理的设计原则。 |
| Uncertainty-Aware Prediction and Application in Planning for Autonomous Driving: Definitions, Methods, and Comparison Authors Wenbo Shao, Jiahui Xu, Zhong Cao, Hong Wang, Jun Li 自动驾驶系统面临着在复杂且充满不确定性的动态环境中航行的巨大挑战。本研究提出了一个统一的预测和规划框架,同时对短期任意不确定性 SAU 、长期任意不确定性 LAU 和认知不确定性 EU 进行建模,以预测并为动态环境中的规划奠定坚实的基础。该框架使用高斯混合模型和深度集成方法,同时捕获和评估 SAU、LAU 和 EU,而传统方法不能同时集成这些不确定性。此外,考虑到各种不确定性,引入了不确定性意识规划。该研究的贡献包括不确定性估计、风险建模和规划方法与现有方法的比较。使用 CommonRoad 基准和感知有限的设置对所提出的方法进行了严格评估。这些实验阐明了自动驾驶过程中不同不确定性因素的优势和作用。此外,对各种不确定性建模策略的比较评估强调了对多种类型的不确定性进行建模的好处,从而提高了规划的准确性和可靠性。所提出的框架促进了 UAP 方法的开发,并超越了现有的不确定性风险模型,特别是在考虑不同的交通场景时。 |
| Tightly-Coupled LiDAR-Visual-Inertial SLAM and Large-Scale Volumetric Occupancy Mapping Authors Simon Boche, Sebasti n Barbas Laina, Stefan Leutenegger 自主导航是现实世界中移动机器人每一个潜在应用的关键要求之一。除了高精度状态估计之外,适当且全局一致的 3D 环境表示也是必不可少的。我们提出了一个完全紧密耦合的 LiDAR 视觉惯性 SLAM 系统和 3D 映射框架,应用局部子映射策略来实现大规模环境的可扩展性。引入了一种新颖且无对应性、本质上概率的 LiDAR 残差公式,仅以占用场及其各自的梯度来表示。这些残差可以添加到因子图优化问题中,或者作为用于实时估计的框架到映射因子,或者作为相对于彼此对齐子图的映射到映射因子。 |
| NatSGD: A Dataset with Speech, Gestures, and Demonstrations for Robot Learning in Natural Human-Robot Interaction Authors Snehesh Shrestha, Yantian Zha, Saketh Banagiri, Ge Gao, Yiannis Aloimonos, Cornelia Fermuller 多模式人机交互 HRI 数据集的最新进展突出了语音和手势的融合,扩展了机器人吸收显式和隐式 HRI 见解的能力。然而,现有的语音手势 HRI 数据集通常专注于基本任务,例如对象指向和推动,揭示了扩展到复杂领域以及优先考虑人类命令数据而不是机器人行为记录方面的局限性。为了弥补这些差距,我们引入了 NatSGD,这是一个多模式 HRI 数据集,包含通过自然的语音和手势发出的人类命令,与机器人行为演示同步。 NatSGD 是机器学习和 HRI 研究交叉点的基础资源,我们展示了它在训练机器人通过多模式人类命令理解任务方面的有效性,强调了共同考虑语音和手势的重要性。 |
| Structure from WiFi (SfW): RSSI-based Geometric Mapping of Indoor Environments Authors Junseo Kim, Jill Aghyourli Zalat, Yeganeh Bahoo, Sajad Saeedi 随着 WiFi 在公共空间中的重要性日益凸显,机器人社区已努力利用这一事实,将 WiFi 信号测量纳入室内 SLAM 同时定位和建图系统中。 SLAM 在广泛的应用中至关重要,尤其是在自主机器人的控制中。本文介绍了基于 WiFi 的定位开发的最新工作,并解决了当前在实现基于 WiFi 的几何映射方面面临的挑战。受 k 可见性研究领域的启发,本文提出了逆 k 可见性的概念,并提出了一种新颖的算法,允许机器人构建未知环境的自由空间地图,这对于规划、导航和避开障碍物至关重要。 |
| LiSTA: Geometric Object-Based Change Detection in Cluttered Environments Authors Joseph Rowell, Lintong Zhang, Maurice Fallon 我们推出了 LiSTA LiDAR Spatio Temporal Analysis,这是一种使用多任务 SLAM 检测概率对象级别随时间变化的系统。许多应用都需要这样的系统,包括建筑、机器人导航、长期自主和环境监测。我们专注于半静态场景,其中对象在数周或数月内添加、减少或改变位置。我们的系统结合了多任务 LiDAR SLAM、体积差分、对象实例描述和使用学习描述符的对应分组来跟踪一组开放的对象。任务之间的对象对应关系是通过对对象学习的描述符进行聚类来确定的。我们使用在模拟环境中收集的数据集和使用安装在四足机器人上的激光雷达系统捕获的现实世界数据集来演示我们的方法,该系统监视包含静态、半静态和动态物体的工业设施。 |
| Cross Domain Policy Transfer with Effect Cycle-Consistency Authors Ruiqi Zhu, Tianhong Dai, Oya Celiktutan 由于样本效率低下,使用深度强化学习方法从头开始训练机器人策略可能会非常昂贵。为了应对这一挑战,将源域中训练的策略转移到目标域成为一种有吸引力的范例。以前的研究通常集中在具有相似状态和动作空间但在其他方面不同的领域。在本文中,我们的主要关注点在于具有不同状态和动作空间的领域,这具有更广泛的实际意义,即将策略从机器人 A 转移到机器人 B。与依赖配对数据的先前方法不同,我们提出了一种新的学习方法使用不成对的数据跨域的状态和动作空间之间的映射函数。我们提出了效果循环一致性,它通过学习这些映射函数的对称优化结构来调整两个域之间转换的效果。一旦学习了映射函数,我们就可以将策略从源域无缝传输到目标域。我们的方法已经在三个运动任务和两个机器人操作任务上进行了测试。 |
| Skater: A Novel Bi-modal Bi-copter Robot for Adaptive Locomotion in Air and Diverse Terrain Authors Junxiao Lin, Ruibin Zhang, Neng Pan, Chao Xu, Fei Gao 在这封信中,我们提出了一种名为 Skater 的新型双模态双旋翼机器人,它能够适应空气和各种地面。 Skater 由一个沿其纵向移动的双轴飞行器组成,两侧有两个被动轮。该机器人采用纵向布置的双轴飞行器作为空中和地面两种模式的统一驱动系统,不仅保持了简洁、轻量化的机构,而且还具有出色的地形穿越能力和强大的转向能力。此外,利用双轴飞行器的矢量推力特性,Skater可以主动产生转向所需的向心力,使其即使在光滑的表面上也能实现稳定的运动。此外,我们对溜冰者的综合动力学进行建模,分析其差分平坦度,并引入使用非线性模型预测控制进行轨迹跟踪的控制器。 |
