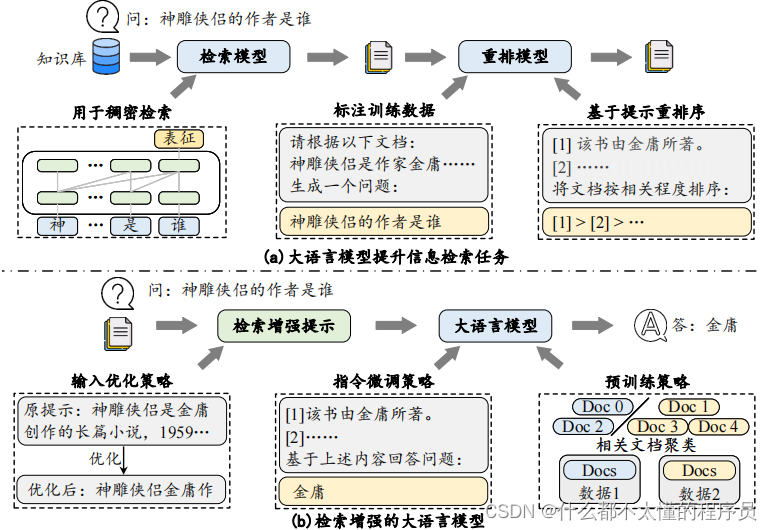
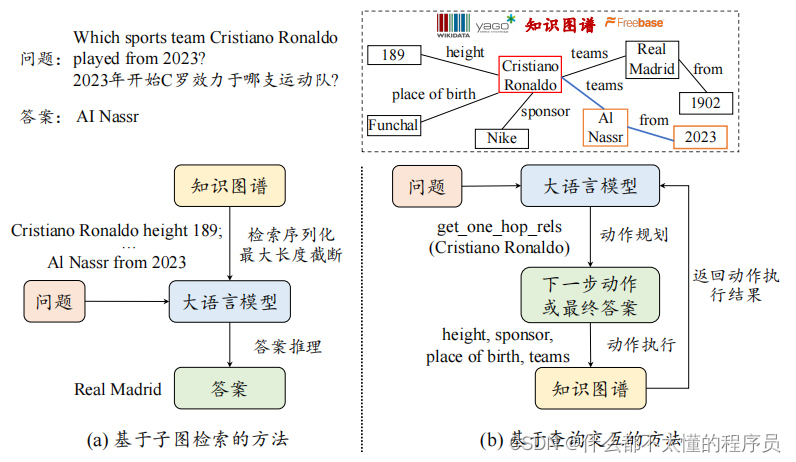
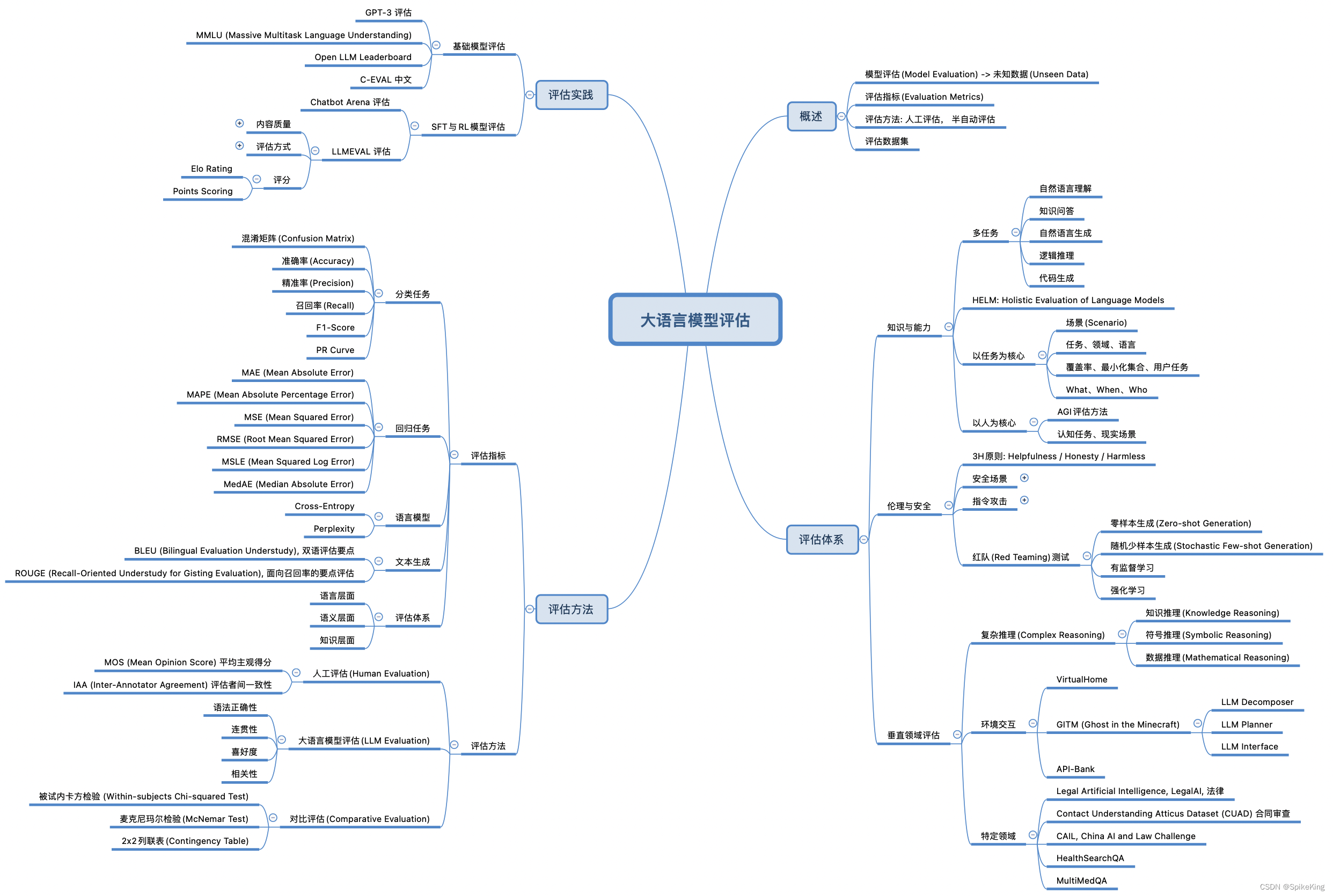
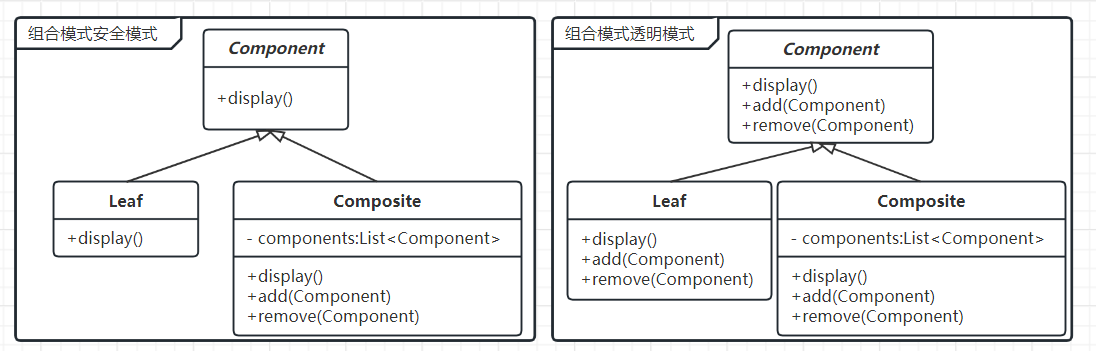
大语言模型中的"大"通常体现在以下几个方面,参数数量,训练数据和计算资源:
参数数量:
- 大语言模型的一个显著特征是其庞大的参数数量。参数的数量决定了模型的复杂度和表示能力。更多的参数通常意味着模型可以捕捉更复杂的模式和关系。
- 大语言模型的可能采用更深、更宽的网络结构,包括更多的层、更多的隐藏单元和更复杂的连接方式。这种结构有助于提高模型的表征能力和泛化能力。
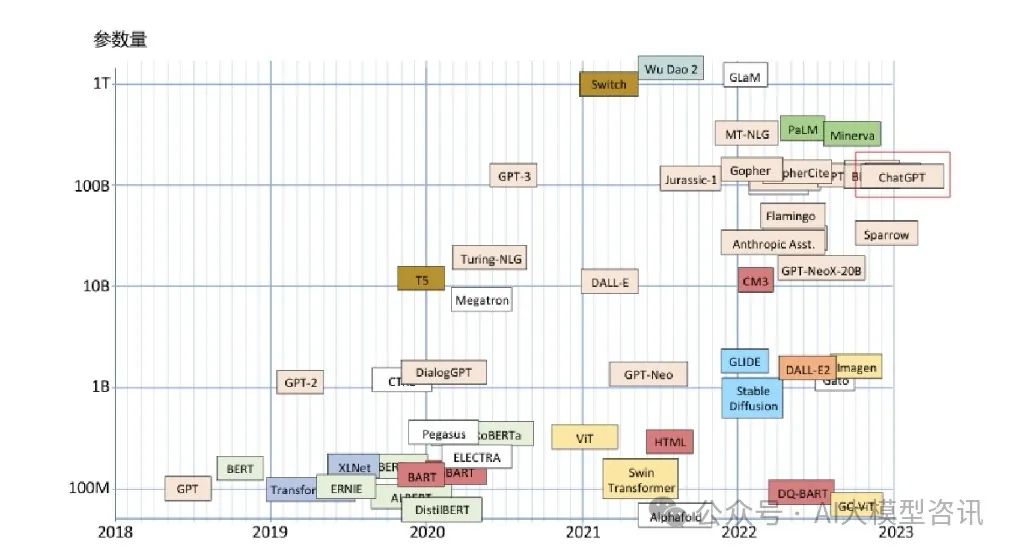
