层次聚类算法
层级聚类算法分类
- 自底向上的凝聚层次聚类:这种方法开始时将每个样本都视为一个单独的簇,然后不断合并最近的簇,直到满足某种停止条件(如簇的数量达到预设值、簇之间的距离超过某个阈值等)。常见的凝聚层次聚类算法有AGNES(AGglomerative NESting)算法等。
- 自顶向下的分裂层次聚类:这种方法开始时将所有样本视为一个簇,然后不断分裂簇,直到满足某种停止条件(如簇的数量达到预设值、簇内部的紧密程度低于某个阈值等)。分裂层次聚类算法在实际应用中相对较少。
自底向上的凝聚层次聚类
- 自底向上的凝聚层次聚类算法主要有以下几种:
AGNES(AGglomerative NESting)算法
- AGNES是一种典型的自底向上的凝聚层次聚类算法。它开始时将每个样本都视为一个单独的簇,然后计算各簇之间的距离,并将最近的两个簇合并为一个新的簇。这个过程会不断迭代,直到满足某种停止条件(如簇的数量达到预设值、簇之间的距离超过某个阈值等)。AGNES算法的关键在于如何计算簇之间的距离,常见的距离度量方法包括最小距离、最大距离和平均距离等。
# 伪代码实现AGNES算法
def agnes_clustering(data, max_clusters=None, distance_threshold=None):
# 初始化:每个数据点是一个簇
clusters = [{
data_point} for data_point in data]
# 计算初始簇之间的距离矩阵
distance_matrix = compute_distance_matrix(clusters)
# 迭代直到满足停止条件
while True:
# 找出距离矩阵中的最小距离及其对应的簇对
min_dist, (cluster_i, cluster_j) = find_closest_clusters(distance_matrix)
# 如果达到最大簇数量或距离阈值,则停止迭代
if (max_clusters is not None and len(clusters) <= max_clusters) or min_dist >= distance_threshold:
break
# 合并簇
merged_cluster = cluster_i.union(cluster_j)
# 更新簇集合,移除被合并的簇,添加新簇
clusters.remove(cluster_i)
clusters.remove(cluster_j)
clusters.append(merged_cluster)
# 更新距离矩阵,计算新簇与其他簇之间的距离
distance_matrix = update_distance_matrix(clusters, distance_matrix, merged_cluster)
# 返回聚类结果
return clusters
# 辅助函数:计算簇之间的距离矩阵
def compute_distance_matrix(clusters):
# 实现计算簇间距离的逻辑,返回距离矩阵
pass
# 辅助函数:找出距离最近的簇对
def find_closest_clusters(distance_matrix):
# 实现找出最小距离及其对应的簇对的逻辑
pass
# 辅助函数:更新距离矩阵,考虑新合并的簇
def update_distance_matrix(clusters, old_distance_matrix, merged_cluster):
# 实现更新距离矩阵的逻辑,考虑新合并的簇
pass
# 使用示例
data = [...] # 输入数据集
clusters = agnes_clustering(data, max_clusters=5, distance_threshold=1.5)
# clusters现在包含层次聚类的结果
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)算法
- 这是一种基于CF Tree(Clustering Feature Tree)的层次聚类算法。它通过使用CF Tree来存储和压缩数据,从而降低了内存消耗和计算复杂度。BIRCH算法能够处理大规模数据集,并且对于噪声和异常值具有一定的鲁棒性。
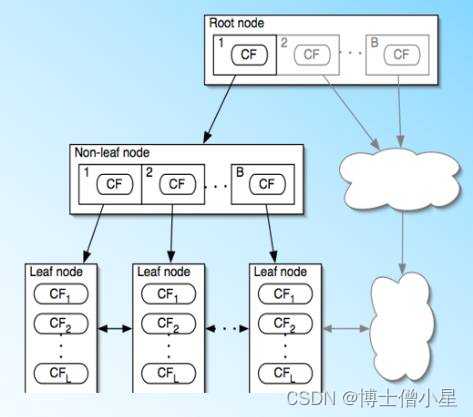
- CF Tree(Clustering Feature Tree)是一种用于层次聚类的数据结构,特别适用于处理大规模数据集。它类似于平衡B+树,每个节点都由聚类特征(CF)组成。
- CF Tree的每个节点包含三个聚类特征,它们构成一个三元组,用(N, LS, SS)来表示。其中,N表示该节点包含的样本数量,LS表示该节点包含的样本点的向量和,SS表示该节点包含的样本点各个特征的平方和。
- 在CF Tree中,父节点的某个CF值等于其指向的所有子节点CF值的总和。CF Tree的构建过程是从空树开始,逐个读入样本并生成CF三元组,然后按照特定的规则将它们插入到树中。
class CFNode:
def __init__(self, threshold, entry_count):
self.threshold = threshold # 阈值,用于决定是否分裂节点
self.entry_count = entry_count # 当前节点包含的样本数量
self.LS = [0] * num_features # 样本点向量和
self.SS = [0] * num_features # 样本点各特征的平方和
self.children = [] # 子节点列表
def insert(self, sample):
# 插入一个样本到当前节点
for i in range(num_features):
self.LS[i] += sample[i]
self.SS[i] += sample[i] ** 2
self.entry_count += 1
# 如果超过阈值,则分裂节点
if self.entry_count > self.threshold:
self.split()
def split(self):
# 分裂节点
new_node = CFNode(self.threshold, 0)
for i in range(num_features):
# 将样本点向量和和平方和平均分配到两个子节点
new_node.LS[i] = self.LS[i] / 2
self.LS[i] -= new_node.LS[i]
new_node.SS[i] = self.SS[i] / 2