| TTA-Nav: Test-time Adaptive Reconstruction for Point-Goal Navigation under Visual Corruptions Authors Maytus Piriyajitakonkij, Mingfei Sun, Mengmi Zhang, Wei Pan 视觉损坏下的机器人导航提出了巨大的挑战。为了解决这个问题,我们提出了一种测试时间适应 TTA 方法,称为 TTA Nav,用于视觉损坏下的点目标导航。我们的即插即用方法将自上而下的解码器与预先训练的导航模型结合起来。首先,预先训练的导航模型获取损坏的图像并提取特征。其次,自上而下的解码器根据预训练模型提取的高级特征进行重建。然后,它将损坏图像的重建反馈给预先训练的模型。最后,预训练的模型再次前向传递以输出动作。尽管仅在干净图像上进行训练,但自上而下的解码器可以从损坏的图像中重建更干净的图像,而不需要基于梯度的适应。带有自上而下解码器的预训练导航模型显着增强了基准测试中几乎所有视觉损坏的导航性能。我们的方法将点目标导航的成功率从最先进的结果 46 提高到 94(在最严重的损坏情况下)。 |
| An Efficient Model-Based Approach on Learning Agile Motor Skills without Reinforcement Authors Haojie Shi, Tingguang Li, Qingxu Zhu, Jiapeng Sheng, Lei Han, Max Q. H. Meng 基于学习的方法通过深度强化学习提高了四足机器人的运动技能。然而,模拟与真实的差距和低样本效率仍然限制了技能转移。为了解决这个问题,我们提出了一种基于模型的有效学习框架,它将世界模型与政策网络相结合。我们训练一个可微的世界模型来预测未来状态,并用它来直接监督基于变分自动编码器 VAE 的策略网络来模仿真实的动物行为。这显着减少了对真实交互数据的需求,并允许快速更新策略。我们还开发了一个高级网络来跟踪不同的命令和轨迹。我们的模拟结果显示,与 PPO 等强化学习方法相比,样本效率提高了十倍。 |
| ZSL-RPPO: Zero-Shot Learning for Quadrupedal Locomotion in Challenging Terrains using Recurrent Proximal Policy Optimization Authors Yao Zhao, Tao Wu, Yijie Zhu, Xiang Lu, Jun Wang, Haitham Bou Ammar, Xinyu Zhang, Peng Du 我们提出了 ZSL RPPO,这是一种改进的零样本学习架构,它克服了师生神经网络的局限性,并能够在具有挑战性的地形中为四足机器人生成稳健、可靠和多功能的运动。我们提出了一种新算法 RPPO 循环近端策略优化,该算法直接在部分可观察的环境中训练循环神经网络,并使用域随机化产生更稳健的训练。我们的运动控制器支持从模拟到现实传输的内在和外在物理参数的广泛扰动,无需进一步微调。这可以避免学生在模拟到现实迁移过程中表现的显着下降,从而增强运动控制器的鲁棒性和泛化性。我们在真实环境中的 Unitree A1 和 Aliengo 机器人上部署了控制器,并由固态激光雷达或深度相机提供外感知。我们的运动控制器在各种具有挑战性的地形(例如光滑的表面、草地地形和楼梯)中进行了测试。 |
| Gotta catch 'em all, safely! Aerial-deployed soft underwater gripper Authors Luca Romanello, Daniel Joseph Amir, Heinrich Stengel, Mirko Kovac, Sophie F. Armanini 水下软夹具展现出监测、研究和物体检索等应用的潜力。然而,现有的水下抓取技术经常对生态系统造成干扰。为了应对这一挑战,我们提出了一种新颖的水下抓取框架,包括固定在可通过无人机部署的定制潜艇吊舱上的轻型抓取器。这种方法可以最大限度地减少水扰动,并能够有效导航到目标区域,从而提高整体任务效率。该吊舱允许水下运动,具有四个自由度。它配备了定制的浮力系统、两个用于差动推力的水泵和两个用于俯仰的水泵。该系统允许浮力调节深度达 6 米,以及在平面上运动。该 3 指夹具由硅胶制成,并在不同形状和尺寸的物体上成功进行了测试,展示了水下时最大拉力高达 8 N。通过在水箱中跟踪其姿态和抓取动作期间的能量消耗来测试潜艇吊舱的可靠性。该系统还在湖中成功完成了任务,并部署在六轴飞行器上。 |
| Aerial Tensile Perching and Disentangling Mechanism for Long-Term Environmental Monitoring Authors Tian Lan, Luca Romanello, Mirko Kovac, Sophie F. Armanini, Basaran Bahadir Kocer 空中机器人通过提供高空间和时间分辨率的数据收集能力,在森林冠层研究和环境监测方面显示出巨大的潜力。然而,有限的飞行续航能力阻碍了它们的应用。受自然栖息行为的启发,我们提出了一种多模式空中机器人系统,该系统集成了用于节能的拉伸栖息和用于数据收集的悬挂驱动吊舱。该系统由四旋翼无人机、允许 360 度系绳旋转的回转环机构以及带有两个通过系绳连接的涵道螺旋桨的流线型吊舱组成。缠绕和松开系绳可以让吊舱在树冠内移动,启动螺旋桨可以让系绳缠绕在树枝上以栖息或解开。我们通过实验确定了在各种条件下稳定栖息所需的最小配重。在此基础上,我们设计并评估了多种栖息和解开策略。栖息和解开动作的比较表明,通过使用吊舱或系绳缠绕可以进一步最大限度地节省能源。与无人机解缠动作相比,这些方法可以将能耗分别降低至 22 和 1.5。我们还计算了系统停顿和电机关闭后所提议的系统所需的最短空闲时间,以节省任务中的能源,这是运行时间的 48.9 倍。 |
| AiSDF: Structure-aware Neural Signed Distance Fields in Indoor Scenes Authors Jaehoon Jang, Inha Lee, Minje Kim, Kyungdon Joo 我们生活的室内场景在视觉上是同质的或无纹理的,但它们本质上具有结构形式,并为 3D 场景重建提供足够的结构先验。受此事实的启发,我们提出了一种室内场景中的结构感知在线符号距离场 SDF 重建框架,特别是在亚特兰大世界 AW 假设下。因此,我们将 AW 的增量 SDF 重建称为 AiSDF。在在线框架内,我们推断给定场景的底层亚特兰大结构,然后估计支持亚特兰大结构的平面面元区域。这种亚特兰大感知面元表示为给定场景提供了明确的平面地图。此外,基于这些亚特兰大平面面元区域,我们自适应地采样并约束 SDF 重建中的结构规律,这使我们能够通过保持高级结构同时增强给定场景的细节来提高重建质量。 |
| RT-H: Action Hierarchies Using Language Authors Suneel Belkhale, Tianli Ding, Ted Xiao, Pierre Sermanet, Quon Vuong, Jonathan Tompson, Yevgen Chebotar, Debidatta Dwibedi, Dorsa Sadigh 语言提供了一种将复杂概念分解为易于理解的部分的方法。机器人模仿学习的最新工作使用语言条件策略来预测给定视觉观察和语言中指定的高级任务的动作。这些方法利用自然语言的结构在语义相似的任务之间共享数据,例如,在多任务数据集中挑选可乐罐和挑选苹果。然而,随着任务在语义上变得更加多样化,例如,拿起可乐罐和倒杯子,任务之间共享数据变得更加困难,因此学习将高级任务映射到操作需要更多的演示数据。为了弥合任务和动作,我们的见解是教机器人动作语言,用更细粒度的短语(例如“向前移动手臂”)描述低级动作。将这些语言动作预测为任务和动作之间的中间步骤,迫使策略学习看似不同的任务中低级动作的共享结构。此外,以语言动作为条件的策略可以在执行过程中通过人类指定的语言动作轻松纠正。这为灵活的政策提供了一种新的范式,可以从人类对语言的干预中学习。我们的方法 RT H 使用语言动作构建动作层次结构,它首先学习预测语言动作,并以此和高级任务为条件,在所有阶段使用视觉上下文来预测动作。我们表明,RT H 利用这种语言动作层次结构,通过有效利用多任务数据集来学习更强大、更灵活的策略。我们表明,这些政策不仅可以对语言干预做出反应,而且还可以从此类干预中学习,并且优于从远程操作干预中学习的方法。 |
