介绍
Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模式,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集
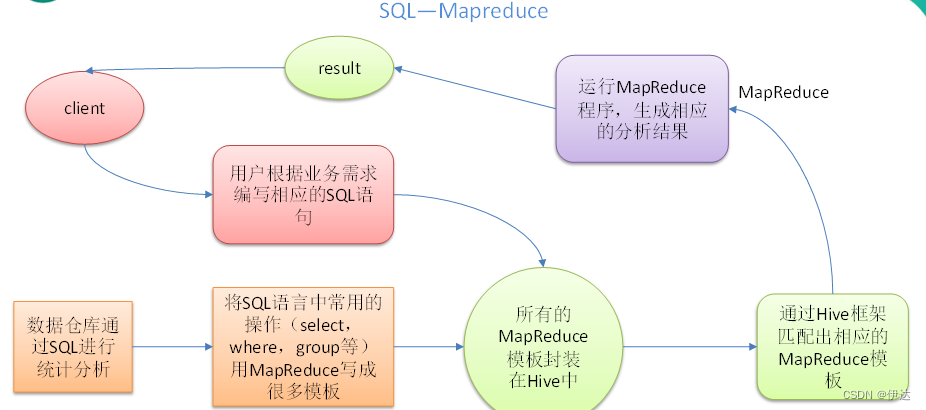
Hive核心是将 HQL转换成MapReduce程序,然后将程序提交到Hadoop集群执行。
Hive由Facebook实现并开源
Hive和Hadoop关系
从功能上来说,数仓至少具备 存储数据 和 分析数据 的能力
Apache Hive 作为一款大数据时代的数仓软件,具备以上能力。只是Hive并不是自己实现,而是借助Hadoop。
Hive利用HDFS存储数据,利用MapReduce查询分析数据。
Hive的最大优点在于让用户专注于编写HQL,Hive帮你转换成MapReduce程序完成对数据的分析
被称为 Sql On Hadoop
Hive的理解
1 Hive能将数据文件映射成一张表,这个映射指什么?
答:文件和表之间的对应关系
在Hive中能够写sql处理的前提是针对表,而不是针对文件,因此需要将文件和表之间的对应关系描述记录清楚。
映射信息 专业的叫法称之为 元数据信息(元数据是指用来描述数据的数据metadata)
具体看,要记录的元数据信息包括:表对应哪个文件(位置信息),表的列对应文件的哪个字段(顺序信息),文件字段的分隔符是什么
2 Hive的本身到底承担了什么功能职责?
答:SQL语法解析编译成为MapReduce
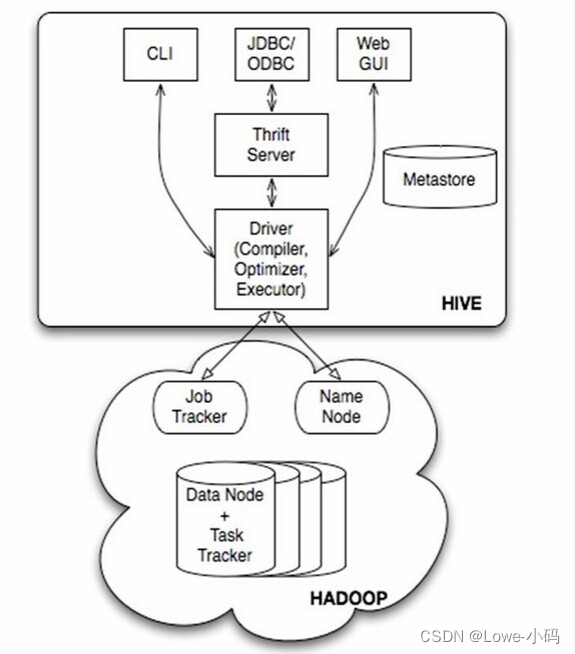
结构
1 客户端 ;
2 Hive对sl的语法解析,编译,执行计划变化;
3 Hadoop (MapReduce,Yarn,HDFS)
4 元数据存储
架构,组件
1 用户接口:
CLI(command line interface,为shell命令行访问)
JDBC/ODBC
WebGUI(浏览器访问)
2 元数据存储
通常是存储在关系数据库,如mysql/derby中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等
3 Hive 的 Driver 驱动程序
功能:语法解析器,计划编译器,优化器,执行器
完成HQL查询语句从词法分析,语法分析,编译,优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有执行引擎调用执行。
元数据(Metadata)
元数据(metadata),又称中介数据,中继数据,为描述数据的数据。主要是描述数据属性的信息,用来支持如指示存储位置,历史数据,资源查找,文件记录等功能
Hive Metadata 即 Hive 的元数据,元数据存储在关系型数据库中,如hive内置的Derby,或者第三方如Mysql等
元数据服务(Metastore)
Metastore 即 元数据服务,作用是管理metadata元数据,对外保留服务地址,让各种客户端通过脸颊metastore服务,由metastore再去连接Mysql数据库来存取元数据
服务配置由3种模式: 内嵌模式,本地模式,远程模式。
| 内嵌模式 | 本地模式 | 远程模式(企业一般这个) | |
