批归一化
内部协变量偏移(Internal covariate shift)
当使用SGD时,不同迭代次数时输入到神经网络的数据不同,可能导致某些层输出的分布在不同迭代次数时不同。
ICS:训练中,深度神经网络中间节点分布的变化。可能增加优化难度。
通过归一化来减少ICS
对每个标量形式的特征单独进行归一化,使其均值为0,方差为1。
对于d维激活 x = ( x 1 , … , x d ) x=(x_1,…,x_d) x=(x1,…,xd),作如下归一化
x ^ i = x i − E [ x i ] Var [ x i ] \hat x_i=\frac{x_i-E[x_i]}{\sqrt{\text{Var}[x_i]}} x^i=Var[xi]xi−E[xi]
保持该层的表达能力
y i = γ i x ^ i + β i y_i=\gamma_i\hat x_i+\beta_i yi=γix^i+βi
若 γ i = Var [ x i ] \gamma_i=\sqrt{\text{Var}[x_i]} γi=Var[xi] 且 β i = E [ x i ] \beta_i=E[x_i] βi=E[xi] ,恢复到原来的激活值。批归一化BN(Batch Normalization)
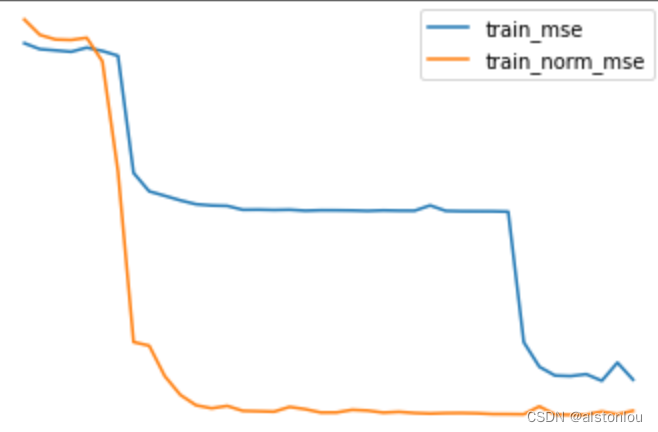
批归一化(Batch Normalization,BatchNorm)是一种用于优化深度神经网络的方法,它可以通过对每一层的输入数据进行标准化处理,使其均值为0,方差为1,从而减少每一层输入数据分布的变化,加快网络的收敛速度,提高网络的泛化能力和鲁棒性。
基本思想:
在每一层的输入数据上进行如下的变换:
x ~ i = x i − μ B σ B 2 + ϵ (归一化) y i = γ x ~ i + β (尺度变换和偏移) \tilde{x}_i=\frac{x_i-\mu_B}{\sqrt{\sigma_B^2+\epsilon}} \quad \text{(归一化)}\\ y_i=\gamma\tilde{x}_i+\beta \quad \text{(尺度变换和偏移)} x~i=σB2+ϵxi−μB(归一化)yi=γx~i+β(尺度变换和偏移)
其中, x i x_i xi 是第 i i i 个神经元的输入, μ B \mu_B μB 和 σ B 2 \sigma_B^2 σB2 是该层输入数据的均值和方差, ϵ \epsilon ϵ 是一个小常数,用于防止除零错误, x ~ i \tilde{x}_i x~i 是归一化后的输入, γ \gamma γ 和 β \beta β 是可学习的参数,用于调整数据的尺度和偏移, y i y_i yi 是最终的输出。优点
- 可以选择较大的初始学习率,加快网络的收敛。
- 可以减少正则化参数的选择问题,如 Dropout、L2 正则项等。
- 可以把训练数据彻底打乱,防止每批训练的时候,某一个样本经常被挑选到。
- 可以缓解梯度消失或梯度爆炸的问题,使得网络可以使用更深的结构和更多的非线性激活函数。
缺点
- 增加了网络的计算量和内存消耗。
- 对于小批量的数据,可能会导致不稳定的结果。
- 对于某些任务,可能会降低网络的表达能力或性能。
其他归一化技巧
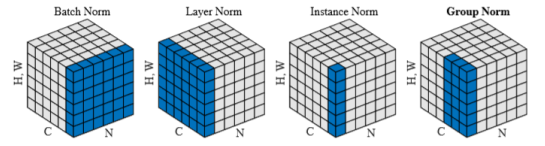
- 批归一化(Batch norm)用于CNN
- 层归一化(Layer norm)用于RNN
- 实例归一化(Instance norm)用于图像风格化
- 群归一化(Group norm)用于CNN处理批较小的情况