| SAQIEL: Ultra-Light and Safe Manipulator with Passive 3D Wire Alignment Mechanism Authors Temma Suzuki, Masahiro Bando, Kento Kawaharazuka, Kei Okada, Masayuki Inaba 提高协作机械手的安全性需要减少运动部件的惯性。在本文中,我们介绍了一种被动 3D 线对准器形式的新颖方法,作为一种轻质、低摩擦的动力传输机构,从而在机械手操作中实现所需的低惯性。通过利用这一创新,将重型执行器整合到根连杆上变得可行,从而实现以最小摩擦为特征的灵活驱动。为了证明该设备的功效,我们制造了一个名为 SAQIEL 的超轻 7 自由度 DoF 机械臂,其移动部件的重量仅为 1.5 千克。值得注意的是,为了减轻 SAQIEL 驱动系统内的摩擦,我们采用了一种独特的机构,可以使用电机直接缠绕电线,从而无需传统的齿轮或皮带减速机构。 |
| Improving Visual Perception of a Social Robot for Controlled and In-the-wild Human-robot Interaction Authors Wangjie Zhong, Leimin Tian, Duy Tho Le, Hamid Rezatofighi 社交机器人通常依靠视觉感知来了解用户和环境。计算机视觉数据驱动方法的最新进展表明,应用深度学习模型来增强社交机器人的视觉感知具有巨大潜力。然而,与资源效率更高的浅层学习模型相比,深度学习方法的高计算要求提出了有关其对现实世界交互和用户体验的影响的重要问题。目前尚不清楚当社交机器人采用基于深度学习的视觉感知模型时,客观交互性能和主观用户体验将如何受到影响。我们采用最先进的人类感知和跟踪模型来改善 Pepper 机器人的视觉感知功能,并进行了受控实验室研究和野外人类机器人交互研究,以评估这种新颖的感知功能,以跟踪特定用户与其他人 |
| Offline Goal-Conditioned Reinforcement Learning for Safety-Critical Tasks with Recovery Policy Authors Chenyang Cao, Zichen Yan, Renhao Lu, Junbo Tan, Xueqian Wang 离线目标条件强化学习 GCRL 旨在通过离线数据集的稀疏奖励来解决目标达成任务。虽然之前的工作已经证明了代理学习接近最优策略的各种方法,但这些方法在处理复杂环境中的各种约束(例如安全约束)时遇到了局限性。其中一些方法优先考虑目标的实现而不考虑安全性,而另一些方法则过度关注安全而牺牲了培训效率。在本文中,我们研究了约束离线 GCRL 问题,并提出了一种称为基于恢复的监督学习 RbSL 的新方法来完成具有各种目标的安全关键任务。为了评估方法性能,我们基于具有随机定位障碍物的机器人抓取环境构建基准,并使用专家或随机策略生成离线数据集。我们将 RbSL 与三种离线 GCRL 算法和一种离线安全 RL 算法进行比较。因此,我们的方法在很大程度上优于现有的最先进的方法。此外,我们通过将 RbSL 部署在真实的 Panda 机械臂上验证了 RbSL 的实用性和有效性。 |
| Sensor-based Multi-Robot Search and Coverage with Spatial Separation in Unstructured Environments Authors Xinyi Wang, Jiwen Xu, Chuanxiang Gao, Yizhou Chen, Jihan Zhang, Chenggang Wang, Ben M. Chen 多机器人系统在解决搜索和覆盖问题方面日益发挥作用。 |
| Tac-Man: Tactile-Informed Prior-Free Manipulation of Articulated Objects Authors Zihang Zhao, Yuyang Li, Wanlin Li, Zhenghao Qi, Lecheng Ruan, Yixin Zhu, Kaspar Althoefer 将机器人技术集成到以人为中心的环境(例如家庭)中,需要先进的操作技能,因为机器人设备需要与门和抽屉等铰接物体接合。机器人操纵的主要挑战是这些物体内部结构的不可预测性和多样性,这使得基于先验的模型(无论是显式的还是隐式的)都不充分。它们的可靠性因相互作用前的模糊性、不完善的结构参数、与未知物体的遭遇以及不可预见的干扰而显着降低。在这里,我们提出了一种先前的自由策略 Tac Man,专注于在操作过程中保持稳定的机器人物体接触。 Tac Man 利用触觉反馈,但独立于物体先验,使机器人能够熟练地处理各种铰接物体,包括具有复杂关节的物体,即使受到意外干扰的影响也是如此。在现实世界的实验和广泛的模拟中都得到了证明,它在动态和变化的环境中始终取得近乎完美的成功,优于现有方法。我们的结果表明,仅触觉传感就足以管理各种铰接式物体,比以前的方法提供更好的鲁棒性和通用性。这强调了复杂操作任务中详细接触建模的重要性,特别是对于铰接物体。 |
| ASPIRe: An Informative Trajectory Planner with Mutual Information Approximation for Target Search and Tracking Authors Kangjie Zhou, Pengying Wu, Yao Su, Han Gao, Ji Ma, Hangxin Liu, Chang Liu 本文提出了一种信息轨迹规划方法,即带有基于西格玛点的互信息奖励近似ASPIRe的textit自适应粒子滤波器树,用于在传感视场有限的杂乱环境中移动目标搜索和跟踪SAT。我们开发了一种新颖的基于西格玛点的近似,利用置信状态的粒子表示来准确估计一般非高斯分布的互信息 MI,同时保持高计算效率。基于 MI 近似,我们开发了以 MI 作为奖励的自适应粒子滤波器树 APFT 方法,该方法具有信念状态树节点,用于连续状态和测量空间中的信息轨迹规划。 APFT 中提出了一种自适应准则,用于根据预期信息增益调整规划范围。 |
| A Human-Centered Approach for Bootstrapping Causal Graph Creation Authors Minh Q. Tram, Nolan B. Gutierrez, William J. Beksi 因果推理是经济学、基因组学和医学等学科的基石,越来越多地被认为是推动机器人领域发展的基础。特别是,从观测数据推断因果关系的能力对于机器人系统的稳健泛化至关重要。然而,构建因果图模型(一种表示因果关系的机制)提出了巨大的挑战。目前,对因果推理的细致掌握,加上对因果关系的理解,必须手动编程到因果图模型中。为了解决这个困难,我们提出了用于创建因果图形模型的以人为中心的增强现实框架的初步结果。具体来说,我们的系统通过让人类参与选择变量、建立关系、执行干预、生成反事实解释以及评估每一步生成的因果图来引导因果发现过程。 |
