链表(Linked List)是一种常见的数据结构,它由一系列节点组成,每个节点包含数据部分和指向下一个节点的指针。链表算法在软件开发程序中有着广泛的应用场景。
链表算法基础知识:
链表算法基础知识主要包括链表的基本概念、结构、操作以及应用场景。以下是一些链表算法的基础知识要点:
1. 链表的基本概念
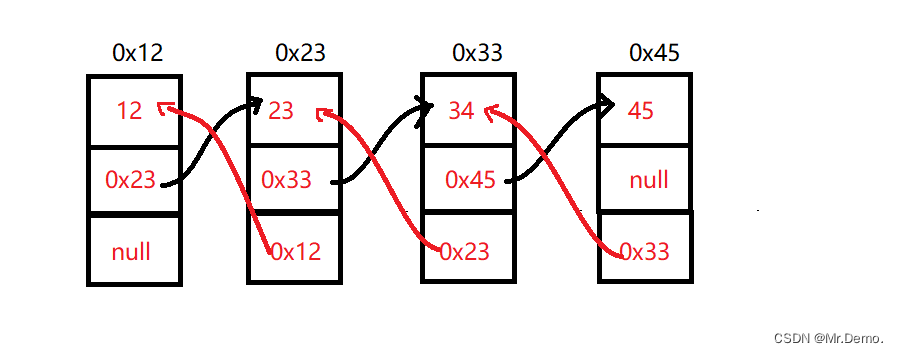
- 链表:链表是一种线性数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
- 节点:链表的每个元素称为节点,每个节点至少包含两部分:数据部分和指向下一个节点的指针。
- 头节点:链表的第一个节点,通常用于标识链表的开始。
- 尾节点:链表的最后一个节点,其指针通常指向
null或None,表示链表的结束。
2. 链表的类型
- 单链表:每个节点只有一个指针,指向下一个节点。
- 双链表:每个节点有两个指针,一个指向前一个节点,另一个指向下一个节点。
- 循环链表:尾节点的指针指向头节点,形成一个闭环。
3. 链表的操作
- 插入:在链表的指定位置插入一个新节点。
- 删除:从链表中删除指定位置的节点。
- 查找:遍历链表以查找特定值的节点。
- 遍历:按顺序访问链表中的每个节点。
4. 链表的实现
链表通常使用结构体或类来实现。例如,在C语言中,可以使用结构体来定义链表节点,包含数据部分和指针部分。在面向对象编程语言中,可以使用类来定义链表节点,并包含相应的属性和方法。
5. 链表的应用场景
- 动态数据结构:需要频繁插入和删除元素的数据结构。
- 内存管理:实现自定义的内存管理器,动态分配和释放内存块。
- 事件处理:按照事件发生的顺序或优先级处理事件。
- 深度优先搜索:在图形遍历算法中,使用链表来表示节点的邻接关系。
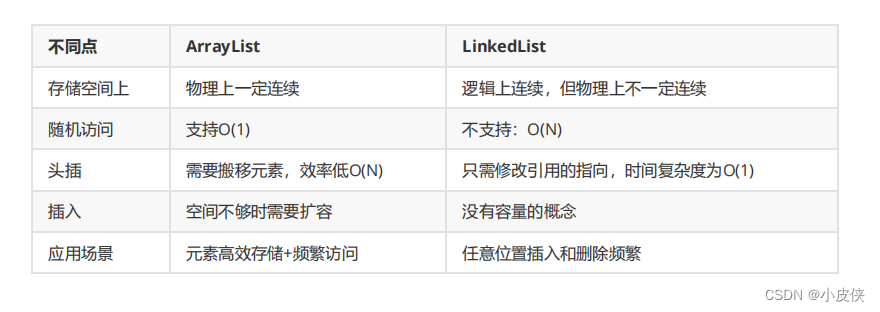
6. 链表的性能特点
- 插入和删除:链表在插入和删除节点时具有较高的效率,时间复杂度通常为O(1)。
- 访问元素:链表在访问特定位置的元素时效率较低,需要遍历链表,时间复杂度为O(n)。
7. 链表的优缺点
- 优点:动态扩展、灵活插入和删除、适应性强。
- 缺点:内存使用较多、访问效率较低、不连续存储、实现复杂性较高。
下面我将介绍一些链表算法的使用场景和使用例子。
使用场景:
动态数据集合:链表非常适合用于需要动态添加或删除元素的数据集合。由于链表不需要在内存中连续存储,因此可以方便地在任意位置插入或删除节点。
数据缓存:在缓存系统中,链表可以用于存储最近访问或最近使用的数据项。当缓存满时,可以轻松地移除最不常用的数据项。
深度优先搜索(DFS):在图形遍历算法中,链表常用于实现深度优先搜索。每个节点可以包含指向其子节点的指针,从而实现递归遍历。
内存管理:链表可以用于实现自定义的内存管理器,例如管理动态分配的内存块。
事件处理:在事件驱动的系统中,链表可用于存储待处理的事件,按照事件发生的顺序或优先级进行处理。
使用例子详解:
以单链表为例,我们可以实现一个简单的链表结构,并展示其添加、删除和遍历的操作。
定义链表节点
python复制代码
class ListNode: |
|
def __init__(self, value=0, next=None): |
|
self.value = value |
|
self.next = next |
添加元素到链表末尾
python复制代码
def append_to_list(head, value): |
|
if not head: |
|
return ListNode(value) |
|
current = head |
|
while current.next: |
|
current = current.next |
|
current.next = ListNode(value) |
|