| Metastore单独配置、启动 | 否 | 否 | 是 |
| Metastore存储介质 | derby | mysql | mysql |
远程模式:
在生产环境中,建议用远程模式来配置HIve Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性,安全性
hive提供的连接:
老版本:bin/hive 连接Metastore
.../hive-3.1.2/bin/hive新版本 : bin/beeline 连接Metastore, beeline连接又新启动的HiveServer2连接访问元数据服务
hiveserver2服务启动前必须先启动datastore服务。
.../hive-3.1.2/bin/beeline
启动后需要手动输入地址
! connect jdbc:hive2://node1:10000
root
密码Hive可视化客户端: DataGrip,Dbeaver,SQuirrel SQL Client等
安装部署
前置: 安装好Hadoop,Mysql
参考文档:HIve安装配置(超详细)-CSDN博客
Hive SQL语法
字段类型:1 原生数据类型(primitive data type),2 复杂数据类型(complex data type)
常用的数据类型是 字符串String 和 数字类型 Int
DDL
------------- 数据库 ---------------------------
创建新的数据库
create <database>
COMMENT 数据库的注视说明语句
LOCATION 知道数据库在HDFS存储位置,默认配置文件中的路径(最好不要指定)
切换数据库
use <database>
删除数据库,谨慎,库下没表才能删除
drop (DATABASE|SCHEMA)(IF EXISTS) <database> [RESTRICT|CASCADE]
CASCADE 可以删除带有表的数据库
------------- 对表 ------------------------------
新建表
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name(col_name data_type [COMMENT col_comment],...)[COMMENT table_comment][ROW FORMAT DELIMITED...]
ROW FORMAT DELIMITED
[FIELDS TERMINATED BY char] 字段之间分隔符
[COLLECTION ITEMS TERMINATED By char] 集合元素之间分隔符
[MAP KEYS TERMINATED BY char] Map映射kv之间分隔符
[LINES TERMINATED By char] 行数据之间分隔符
eg:
CREATE TABLE IF NOT EXISTS mydb.myUserTable(
id string comment 'id'
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
默认分隔符 \001
显示库
show databases;