| The Grasp Loop Signature: A Topological Representation for Manipulation Planning with Ropes and Cables Authors Peter Mitrano, Dmitry Berenson 机器人操纵可变形的一维物体 DOO(例如绳索或电缆)在制造、农业和外科手术中具有重要的潜在应用。在这种环境中,任务可能涉及穿过或避免与架子或框架等物体缠结。使用多个夹具进行抓取可以在机器人和 DOO 之间形成闭环,如果该环内有障碍物,则可能无法到达目标。然而,之前的工作仅考虑了 DOO 的拓扑结构,忽略了操纵它的手臂。在不考虑此类拓扑信息的情况下搜索可能的把握来完成任务的效率非常低,因为由于拓扑限制,许多把握不会导致任务取得进展。因此,我们提出了一个抓取循环签名,它对这些抓取循环的拓扑进行分类,并展示如何使用它来指导规划。我们对两个 DOO 操作任务进行了模拟实验,以表明使用签名比依赖局部几何或有限视野规划的方法更快、更成功。 |
| ComTraQ-MPC: Meta-Trained DQN-MPC Integration for Trajectory Tracking with Limited Active Localization Updates Authors Gokul Puthumanaillam, Manav Vora, Melkior Ornik 在部分可观察的随机环境中,轨迹跟踪的最佳决策提出了重大挑战,其中主动定位更新代理从传感器获取其真实状态信息的过程的数量有限。传统方法常常难以平衡资源节约、准确状态估计和精确跟踪,从而导致性能不佳。这个问题在具有大动作空间的环境中尤其明显,其中对频繁、准确的状态数据的需求至关重要,但主动定位更新的能力受到外部限制的限制。本文介绍了 ComTraQ MPC,这是一种新颖的框架,它结合了 Deep Q Networks DQN 和模型预测控制 MPC,通过受约束的主动定位更新来优化轨迹跟踪。元训练的 DQN 确保自适应主动定位调度,而 MPC 利用可用的状态信息来改进跟踪。这项工作的核心贡献是它们的相互交互,DQN 的更新决策告知 MPC 的控制策略,而 MPC 的结果完善了 DQN 的学习,创建了一个有凝聚力的自适应系统。 |
| Human Robot Pacing Mismatch Authors Muchen Sun, Peter Trautman, Todd Murphey 对于机器人与人类一起规划过于谨慎或过于激进的轨迹的一种广泛接受的解释是,人群密度超过了阈值,因此所有可行的轨迹都被认为是不安全的冻结机器人问题。然而,即使人群密度较低,机器人在靠近人类时的导航性能仍然会急剧下降。在这项工作中,我们认为,人类附近导航性能欠佳的更广泛原因是机器人对人类与他人共享空间的灵活性意愿的误判,特别是当机器人假设人类的灵活性在交互过程中保持不变时,我们称之为人类机器人步调不匹配的现象。我们证明,解决步调不匹配的必要条件是对机器人和人类在决策过程中的灵活性的演变进行建模,这种策略称为分布空间建模。 |
| Mixed-Strategy Nash Equilibrium for Crowd Navigation Authors Muchen Sun, Francesca Baldini, Peter Trautman, Todd Murphey 我们解决了寻找人群导航的混合策略纳什均衡的问题。混合策略纳什均衡为机器人提供了一个严格的模型来预测人群中不确定但合作的人类行为,但计算成本对于可扩展和实时决策来说通常太高。在这里,我们证明了一个简单的迭代贝叶斯更新方案收敛于混合策略社交导航游戏的纳什均衡。此外,我们提出了一个数据驱动框架,通过将代理策略初始化为从人类数据集中学习的高斯过程来构建游戏。基于所提出的混合策略纳什均衡模型,我们开发了一种基于采样的人群导航框架,该框架可以集成到现有的导航方法中并在笔记本电脑CPU上实时运行。我们在模拟环境和非结构化环境中的真实人类数据集中评估我们的框架。 |
| Fast Ergodic Search with Kernel Functions Authors Muchen Sun, Ayush Gaggar, Peter Trautman, Todd Murphey 遍历搜索可以实现信息分布的最优探索,同时保证搜索空间的渐近覆盖。然而,当前的方法通常在搜索空间维度上具有指数计算复杂度并且仅限于欧几里得空间。我们引入了一种计算高效的遍历搜索方法。我们的贡献是双重的。首先,我们开发一个基于内核的遍历度量并将其从欧几里得空间推广到李群。我们正式证明所提出的度量与标准遍历度量一致,同时保证搜索空间维度的线性复杂度。其次,我们推导了非线性系统的核遍历度量的一阶最优性条件,这使得有效的轨迹优化成为可能。综合数值基准表明,所提出的方法比最先进的算法至少快两个数量级。最后,我们通过孔插入任务中的钉子演示了所提出的算法。我们将该问题表述为 SE 3 空间中的覆盖任务,并使用 30 秒长的人类演示作为遍历覆盖的先验分布。 |
| Deep Incremental Model Based Reinforcement Learning: A One-Step Lookback Approach for Continuous Robotics Control Authors Cong Li 基于模型的强化学习 MBRL 尝试使用可用的或已学习的模型来提高强化学习的数据效率。这项工作提出了一种一步回溯方法,联合学习潜在空间模型和策略来实现样本高效连续机器人控制,其中利用控制理论知识来降低模型学习难度。具体来说,所谓的一步后退数据被用来促进增量进化模型,这是 MBRL 领域中机器人进化模型的另一种结构化表示。增量进化模型可以准确预测机器人运动,但样本复杂度较低。这是因为所制定的增量进化模型将模型学习难度降低为参数矩阵学习问题,这对于高维机器人应用特别有利。学习到的增量进化模型的想象数据用于补充训练数据,以提高样本效率。 |
| Cooperative Automated Driving for Bottleneck Scenarios in Mixed Traffic Authors M.V. Baumann, J. Beyerer, H.S. Buck, B. Deml, S. Ehrhardt, Ch. Frese, D. Kleiser, M. Lauer, M. Roschani, M. Ruf, Ch. Stiller, P. Vortisch, J.R. Ziehn 联网自动车辆 CAV 将车辆间 V2V 通信纳入其运动规划,预计将为个人和整体交通流量提供广泛的好处。一个常见的限制或必需的先决条件是兼容的 CAV 必须已经在高渗透率的交通中可用。在为用户提供充分利益之前逐步实现这样的渗透率会带来互联驾驶开发中常见的先有鸡还是先有蛋的问题。基于瓶颈交通流的协同驾驶功能的示例,例如在遇到障碍时,我们说明了如何在透明的假设和目标下实现这种渐进式、渐进式的引入。为此,我们从自动化技术、流量、人为因素和市场的角度分析了挑战,并提出了一个原则: 1 考虑每个领域的个性化需求 2 为 0 到 100 之间的任何兼容 CAV 渗透率提供好处以及对未来流量预期发展的向上兼容性 3 可以严格限制合作对任何参与者的负面影响 4 可以通过接近市场的技术来实施。 |
| BronchoCopilot: Towards Autonomous Robotic Bronchoscopy via Multimodal Reinforcement Learning Authors Jianbo Zhao, Hao Chen, Qingyao Tian, Jian Chen, Bingyu Yang, Hongbin Liu 支气管镜检查在肺部疾病的早期诊断和治疗中发挥着重要作用。这个过程要求医生操纵柔性内窥镜到达远端病变,特别是在检查上肺叶气道时需要大量的专业知识。随着人工智能和机器人技术的发展,强化学习RL方法已应用于介入手术机器人的操控中。然而,与利用多模态信息的人类医生不同,当前的大多数强化学习方法都依赖于单一模态,这限制了它们的性能。在本文中,我们提出了 BronchoCopilot,这是一种多模式 RL 代理,旨在获得自主支气管镜检查的操作技能。 BronchoCopilot 专门集成了支气管镜摄像头的图像和估计的机器人姿势,旨在在具有挑战性的气道环境中获得更高的成功率。我们采用辅助重建任务来压缩多模态数据,并利用注意力机制来实现该数据的有效潜在表示,作为 RL 模块的输入。该框架采用逐步训练和微调的方法来减轻训练难度的挑战。我们在真实模拟环境中的评估表明,BronchoCopilot 通过有效利用多模态信息,在第五代气道中以一致的动作获得了约 90 的成功率。 |
