个人主页:Lei宝啊
愿所有美好如期而遇
概念:
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),正则匹配是一个模糊的匹配(不是精确匹配)
如下四个方法经常使用:
- match()
- search()
- findall()
- finditer()
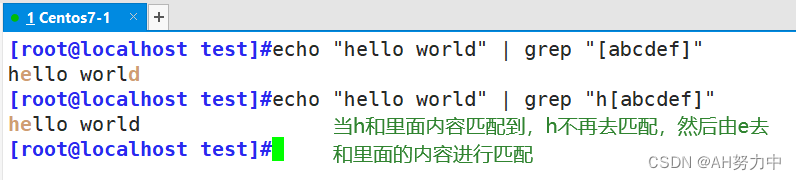
匹配单个字符或数字:
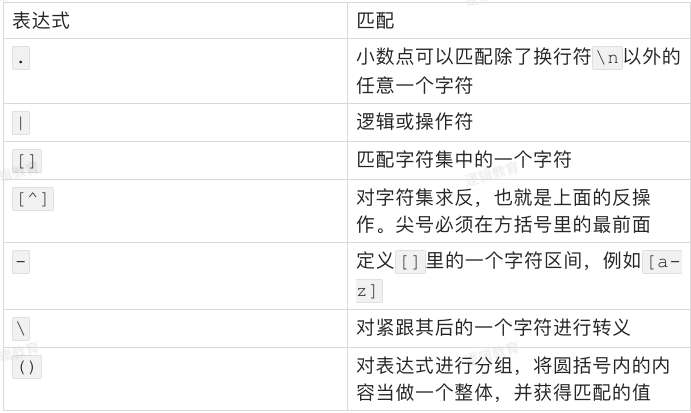
| 匹配 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符,当flags被设置为re.S时,可以匹配包含换行符以内的所有字符 |
| [] | 里面是字符集合,匹配[]里任意一个字符 |
| [0123456789] | 匹配任意一个数字字符 |
| [0-9] | 匹配任意一个数字字符 |
| [a-z] | 匹配任意一个小写英文字母字符 |
| [A-Z] | 匹配任意一个大写英文字母字符 |
| [A-Za-z] | 匹配任意一个英文字母字符 |
| [A-Za-z0-9] | 匹配任意一个数字或英文字母字符 |
| [^lucky] | []里的^称为脱字符,表示非,匹配不在[]内的任意一个字符 |
| ^[lucky] | 以[]中内的某一个字符作为开头 |
| \d | 匹配任意一个数字字符,相当于[0-9] |
| \D | 匹配任意一个非数字字符,相当于[^0-9] |
| \w | 匹配字母、下划线、数字中的任意一个字符,相当于[0-9A-Za-z_] |
| \W | 匹配非字母、下划线、数字中的任意一个字符,相当于[^0-9A-Za-z_] |
| \s | 匹配空白符(空格、换页、换行、回车、制表),相当于[ \f\n\r\t] |
| \S | 匹配非空白符(空格、换页、换行、回车、制表),相当于[^ \f\n\r\t] |
匹配锚字符
锚字符:用来判定是否按照规定开始或者结尾
| 匹配 | 说明 |
|---|---|
| ^ | 行首匹配,和[]里的^不是一个意思 |
| $ | 行尾匹配 |
| \A | 匹配字符串的开始,和^的区别是\A只匹配整个字符串的开头,即使在re.M模式下也不会匹配其他行的行首 |
| \Z | 匹配字符串的结尾,和$的区别是\Z只匹配整个字符串的结尾,即使在re.M模式下也不会匹配其他行的行尾 |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。
有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
| 匹配 | 说明 |
|---|---|
| (xyz) | 匹配括号内的xyz,作为一个整体去匹配 一个单元 子存储 |
| x? | 匹配0个或者1个x,非贪婪匹配 |
| x* | 匹配0个或任意多个x |
| x+ | 匹配至少一个x |
| x{n} | 确定匹配n个x,n是非负数 |
| x{n,} | 至少匹配n个x |
| x{n,m} | 匹配至少n个最多m个x |
| x|y | |表示或的意思,匹配x或y |
re模块中常用函数
通用flags(修正符)
| 值 | 说明 |
|---|---|
| re.I | 是匹配对大小写不敏感 |
| re.M | 多行匹配,影响到^和$ |
| re.S | 使.匹配包括换行符在内的所有字符 |
通用函数
获取匹配结果
使用group()方法 获取到匹配的值
groups() 返回一个包含所有小组字符串的元组(也就是自存储的值),从 1 到 所含的小组号。
match()函数
原型
def match(pattern, string, flags=0)功能
匹配成功返回 匹配的对象
匹配失败 返回 None
获取匹配结果
使用group()方法 获取到匹配的值
groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
注意:从第一位开始匹配 只匹配一次
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式
举例说明:
import re
str1 = '124jfda\n'
str2 = '\n124jfda'
print(re.match(".",str1))
print(re.match(".",str2))
print(re.match(".",str2,re.S))
search()函数
原型
def search(pattern, string, flags=0)功能
扫描整个字符串string,并返回第一个pattern模式成功的匹配
匹配失败 返回 None
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式 注意:
只要字符串包含就可以
只匹配一次
示例
str1 = '124jfda\n' str2 = '\n124jfda' print(re.search(".",str1)) print(re.search(".",str2)) print(re.search(".",str2,re.S))
