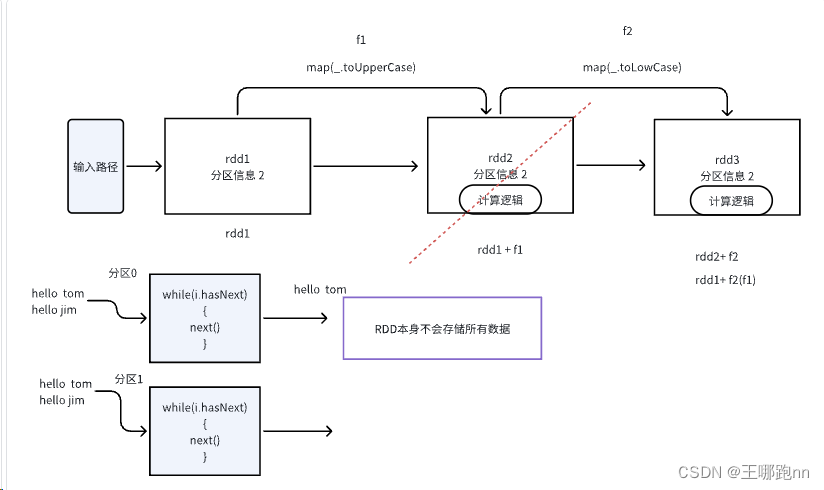
1.flume中拦截器的作用:个人认为就是修改或者删除事件中的信息(处理一下事件)。
2.一些拦截器
Host Interceptor,Timestamp Interceptor,Static Interceptor,UUID Interceptor,Search and Replace Interceptor,自定义拦截器
3.Channel选择器
Replicating Channel Selector,Multiplexing Channel Selector等。
功效:根据一些设置,使得传过来的事件选择走哪个channel。并且可以配合拦截器来呈现出许多不同的功效。
通过自定义的规则,来去决定事件Event发送到哪个channel。
4.Sink处理器
Sink用来消费存储在channel中的事件Event。
可以将多个sink放入到一个组中,sink处理器能够对一个组中所有的sink进行负载均衡,在一个sink出现临时错误时进行故障转移。
5.一些sink处理器
Default Sink Processor:
默认的Sink处理器只支持单个Sink。
Failover Sink Processor:
故障转移处理器维护了一个带有优先级的sink列表,故障转移机制将失败的sink放入到一个冷却池中,如果sink成功了发送事件,将其放入到活跃池中,sink可以设置优先级,优先级越高,如果一个sink发送事件失败,下一个有更高优先级的sink将被用来发送事件,比如:优先级100的比优先级80的先被使用,如果没有设置优先级,按照配置文件中配置的顺序来决定。
一个组中有sink处理器时,进行负载均衡选择sink处理器的方式是可选的,例如:轮询,随机,自定义等。
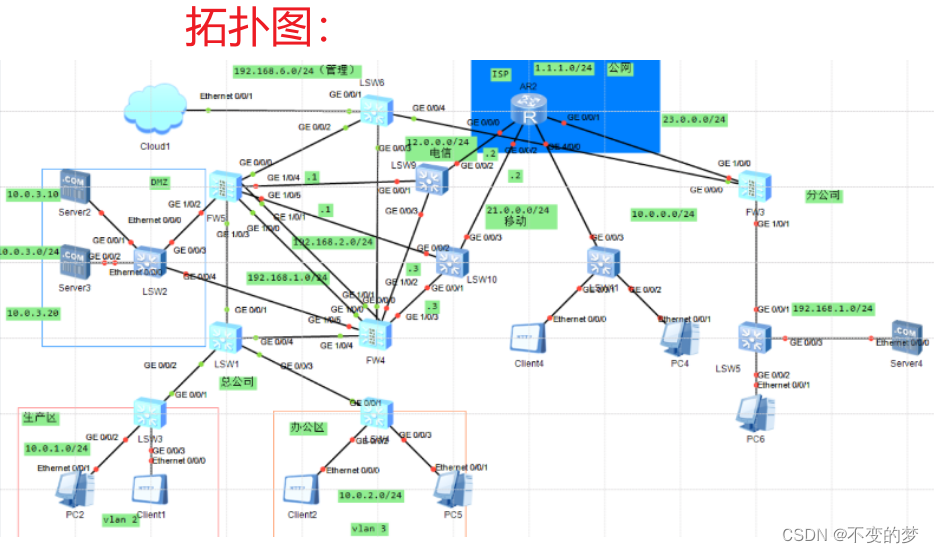
6.使用Flume导入数据到HDFS
数据导出到HDFS需要使用HDFS Sink,conf配置文件中进行相应的配置即可。
7.Flume监控
Ganglia工具。Ganglia用于测量和监控数以千计的节点(其实不外乎就是用Ganglia工具来监控Flume节点),Ganglia核心包括gmond(监控守护进程)、gmetad(元数据守护进程)以及一个web前端。主要是用来监控节点的性能,例如:cpu,memory,硬盘利用率,I/O负载,网络流量情况等,可以通过曲线见到每个节点的工作状态,对合理调整,分配系统资源,提高系统整体性能起到重要作用。
8.Flume总结
Flume是一个分布式,高可用,高可靠的海量日志采集,聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时提供了对数据进行简单处理并写到各种数据接收方的能力。
分布式:指通过部署多个agent来实现分布式。
高可用:通过sink的负载均衡或者副本机制来保证高可用。
高可靠:通过Channel的事务来保证高可靠。
各类数据发送方:通过可以指定很多类型的Source来实现支持各种类型的数据发送方。
eg:

对数据进行简单处理:通过拦截器,制定规则,来对数据进行修改,丢弃等操作。
写到各种数据接收方:通过支持各种类型的Sink来实现支持写到各种数据接收方的能力。
eg:

Flume的使用:
Flume的使用也非常简单,我们只需要在配置文件中配置好Flume的三大组件(Source,Channel,Sink)的相应配置,就可以使用了。
Flume的监控:使用Ganglia工具来监控Flume节点。
---------------------------------------------------------------------------------------------------------------------------------
DataX
9.DataX概述:
DataX是阿里巴巴开源的一个异构数据源(就是不同数据的来源,例如mysql,mongodb,hdfs等)的离线同步工具,致力于实现包括关系型数据库(mysql,oracle等),hdfs,hive,odps,hbase,ftp等各种异构数据源之间稳定高效的数据同步功能。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能将已有的数据源做到无缝数据同步。
如图所示:

为了解决异构数据源的同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
sqoop是将mysql数据库的数据导入到hdfs中(以及反方向的导出),使用场景相对“单一”。
10.DataX的结构:
以Mysql为例:
Reader:数据采集模块,负责数据源数据的采集,将数据发给FrameWork
Writer:数据写入模块,负责不断从Frameworks中拿数据,并将数据写入到目的端。
Framework:用于连接Reader和Writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
11.在配置文件中配置好reader的读取信息,以Json格式的形式,DataX自己就知道怎么去做了
eg:

12.在配置文件中配置好writer的读取信息,以Json格式的形式,DataX自己就知道怎么去做了
eg:


























![[工具探索]VSCode介绍和进阶使用](https://img-blog.csdnimg.cn/direct/9296daa2883b4152850b8caa7e289ced.jpeg#pic_center)