显示表
show tables [in database];
显示元数据信息
desc formatted myUserTable;
注释信息的中文乱码—— 元数据存储在mysql数据库,默认编码,主要支持Latin编码
Mysql数据库执行:
alter table hive3.COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table hive3.TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive3.PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive3.PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table hive3.INDEX_PARAMS modify column PARAM__VALUE varchar(4000) character set utf8;
-- 原来的表的注释无法修改,只能新建表才会生效
删除表
drop table mydb.myUserTable;
DML
导入数据:1 load 2 insert
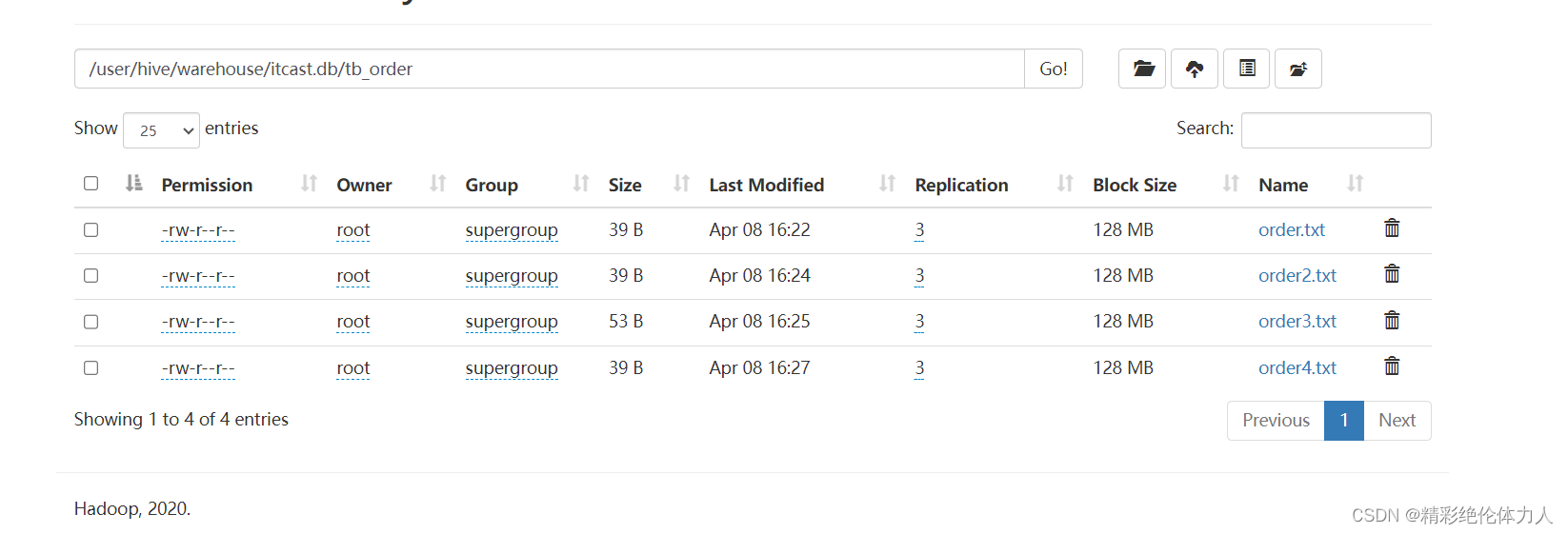
新建的数据库,在hdfs下面格式:${hive.metastore.warehouse.dir}/database.db/tablename/结构化文件.txt
暴力,直接放上去:
hadoop fs -put xx.txt ${hive.metastore.warehouse.dir}/database.db/tablename/
hive推荐load
LOAD DATA [LOCAL] INPUT 'filepath' [OVERWRITE] INTO TABLE tablename;
-LOCAL 加上,后面跟的文件需要和hive的metastore一个服务器,不加则需要在hdfs的文件系统路径里;文件移动是复制操作
-OVERWRITE 加上是覆盖,不加是追加;文件是移动操作,原来的会没有
INSERT 可用,但速度很慢
INSERT INTO TABLE tablename VALUES (1,2,3);
INSERT INTO TABLE tablename(id,name) VALUES (1,'zl');
INSERT INTO TABLE tablename SELECT id,name FROM tablename2; (推荐)查询
DISTINCT 去重
GROUP BY 分组 ,搭配 HAVING
LIMIT [offset,] rows 分页
WHERE
- 判空 age IS NULL
- 区间 between 1500 and 3000 = >1500 and < 3000
- 数据 in (1,2,3)
ORDER BY [ASC|DESC] 排序
聚合: COUNT(*)返回被选行数,COUNT(column)返回某列不为NULL的行数,SUM,MAX,MIN,AVG等,不管多少行,聚合后只返回一条数据
count(distinct column):列存在重复数据,去重后统计
AS 起别名