注意
与search的区别
相同点:
都只匹配一次
不同点:
- search是在要匹配的字符串中 包含正则表达式的内容就可以
- match 必须第一位就开始匹配 否则匹配失败
findall()函数(返回列表)
原型
def findall(pattern, string, flags=0)功能
扫描整个字符串string,并返回所有匹配的pattern模式结果的字符串列表
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式
举例:
import re
str = '13678324489'
print(re.findall("[14]",str))
print(re.findall("1[0-9]",str))
print(re.findall("1[0-9]{10}$",str))
print(re.findall("1[0-9]{9}$",str))
贪婪与非贪婪模式
贪婪: .*
非贪婪: .*?
str = "<b>加粗</b><b>加粗的</b><b>加粗的的</b>"
val1 = re.search('<b>.*</b>',str) #贪婪
val2 = re.search('<b>.*?</b>',str) #非贪婪
print(val1.group())
print(val2.group())
myStr = """
<a href="http://www.baidu.com">百度</a>
<A href="http://www.taobao.com">淘宝</A>
<a href="http://www.id97.com">电
影网站</a>
<i>我是倾斜1</i>
<i>我是倾斜2</i>
<em>我是倾斜2</em>
"""
#提取网址和名字
lt = re.findall('<a href="(.*?)">(.*?)</a>',myStr,re.S|re.I)
print(lt)
finditer()函数
原型
def finditer(pattern, string, flags=0)功能
与findall()类似,返回一个迭代器
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) string 要匹配的字符串 flags 标识位,用于控制正则表达式的匹配方式
举例:
import re
ret = re.finditer('\d', '12456789')
print(ret)
print(next(ret))
for i in ret:
print(i)
split()函数(返回值为列表)
作用:切割字符串
原型:
def split(patter, string, maxsplit=0, flags=0)参数
pattern 正则表达式
string 要拆分的字符串
maxsplit 最大拆分次数 默认拆分全部
flags 修正符
示例:
import re
myStr = "asdas\rd&a\ts12d\n*a3sd@a_1sd"
#通过特殊字符 对其进行拆分 成列表
#非字母拆分
res = re.split("[^a-z]",myStr)
print(res)
res = re.split("\W",myStr)
print(res)

正则高级
分组&起名称
概念
处理简单的判断是否匹配之外,正则表达式还有提取子串的功能,用()表示的就是要提取的分组
说明
- 正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来
- group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串
示例:
import re
s = '3G4HFD567'
#格式:?P<别名> ()里内容表示要提取的分组
x = re.match("(?P<value>\d+)",s)
print(x.group(0))
print(x.group('value'))
编译
概念
当在python中使用正则表达式时,re模块会做两件事,一件是编译正则表达式,如果表达式的字符串本身不合法,会报错。另一件是用编译好的正则表达式提取匹配字符串
编译优点
如果一个正则表达式要使用几千遍,每一次都会编译,出于效率的考虑进行正则表达式的编译,就不需要每次都编译了,节省了编译的时间,从而提升效率
compile()函数
原型
def compile(pattern, flags=0)作用
将pattern模式编译成正则对象
参数
参数 说明 pattern 匹配的正则表达式(一种字符串的模式) flags 标识位,用于控制正则表达式的匹配方式 flags
值 说明 re.I 是匹配对大小写不敏感 re.M 多行匹配,影响到^和$ re.S 使.匹配包括换行符在内的所有字符 返回值
编译好的正则对象
示例:
import re
str = '123456'
pattern = re.compile("\d")
print(pattern.search(str))