| Collision-Free Robot Navigation in Crowded Environments using Learning based Convex Model Predictive Control Authors Zhuanglei Wen, Mingze Dong, Xiai Chen 深度强化学习DRL的出现极大地扩展了自主机器人的应用范围。然而,在拥挤和复杂的环境中安全导航仍然是一个持续的挑战。本研究提出了一种利用 DRL 的机器人导航策略,将观察概念化为凸静态无障碍区域,这与传统上对原始传感器输入的依赖不同。这项工作的新颖性有三重 1 根据机器人的运动学限制和根据 2D LiDAR 传感器数据计算的凸区域,制定包括短期和长期参考点的动作空间。 2 探索将 DRL 与模型预测控制 MPC 相结合的混合解决方案。 3 基于静态无障碍区域、参考点和MPC优化的轨迹,设计定制的状态空间和奖励函数。 |
| DUFOMap: Efficient Dynamic Awareness Mapping Authors Daniel Duberg, Qingwen Zhang, MingKai Jia, Patric Jensfelt 现实世界的动态本质是机器人技术的主要挑战之一。处理这个问题的第一步是检测世界的哪些部分是动态的。典型的基准任务是创建一个仅包含世界静态部分的地图,以支持本地化和规划等工作。当前的解决方案通常应用于后处理,其中参数调整允许用户调整特定数据集的设置。在本文中,我们提出了 DUFOMap,这是一种专为高效在线处理而设计的新型动态感知映射框架。尽管所有场景都具有相同的参数设置,但它的性能更好或与最先进的方法相当。利用射线投射来识别和分类完全观察到的空白区域。由于观察到这些区域是空的,因此在其他时间它们内部的任何东西都必须是动态的。评估在各种场景中进行,包括 KITTI 和 Argoverse 2 的室外环境、KTH 校园的开放区域以及不同的传感器类型。 DUFOMap 在准确性和计算效率方面优于最先进的技术。提供了源代码、基准测试和所使用的数据集的链接。 |
| Localization matters too: How localization error affects UAV flight Authors Suquan Zhang, Yuanfan Xu, Shu ang Yu, Qingmin Liao, Jincheng Yu, Yu Wang 无人机的最大安全飞行速度是衡量其完成各项任务效率的重要指标。该指标受到无人机定位误差、感知范围、系统延迟等众多参数的影响。然而,就定位误差而言,虽然已有很多研究致力于提高无人机的定位能力,但缺乏对其对速度影响的定量研究。在这项工作中,我们对无人机的各种参数与其最大飞行速度之间的关系进行了建模。我们考虑一个类似于在茂密森林中航行的场景,无人机需要快速避开前方的障碍物,并在避开后迅速重新调整方向。基于该场景,我们研究了定位误差等参数如何影响无人机飞行过程中的最大安全速度,以及这些参数之间的耦合关系。此外,我们在仿真环境中验证了我们的模型,结果表明预测的最大安全速度与测试速度相比误差小于20。在高密度情况下,定位误差对无人机的最大安全飞行速度有显着影响。 |
| Barrier Functions Inspired Reward Shaping for Reinforcement Learning Authors Nilaksh, Abhishek Ranjan, Shreenabh Agrawal, Aayush Jain, Pushpak Jagtap, Shishir Kolathaya 强化学习 RL 已从简单的控制任务发展到具有大型状态空间的复杂现实世界挑战。虽然强化学习在这些任务中表现出色,但训练时间仍然是一个限制。奖励塑造是一种流行的解决方案,但现有方法通常依赖于价值函数,这面临可扩展性问题。本文提出了一种新颖的以安全为导向的奖励塑造框架,其灵感来自屏障功能,在各种环境和任务中提供简单性和易于实施性。为了评估所提出的奖励公式的有效性,我们在 CartPole、Ant 和 Humanoid 环境中进行了模拟实验,并在 Unitree Go1 四足机器人上进行了实际部署。我们的结果表明,与普通奖励相比,我们的方法的收敛速度提高了 1.4 2.8 倍,驱动工作量低至 50 60。 |
| A Novel Dynamic Light-Section 3D Reconstruction Method for Wide-Range Sensing Authors Mengjuan Chen, Qing Li, Kohei Shimasaki, Shaopeng Hu, Qingyi Gu, Idaku Ishii 现有的基于振镜的激光扫描系统在多尺度3D重建中应用具有挑战性,因为难以在高重建精度和宽重建范围之间取得平衡。本文提出了一种通过使用多检流计切换相机视场 FOV 来同步激光扫描的新颖方法。除了先进的硬件设置之外,我们还通过对动态相机、动态激光及其组合交互进行建模,建立了系统的全面数学模型。然后,我们通过构建误差模型并最小化目标函数,提出了一种高精度且灵活的校准方法。最后,我们通过扫描标准组件来评估所提出系统的性能。评估结果表明,当测量范围扩展到1100 mm×1300 mm×650 mm时,所提出的3D重建系统的精度达到0.3 mm。 |
| A non-cubic space-filling modular robot Authors Tyler Hummer, Sam Kriegman 不同形状的空间填充构件渗透到自然界的各个组织层面,从原子到蜂窝,并已被证明在从分子容器到粘土砖的人造系统中有用。但是,尽管数学已知的空间填充多面体多种多样,但机器人技术中只探索了立方体。因此,在这里我们将一个非立方空间机器人化,填充形状为菱形十二面体。这种几何形状为立方体提供了一种有吸引力的替代方案,因为它极大地简化了一个细胞围绕另一个细胞边缘的旋转运动,并增加了每个细胞可以与之通信和保持的邻居数量。为了更好地了解这些和其他空间填充机器的挑战和机遇,我们制造了 48 个菱形十二面体单元,并用它们来建造各种上部结构。我们报告了我们建造的一些结构的机车能力,并讨论了我们测试的不同设计的缺点。我们还引入了一种无性别被动细胞对接策略,该策略可推广到任何具有径向对称面的多面体。 |
| Summary Paper: Use Case on Building Collaborative Safe Autonomous Systems-A Robotdog for Guiding Visually Impaired People Authors Aman Malhotra, Selma Saidi 这是一篇关于机器狗用例的摘要论文,专门用于在智能十字路口等复杂环境中引导视障人士。在这种情况下,机器狗必须自主决定穿过路口是否安全,以便进一步引导人类。我们利用 Robotdog 和在同一环境中运行的其他自主系统之间的数据共享和协作。 |