self.SS[i] -= new_node.SS[i]
self.entry_count = self.entry_count // 2
new_node.entry_count = self.entry_count
self.children.append(new_node)
# 递归地对子节点进行插入操作
for sample in self.samples:
new_node.insert(sample)
def merge(self, other_node):
# 合并两个节点
for i in range(num_features):
self.LS[i] += other_node.LS[i]
self.SS[i] += other_node.SS[i]
self.entry_count += other_node.entry_count
# 如果合并后超过阈值,则可能需要递归地合并子节点
if self.entry_count > self.threshold:
self.split()
def birch_clustering(data, threshold):
# 初始化根节点
root = CFNode(threshold, 0)
# 遍历数据集,将样本插入到CF Tree中
for sample in data:
root.insert(sample)
# 执行聚类操作
clusters = []
for node in CFTree_traversal(root):
# 将节点转换为聚类
cluster = Cluster(node.LS, node.SS, node.entry_count)
clusters.append(cluster)
return clusters
def CFTree_traversal(node):
# CF Tree的遍历函数
yield node
for child in node.children:
yield from CFTree_traversal(child)
# 使用示例
data = [...] # 输入数据集
threshold = ... # 设置阈值
clusters = birch_clustering(data, threshold)
# clusters现在包含层次聚类的结果
- CF Tree的主要优点是它能够有效地压缩数据并减少计算复杂度,从而在处理大规模数据集时提高聚类的效率。此外,由于它采用了树形结构,因此还具有天然的可扩展性和灵活性,可以方便地添加、删除或修改节点。这使得CF Tree成为一种非常适合于处理超大规模数据集的层次聚类算法。
CURE(Clustering Using Representatives)算法
CURE算法通过选择每个簇的代表点来进行聚类。它认为一个簇中的代表点应该能够反映该簇的整体形状和大小,而不仅仅是其中心或质心。因此,CURE算法在合并簇时,会考虑代表点之间的距离和数量,以得到更加合理的聚类结果。
import numpy as np
class CURE:
def __init__(self, data, num_clusters, shrinkage_factor=0.5):
self.data = data # 输入数据集
self.num_clusters = num_clusters # 期望的聚类数目
self.shrinkage_factor = shrinkage_factor # 收缩因子,用于确定代表点的数量
self.representatives = [] # 代表点的集合
self.clusters = [] # 聚类结果的集合
def fit(self):
# 初始化:选择每个聚类的第一个代表点
self.representatives = self.data[:self.num_clusters]
# 迭代过程,直到代表点不再显著变化
while True:
# 计算每个点到最近代表点的距离
distances = self._calculate_distances(self.representatives)
# 更新代表点:选择每个聚类的中心点和最远的点作为新的代表点
new_representatives = []
for i in range(self.num_clusters):
# 找到第i个聚类的中心点
centroid = np.mean(self.data[distances[:, i] < np.inf], axis=0)
# 找到第i个聚类的最远点
farthest_point = self.data[np.argmax(distances[:, i])]
# 计算收缩后的点
shrunken_centroid = self._shrink(centroid, self.shrinkage_factor)
# 添加新的代表点到列表中
new_representatives.append(shrunken_centroid)
new_representatives.append(farthest_point)
# 检查代表点是否发生变化
if np.all(np.array(self.representatives) == np.array(new_representatives)):
break
self.representatives = new_representatives
# 使用最终的代表点生成聚类
self.clusters = self._form_clusters(self.representatives)
def _calculate_distances(self, representatives):
# 计算每个点到所有代表点的距离
distances = np.full((len(self.data), len(representatives)), np.inf)
for i, rep in enumerate(representatives):
distances[:, i] = np.linalg.norm(self.data - rep, axis=1)
return distances
def _shrink(self, point, factor):
# 根据收缩因子收缩点
return point * factor
def _form_clusters(self, representatives):
# 使用代表点形成聚类
clusters = []
for rep in representatives:
# 将每个点到最近代表点的距离小于无穷大的点分配到该聚类
cluster = self.data[np.min(np.linalg.norm(self.data - rep, axis=1), axis=1) < np.inf]
clusters.append(cluster)
return clusters
# 使用示例
data = np.random.rand(100, 2) # 假设有100个二维数据点
cure = CURE(data, num_clusters=5)
cure.fit()
# 输出聚类结果
for i, cluster in enumerate(cure.clusters):
print(f"Cluster {
i+1}: {
cluster}")
CHAMELEON(Highly Adaptive MEthod for Learning Cluster Hierarchies from Data)算法
- 这是一种基于动态模型的层次聚类算法。它通过使用一个动态模型来描述数据的分布和演化,从而能够发现不同尺度和密度的簇。CHAMELEON算法在处理复杂形状和密度的簇时表现出较好的性能。
import numpy as np
from scipy.spatial.distance import pdist, squareform
class CHAMELEON:
def __init__(self, data, k=5, m=2, t=2):
self.data = data # 输入数据集
self.k = k # k-最近邻参数
self.m = m # 用于计算相似性的最小点数
self.t = t # 阈值参数
self.graph = None # 相似性图
self.clusters = [] # 聚类结果
def fit(self):
# 步骤1: 计算相似性图
self.graph = self._compute_similarity_graph(self.data)
# 步骤2: 初始化聚类
self.clusters = [self.data]
# 步骤3: 迭代聚类
while len(self.clusters) > 1:
new_clusters = []
for cluster in self.clusters:
# 步骤3.1: 计算子聚类
subclusters = self._compute_subclusters(cluster)
# 步骤3.2: 合并相似的子聚类
merged_clusters = self._merge_similar_clusters(subclusters)
new_clusters.extend(merged_clusters)
self.clusters = new_clusters
def _compute_similarity_graph(self, data):
# 计算数据点之间的距离
dist_matrix = squareform(pdist(data))
# 使用k-最近邻方法构建相似性图
graph = np.zeros((len(data), len(data)))
for i in range(len(data)):
for j in range(i+1, len(data)):
if dist_matrix[i, j] in np.sort(dist_matrix[i, :])[:self.k]:
graph[i, j] = graph[j, i] = 1
return graph
def _compute_subclusters(self, cluster):
# 提取cluster中的数据点
data_points = cluster
# 计算点之间的相似性
similarity_matrix = np.dot(data_points, data_points.T)
# 初始化子聚类
subclusters = []
for i in range(len(data_points)):
subcluster = [data_points[i]]
for j in range(i+1, len(data_points)):
if similarity_matrix[i, j] > self.t:
subcluster.append(data_points[j])
subclusters.append(subcluster)
return subclusters
def _merge_similar_clusters(self, subclusters):
# 合并相似的子聚类
merged_clusters = []
while subclusters:
clusters_to_merge = []
for sc in subclusters:
if not clusters_to_merge:
clusters_to_merge.append(sc)
else:
merged = False
for c in clusters_to_merge:
if self._is_similar(sc, c, self.m):
merged = True
break
if not merged:
clusters_to_merge.append(sc)
# 合并选中的子聚类
merged_cluster = np.vstack(clusters_to_merge)
merged_clusters.append(merged_cluster)
# 更新待合并的子聚类列表
subclusters = [sc for sc in subclusters if sc not in clusters_to_merge]
return merged_clusters
def _is_similar(self, cluster1, cluster2, m):
# 判断两个子聚类是否相似
# 这里使用简单的点集交集大小作为相似性的度量
intersection = len(set(cluster1).intersection(set(cluster2)))
return intersection >= min(len(cluster1), len(cluster2)) - m
# 使用示例
data = np.random.rand(100, 2) # 假设有100个二维数据点
chameleon = CHAMELEON(
- 这些自底向上的凝聚层次聚类算法各有特点,适用于不同的数据集和聚类需求。在实际应用中,需要根据具体情况选择合适的算法,并进行参数调整和性能评估。