上图为大规模语言模型的参数量随着时间的变化图,2022年左右大规模语言模型大量出现,参数量在100B(1千亿)左右。
训练数据:
大语言模型通常是通过大规模的文本数据进行训练的,这些数据包含了丰富的语言信息,有助于模型学习更准确的语言表示。
从下面的图可以看到,Meta 开源的llama所需要的训练数据有2T(2万亿)token,阿里开源的通义千问模型的训练数据达到了3T(3万亿)。这个训练数据是什么量级呢,我们可以来类比一下,2022年底的时候,维基上有640万篇文章,这些文章的token量大概是40亿。

计算资源:
- 大语言模型通常需要大量的计算资源来训练和推理。这包括高性能的GPU或TPU,以及大规模的分布式计算环境,如多GPU服务器或云计算资源。
- 大语言模型在推理时需要处理大量的参数和复杂的计算,因此推理速度成为一个挑战。优化的模型架构、模型压缩技术和专门的硬件加速可以提高推理速度。

上图中我们可以看到一台8卡的A100(80G)的服务器大概可以提供的计算量为5PFlop/s-day,假设GPT4有万亿参数量,其大概需要的计算量为75352 PFlop/s-day,如果需要15天训练完成的话,估计需要万卡的GPU集群。
所以,大语言模型的规模不仅体现在参数数量上,还包括训练数据、计算资源上,这些“大”使得大规模语言模型的泛化能力和应用领域等都得到极大增强。大语言模型在增强泛化能力的情况下,还会带来给应用领域带来变革。
大语言模型的规模通常与其泛化能力相关联。更大的模型容易过拟合训练数据,但在合适的正则化和训练技巧下,它们可以学习到更广泛、更准确的语言规律。
大语言模型的规模也会影响其在不同应用领域的效果。在自然语言处理任务中,大模型可能在机器翻译、文本生成、语言理解等方面表现更出色。
PS:欢迎扫码关注公众号^_^.