| Optimal Integrated Task and Path Planning and Its Application to Multi-Robot Pickup and Delivery Authors Aman Aryan, Manan Modi, Indranil Saha, Rupak Majumdar, Swarup Mohalik 我们提出了一种通用的多机器人规划机制,它将最优任务规划器和最优路径规划器结合起来,为复杂的多机器人规划问题提供可扩展的解决方案。集成规划器通过任务规划器和路径规划器的交互,为机器人生成最佳的无碰撞轨迹。我们说明了仓库场景中物体拾取和放置规划问题的通用算法,其中一组机器人被委托将物体从工作空间中的一个位置移动到另一个位置。我们通过将任务规划问题简化为 SMT 求解问题并采用高度先进的 SMT 求解器 Z3 来解决它。为了生成机器人的无碰撞运动,我们扩展了最先进的算法“基于冲突的搜索与优先约束”,并具有几个特定领域的约束。我们在物体拾取规划问题的各种实例上广泛评估我们的集成任务和路径规划器,并将其性能与最先进的多机器人经典规划器进行比较。 |
| Smooth Computation without Input Delay: Robust Tube-Based Model Predictive Control for Robot Manipulator Planning Authors Qie Sima, Yu Luo, Tianyin Ji, Fuchun Sun, Huaping Liu, Jianwei Zhang 模型预测控制 MPC 在优化目标和满足约束方面表现出了卓越的能力。然而,与在每个触发时刻求解最优控制问题 OCP 相关的大量计算负担在状态采样和控制应用之间引入了显着的延迟。当参与复杂任务时,这些延迟限制了 MPC 在资源受限系统中的实用性。本文解决这个问题的直觉是,通过预测后继状态,控制器可以提前一步解决 OCP,从而避免下一动作的延迟。为此,我们计算实际系统状态和名义系统状态之间的偏差,预测即将到来的实际状态作为即将出现的 OCP 解决方案的初始条件。预期计算存储基于当前标称状态的最优控制,从而减轻延迟效应。此外,我们建立了线性化误差的上限,有效地线性化非线性系统,降低OCP复杂度,并提高响应速度。 |
| RKHS-BA: A Semantic Correspondence-Free Multi-View Registration Framework with Global Tracking Authors Ray Zhang, Jingwei Song, Xiang Gao, Junzhe Wu, Tianyi Liu, Jinyuan Zhang, Ryan Eustice, Maani Ghaffari 这项工作报告了一种新颖的束调整 BA 公式,使用称为 RKHS BA 的再生内核希尔伯特空间 RKHS 表示。所提出的公式是无对应关系的,使 BA 能够直接在优化中使用 RGB D LiDAR 和语义标签,并为直接方法中常用的光度损失函数提供了泛化。 RKHS BA 可以将外观和语义标签合并到连续的空间语义功能表示中,不需要通过图像金字塔进行优化。 |
| Results and Lessons Learned from Autonomous Driving Transportation Services in Airfield, Crowded Indoor, and Urban Environments Authors Doosan Baek, Sanghyun Kim, Seung Woo Seo, Sang Hyun Lee 在过去的几十年里,自动驾驶汽车得到了积极的研究。最近的几项工作通过令人印象深刻的实验结果展示了自动驾驶交通服务在城市环境中的潜力。然而,这些研究指出,在复杂场景下,自动驾驶汽车的性能有时仍不如专业驾驶员。此外,他们并不关注自动驾驶交通服务在城市环境以外的其他领域的可能性。本文介绍了机场、拥挤的室内和城市环境中自动驾驶交通服务的研究成果和经验教训。我们讨论如何应对这些不同环境中的一些独特挑战。我们还概述了尚未引起太多关注但必须解决的剩余挑战。 |
| A Cost-Effective Cooperative Exploration and Inspection Strategy for Heterogeneous Aerial System Authors Xinhang Xu, Muqing Cao, Shenghai Yuan, Thien Hoang Nguyen, Thien Minh Nguyen, Lihua Xie 在本文中,我们提出了一种用于协作空中检查的异构无人机群系统的成本有效的策略。与之前的群体检测工作不同,该方法不依赖于精确的环境先验知识,可以完成对任何形状物体的全3D表面覆盖。在这项工作中,代理被分成小组,每架无人机分配不同的任务,包括测绘、探索和检查。通过遵循最佳优先规则为每个团队分配最佳检查量,可以促进任务分配。基于体素图的环境表示用于寻路,基于规则的路径规划方法是该方法的核心。我们使用所提出的方法在所有具有挑战性的实验中取得了最佳性能,在多个评估试验中超越了类似任务的所有基准方法。 |
| A Comparative Study of Rapidly-exploring Random Tree Algorithms Applied to Ship Trajectory Planning and Behavior Generation Authors Trym Tengesdal, Tom Arne Pedersen, Tor Arne Johansen 快速探索随机树 RRT 算法在非结构化环境中基于采样的非完整车辆规划中很受欢迎。然而,我们认为之前的工作并没有阐明采用此类算法时面临的挑战。因此,在本文中,我们对以下先前提出的 RRT 算法变体的性能进行了首次比较研究: Potential Quick RRT PQ RRT 、 Informed RRT IRRT 、 RRT 和 RRT,用于非结构化海事中几种情况下的单查询非完整运动规划环境。还讨论了在海事领域采用此类算法的实用性。 |
| Shaping Multi-Robot Patrol Performance with Heterogeneity in Individual Learning Behavior Authors Connor York, Zachary R Madin, Paul O Dowd, Edmund R Hunt 社会群体内学习行为的个体差异,无论是人类、其他动物还是机器人,都会对集体任务表现产生重大影响。这是因为它会影响个体对环境的反应以及他们之间的互动。近年来,人们越来越关注个体差异(无论是在学习方面还是在其他特征方面)如何影响所研究的集体结果(例如社会性昆虫觅食行为)的问题。多机器人、群体系统继承了这些例子的生物灵感,在这里我们考虑一种称为潜在抑制 LI 的学习行为的异质性对于负责环境监测和异常检测的巡逻机器人团队是否有用。 LI 较高的人可能会被认为更善于学会不去注意不相关或无回报的刺激,而 LI 较低的人可能会被认为容易分心,但更积极的是,他们更具探索性。我们引入了一个简单的 LI 影响模型,作为重新搜索奖励异常阅读位置的概率,而之前发现该位置是无奖励的、无关的。在模拟巡逻中,我们发现大多数高 LI 机器人和单个低 LI 机器人的负偏分布在监测动态环境方面总体上最有效。 |
| Grid-based Fast and Structural Visual Odometry Authors Zhang Zhihe 在同步定位和建图SLAM领域,研究人员一直追求在精度和时间成本方面更好的性能。传统算法通常依赖图像中的基本几何元素来建立帧之间的连接。然而,这些元素存在分布不均匀、提取速度慢等缺点。此外,线等几何元素在位姿估计过程中尚未得到充分利用。为了解决这些挑战,我们提出了 GFS VO,一种基于网格的 RGB D 视觉里程计算法,可以最大限度地利用点和线特征。我们的算法结合了快速线提取和稳定的线均质化方案来改进特征处理。为了充分利用场景中的隐藏元素,我们引入曼哈顿轴 MA 来提供本地地图和当前帧之间的约束。此外,我们设计了一种基于广度优先搜索的算法来提取平面法向量。为了评估 GFS VO 的性能,我们进行了广泛的实验。 |