return head |
从链表中删除元素
python复制代码
def delete_from_list(head, value): |
|
if not head: |
|
return None |
|
if head.value == value: |
|
return head.next |
|
current = head |
|
while current.next and current.next.value != value: |
|
current = current.next |
|
if current.next: |
|
current.next = current.next.next |
|
return head |
遍历链表
python复制代码
def traverse_list(head): |
|
current = head |
|
while current: |
|
print(current.value, end=' ') |
|
current = current.next |
|
print() |
使用示例
python复制代码
# 创建链表 |
|
head = None |
|
# 添加元素 |
|
head = append_to_list(head, 1) |
|
head = append_to_list(head, 2) |
|
head = append_to_list(head, 3) |
|
# 遍历链表 |
|
print("链表内容:") |
|
traverse_list(head) |
|
# 删除元素 |
|
head = delete_from_list(head, 2) |
|
# 再次遍历链表 |
|
print("删除元素后的链表内容:") |
|
traverse_list(head) |
输出将会是:
复制代码
链表内容: |
|
1 2 3 |
|
删除元素后的链表内容: |
|
1 3 |
在这个例子中,我们创建了一个简单的单链表,并演示了如何向链表中添加元素、如何从链表中删除元素以及如何遍历链表。这些基本操作展示了链表在软件开发中的一些常见用法。
链表算法的优缺点:
链表算法具有以下优点和缺点:
优点:
动态数据结构:链表是一种动态数据结构,这意味着它可以根据需要动态地扩展或收缩。无需预先分配固定大小的内存空间,从而能够更有效地利用内存。
灵活的插入和删除:在链表中,插入和删除节点非常灵活和高效。只需更改相关节点的指针,而无需移动其他元素。这使得链表非常适合实现需要频繁插入和删除操作的数据结构。
适应性强:链表可以适应各种数据类型,包括基本数据类型和复杂数据类型。此外,链表还支持插入和删除不同数据类型的节点。
支持随机访问:虽然链表不支持像数组那样的直接索引访问,但可以通过遍历链表来访问任何位置的节点。在某些情况下,这可能是一个优势,因为链表可以在访问元素时执行其他操作(如检查有效性)。
缺点:
内存使用:链表中的每个节点都包含数据和指向下一个节点的指针,因此链表通常比相同大小的数组占用更多的内存。此外,由于链表是动态分配的,因此可能存在内存碎片问题。
访问效率:链表不支持随机访问,这意味着访问链表中的特定元素需要遍历链表,直到找到所需的节点。这导致链表在访问元素时的效率较低,特别是在大型链表中。
不连续存储:链表中的元素在内存中不是连续存储的,这可能导致缓存不友好。在连续访问链表中的元素时,可能会导致频繁的缓存未命中,从而降低性能。
实现复杂性:相对于数组等简单数据结构,链表需要更多的指针操作和内存管理。这可能导致代码更复杂且容易出错。
总结:链表算法具有动态扩展、灵活插入和删除等优点,但同时也存在内存使用、访问效率、不连续存储和实现复杂性等缺点。在选择使用链表算法时,需要根据具体的应用场景和需求进行权衡。当然,链表还有很多其他复杂的应用,比如双向链表、循环链表、链表排序等,它们在更复杂的数据结构和算法中有着广泛的应用。