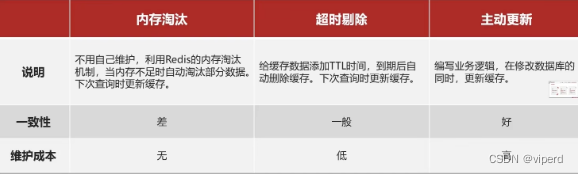
原则:redis希望存储的是热点数据,尽量可以在一天内访问到。
最佳实践
选择合适的数据结构
redis有String、Hash、Set、SortedSet、List等结构,主要依据业务需要进行选择
string:几乎所有数据都可以用string存储,但是最好适用于value较小、结构简单的数据,但是对于特殊结构如list/set这种,某种情况下可以节省存储空间和提高存取效率。(特点,可以有默认的过期时间)
list:有序列表,可以在头尾进行插入,插入效率高O(1),如果往中间插效率就很低。使用场景如博客系统可以为每篇文章设置一个list,使用lrange进行分页。
set:无序集合,可实现去重,使用场景如记录访问ip,可以实现天然去重。
SortedSet(ZSet):跳表,增删数据的复杂度都是O(logn),每个成员都有对应的分数用于排序,访问内部成员会很高效,使用场景如大型游戏积分榜,可以用zincrby增加用户分数,用zrange来获取top10,用zrange和zrank来获取用户的排名信息和附近的排名用户。
Hash:同hashmap,需要注意的是其编码有几种类型,压缩编码占据空间小但获取效率低容易导致pending,所以可以在设置时指定编码,对于对象,如果只更新部分字段就显得更加灵活而不需要像字符串一样维护整个json。
HyperLogLog:用于基数统计,如网站UV.在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。可以参考这篇文章:
https://www.cnblogs.com/exceptioneye/p/7081896.html
杜绝大Value及热点key
String类型超过1Mb,集合的元素超过1w,就需要考虑拆分。
热点key容易导致cpu及网络高负载,需要业务上有相应的降级。
由于redis为单线程,针对大key的耗时一高就容易导致整个集群出现问题,
1.拆分大value的方法:
i:需要整存整取
将对象拆成几个key value,使用multiGet获取值来分拆单次操作的压力,将压力分摊到多个redis实例中,这种比较常见。
ii:需要部分存取
还是对其拆分为几个key value,或者使用hash进行存储分拆,每个filed去代表属性。
2.集合中元素过多(超过1w)
同样是需要进行拆分来分散单次操作的压力,比如固定桶数量,设置n个hash桶,先进行取余确定分到哪个hash桶,再去真正的hash桶内执行hash操作(相当于为key拆分编号)
对于list的pop操作如果需要按照时间,就可以在设置key的时候按照时间进行命名分拆。
![<span style='color:red;'>Redis</span> <span style='color:red;'>最佳</span><span style='color:red;'>实践</span> [后端必看]](https://img-blog.csdnimg.cn/ea2601b3918f4aef836b5fe30da2ebf7.gif#pic_center)