| phloSAR: a Portable, High-Flow Pressure Supply and Regulator Enabling Untethered Operation of Large Pneumatic Soft Robots Authors Maxwell Ahlquist, Rianna Jitosho, Jiawen Bao, Allison M. Okamura 气动驱动通过促进顺应性、实现大体积变化以及将驱动器重量集中在远离末端执行器的位置,从而有利于软机器人技术。然而,当气动执行器与笨重的空气和电源相连时,便携性就会受到影响。虽然便携式气动系统有现有的选择,但它们的动态能力有限,限制了它们对低压和/或小体积软机器人的适用性。在这项工作中,我们提出了一种便携式、高流量压力供应和调节器 phloSAR,用于不受束缚、重量受限、动态软机器人应用。 PhloSAR 利用高流量比例阀、集成压力储存器和文丘里真空发生装置来实现便携性和动态性能。我们提出了一组描述系统动力学的模型,在物理硬件上对它们进行实验验证,并讨论设计参数对系统运行的影响。最后,我们将概念验证原型与安装在飞行器上的软机器人臂集成,以展示该系统对移动机器人的适用性。 |
| Automated Continuous Force-Torque Sensor Bias Estimation Authors Philippe Nadeau, Miguel Rogel Garcia, Emmett Wise, Jonathan Kelly 六轴力扭矩传感器通常安装在串行机器人的手腕上,用于测量作用在机器人末端执行器上的外力和扭矩。这些测量用于负载识别、接触检测和人机交互等应用。通常,从力扭矩传感器获得的测量结果比根据关节扭矩读数计算的估计值更准确,因为前者独立于机器人的动态和运动学模型。然而,力扭矩传感器测量结果会受到温度变化、机械应力和其他因素的复合效应造成的随时间漂移的偏差的影响。在这项工作中,我们提出了一个管道,可以连续估计连接到机器人手腕的力扭矩传感器的偏差和偏差漂移。管道的第一个组件是卡尔曼滤波器,用于估计机器人关节的运动状态位置、速度和加速度。第二个组件是运动学模型,它将关节空间运动学映射到力扭矩传感器的任务空间运动学。 |
| Autonomous Strike UAVs for Counterterrorism Missions: Challenges and Preliminary Solutions Authors Meshari Aljohani, Ravi Mukkamalai, Stephen Olariu 无人机正在成为现代战争中的重要工具,这主要是因为它们具有成本效益、降低风险以及执行更广泛活动的能力。使用自主无人机对高价值目标执行打击任务是这项研究的重点。由于账本技术、智能合约和机器学习的发展,以前由专业人员或远程无人机进行的此类活动现在变得可行。我们的研究首次对成功实施自主无人机任务的挑战和初步解决方案进行了深入分析。具体来说,我们确定必须克服的挑战,并针对所确定的挑战提出可能的技术解决方案。 |
| SELFI: Autonomous Self-Improvement with Reinforcement Learning for Social Navigation Authors Noriaki Hirose, Dhruv Shah, Kyle Stachowicz, Ajay Sridhar, Sergey Levine 通过经验进行交互和改进的自主自我改进机器人是机器人系统在现实世界中部署的关键。在本文中,我们提出了一种在线学习方法 SELFI,它利用在线机器人经验来快速有效地调整预训练的控制策略。 SELFI 在基于离线模型的学习之上应用在线无模型强化学习,以发挥两种学习范式的最佳部分。具体来说,SELFI 通过将离线预训练中基于相同模型的学习目标合并到通过在线无模型强化学习学习到的 Q 值中来稳定在线学习过程。我们在多个现实世界环境中评估 SELFI,并报告在避免碰撞方面的改进,以及通过人类用户研究衡量的更符合社会规范的行为。 SELFI 使我们能够以较少的人为干预快速学习有用的机器人行为,例如行人的先发制人行为、避免小型和透明物体的碰撞以及避免在不平坦的地板表面上行驶。 |
| Optimal Robot Formations: Balancing Range-Based Observability and User-Defined Configurations Authors Syed Shabbir Ahmed, Mohammed Ayman Shalaby, Jerome Le Ny, James Richard Forbes 本文介绍了一组可定制的新颖成本函数,使用户能够轻松指定所需的机器人编队,例如高覆盖范围的基础设施检查编队,同时保持较高的相对位姿估计精度。总体成本函数平衡了机器人靠近以实现基于良好测距的相对定位精度的需求和机器人完成特定任务的需求,例如最小化检查给定区域所需的时间。通过最小化聚合成本函数找到的地层在模拟和实验中的覆盖路径规划任务中进行评估,其中机器人使用基于扩展卡尔曼滤波器的同步定位和映射算法来定位自身和未知地标。 |
| Joint Spatial-Temporal Calibration for Camera and Global Pose Sensor Authors Junlin Song, Antoine Richard, Miguel Olivares Mendez 在机器人技术中,运动捕捉系统已被广泛用于测量定位算法的准确性。此外,该基础设施还可以用于其他计算机视觉任务,例如视觉惯性SLAM动态初始化的评估、多目标跟踪或自动注释。然而,为了最佳地工作,这些功能需要在相机和全局姿态传感器之间具有准确且可靠的时空校准参数。在本研究中,我们提供了两种新颖的解决方案来估计这些校准参数。首先,我们设计了一种具有高精度和一致性的基于离线目标的方法。时空参数、相机固有参数和轨迹同时优化。然后,我们提出了一种在线无目标方法,消除了对校准目标的需要,并能够估计随时间变化的时空参数。此外,我们对无目标方法进行了详细的可观测性分析。我们关于可观测性的理论发现通过模拟实验得到了验证,并为校准提供了可解释的指南。 |
| Nussbaum Function Based Approach for Tracking Control of Robot Manipulators Authors Hamed Rahimi Nohooji, Holger Voos 本文介绍了一种新颖的基于 Nussbaum 函数的机器人操纵器 PID 控制。将Nussbaum函数集成到PID框架中提供了一种结构简单的解决方案,有效解决了未知控制方向的挑战。稳定性是通过基于神经网络的估计和李亚普诺夫分析的结合来实现的,有助于自动增益调整,而不需要系统动力学。我们的方法提供了最小参数要求的增益确定,显着降低了机器人操纵器控制的复杂性并提高了效率。该论文保证闭环系统内的所有信号都保持有界。 |
| Suturing Tasks Automation Based on Skills Learned From Demonstrations: A Simulation Study Authors Haoying Zhou, Yiwei Jiang, Shang Gao, Shiyue Wang, Peter Kazanzides, Gregory S. Fischer 在这项工作中,我们开发了一个开源手术模拟环境,其中包括通过 MRI 扫描物理体模获得的真实模型,用于训练和评估用于自主缝合的演示 LfD 算法学习。 LfD 算法利用动态运动原语 DMP 和局部加权回归 LWR ,但重点关注针轨迹,而不是仪器,以获得针抓取方面更好的通用性。我们进行了一项用户研究,收集多个缝合演示,并对 LfD 算法从一个体模的一个位置的演示推广到同一体模的不同位置以及不同体模的能力进行全面分析。 |
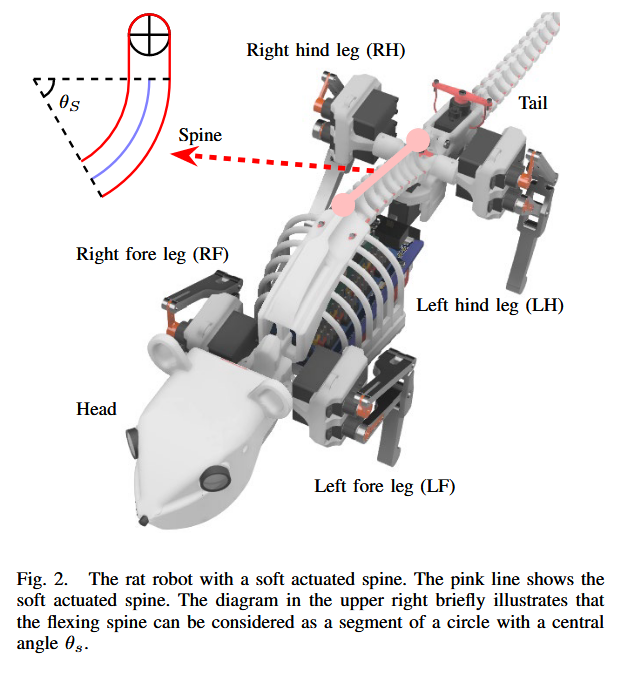
| Optimizing Dynamic Balance in a Rat Robot via the Lateral Flexion of a Soft Actuated Spine Authors Yuhong Huang, Zhenshan Bing, Zitao Zhang, Genghang Zhuang, Kai Huang, Alois Knoll 对于哺乳动物来说,利用脊柱保持平衡是通过肌肉力量以最有效的方式调整身体姿势的生理学方式。因此,我们可以看到许多残疾的四足动物即使有三肢,仍然可以站立或行走。本文基于受脊柱屈曲影响的质心 CoM 和支撑区域之间的空间关系,研究了小跑步态中动态平衡的优化。小跑期间,机器人平衡受到 CoM 到对角立足点形成的支撑区域的距离的显着影响。在这种情况下,脊柱侧屈能够改变立足点的位置,有望在小跑时优化平衡。本文使用配备软驱动脊柱的大鼠机器人探讨了这一现象。基于脊柱的侧屈,我们建立了运动学模型来量化小跑步态中脊柱弯曲对机器人平衡的影响。随后,我们开发了一种用于脊柱弯曲的优化控制器,旨在在不改变腿部运动的情况下增强平衡。我们提出的控制器的有效性是通过在老鼠机器人上进行的广泛模拟和物理实验来评估的。 |
| PRIME: Scaffolding Manipulation Tasks with Behavior Primitives for Data-Efficient Imitation Learning Authors Tian Gao, Soroush Nasiriany, Huihan Liu, Quantao Yang, Yuke Zhu 模仿学习在使机器人获得复杂的操纵行为方面表现出了巨大的潜力。然而,这些算法在长期任务中面临着高样本复杂性的问题,其中复合误差在任务范围内累积。我们提出了基于 PRIME PRimitive 的具有数据效率的 IMitation,这是一种基于行为原语的框架,旨在提高模仿学习的数据效率。 PRIME 通过将任务演示分解为原始序列来搭建机器人任务,然后通过模仿学习学习高级控制策略来对原始序列进行排序。 |
| An Architecture for Unattended Containerized (Deep) Reinforcement Learning with Webots Authors Tobias Haubold, Petra Linke 随着数据科学应用程序在各行业中得到采用,工具环境日趋成熟,可以促进此类应用程序的生命周期,并为所涉及的挑战提供解决方案,从而提高相关人员的生产力。 |
| Scalable Vision-Based 3D Object Detection and Monocular Depth Estimation for Autonomous Driving Authors Yuxuan Liu 本论文对基于视觉的 3D 感知技术的进步做出了多方面的贡献。在第一部分中,本文介绍了单目和立体 3D 对象检测算法的结构增强。通过将地面参考几何先验集成到单目检测模型中,这项研究在单目 3D 检测的基准评估中实现了无与伦比的准确性。同时,这项工作通过结合从单目网络收集的见解和推理结构来完善立体 3D 检测范例,从而提高立体检测系统的运行效率。第二部分致力于数据驱动策略及其在 3D 视觉检测中的实际应用。引入了一种新颖的训练方案,该方案合并了用 2D 或 3D 标签注释的数据集。这种方法不仅通过利用大幅扩展的数据集来增强检测模型,而且还有助于在仅容易获得 2D 注释的现实场景中经济地部署模型。最后,论文提出了一种专为自动驾驶环境中无监督深度估计而定制的创新流程。广泛的实证分析证实了这一新提出的管道的稳健性和有效性。 |
| RISeg: Robot Interactive Object Segmentation via Body Frame-Invariant Features Authors Howard H. Qian, Yangxiao Lu, Kejia Ren, Gaotian Wang, Ninad Khargonkar, Yu Xiang, Kaiyu Hang 为了在新环境中成功执行抓取等操作任务,机器人必须熟练地从背景和/或其他物体中分割出看不见的物体。之前的工作通过在大规模数据上训练深度神经网络来学习 RGB RGB D 特征嵌入来执行看不见的对象实例分割 UOIS,其中杂乱的环境通常会导致分割不准确。我们在这些方法的基础上引入了一种新颖的方法,通过使用机器人交互和设计的身体框架不变特征来纠正基于静态图像的 UOIS 掩模的不准确分割,例如分割不足。我们证明,由于机器人交互而随机附着到刚体的框架的相对线性和旋转速度可用于识别对象并累积校正的对象级别分割掩模。通过将运动引入分割不确定性区域,我们能够以不确定性驱动的方式大幅提高分割精度,并且具有最少的、非破坏性的交互。每个场景 2 3 。 |
| OccFusion: A Straightforward and Effective Multi-Sensor Fusion Framework for 3D Occupancy Prediction Authors Zhenxing Ming, Julie Stephany Berrio, Mao Shan, Stewart Worrall 本文介绍了 OccFusion,这是一种简单高效的传感器融合框架,用于预测 3D 占用情况。对 3D 场景的全面理解对于自动驾驶至关重要,最近的 3D 语义占用预测模型已经成功解决了描述具有不同形状和类别的现实世界对象的挑战。然而,现有的 3D 占用预测方法严重依赖环视摄像机图像,这使得它们容易受到照明和天气条件变化的影响。通过集成激光雷达和环视雷达等其他传感器的功能,我们的框架提高了占用预测的准确性和鲁棒性,从而在 nuScenes 基准测试中实现顶级性能。此外,在 nuScenes 数据集上进行的大量实验(包括具有挑战性的夜间和雨天场景)证实了我们的传感器融合策略在各种感知范围内的卓越性能。 |
| Kick Back & Relax++: Scaling Beyond Ground-Truth Depth with SlowTV & CribsTV Authors Jaime Spencer, Chris Russell, Simon Hadfield, Richard Bowden 自监督学习是解锁通用计算机视觉系统的关键。通过消除对真实注释的依赖,它允许扩展到更大的数据量。不幸的是,自监督单目深度估计 SS MDE 因缺乏多样化的训练数据而受到限制。 |
| Composite Distributed Learning and Synchronization of Nonlinear Multi-Agent Systems with Complete Uncertain Dynamics Authors Emadodin Jandaghi, Dalton L. Stein, Adam Hoburg, Mingxi Zhou, Chengzhi Yuan 本文解决了在领导者跟随者框架内的异构非线性不确定性下运行的多智能体机器人操纵器系统网络中的复合同步和学习控制的挑战性问题。引入了一种新颖的双层分布式自适应学习控制策略,包括第一层分布式协作估计器和第二层分散确定性学习控制器。第一层的主要目标是促进每个机器人代理对领导者信息的估计。第二层负责使各个机器人代理能够跟踪所需的参考轨迹并准确识别和学习其非线性不确定动力学。所提出的分布式学习控制方案代表了现有文献的进步,因为它能够管理具有完全不确定的动力学(包括不确定的质量矩阵)的机器人代理。该框架允许机器人控制独立于环境,可用于各种设置,从水下到太空,在这些环境中识别系统动态参数具有挑战性。使用Lyapunov方法严格分析闭环系统的稳定性和参数收敛性。对多智能体机器人操纵器进行的数值模拟验证了该方案的有效性。 |
| Chinese Abs From Machine Translation |