Transformer模型是一种深度学习架构,它在2017年由Vaswani等人在论文《Attention is All You Need》中首次提出。这种架构特别适用于处理序列数据,如文本、音频或时间序列数据,因此在自然语言处理(NLP)、语音识别和时序分析等领域有着广泛的应用。Transformer模型的核心创新之一是自注意力机制(Self-Attention Mechanism),这使得模型能够在处理序列数据时,无需依赖于传统的递归神经网络(RNN)或卷积神经网络(CNN)结构。
1. Transformer架构
Transformer模型的基本结构包括两大部分:编码器(Encoder)和解码器(Decoder)。
- 编码器:编码器由若干个相同的层堆叠而成,每一层都包含两个子层。第一个子层是多头自注意力机制(Multi-Head Self-Attention Mechanism),使模型能够同时关注输入序列中的多个位置。第二个子层是简单的、位置全连接的前馈网络。每个子层周围都有一个残差连接(Residual Connection),紧接着是层归一化(Layer Normalization)。这种设计使得模型可以通过增加层的数量来增加其复杂性,而不会陷入训练困难。
- 解码器:解码器同样由若干个相同的层堆叠而成,每一层也包含三个子层。前两个子层分别是多头自注意力机制和编码器-解码器注意力机制(Encoder-Decoder Attention Mechanism),后者使解码器能够关注编码器的输出。第三个子层是前馈网络。解码器的每个子层也都使用了残差连接和层归一化。
自注意力机制
自注意力机制是Transformer模型的核心,它允许模型在处理每个序列元素时考虑到序列中的其他元素,这种机制可以通过三个主要步骤实现:查询(Query)、键(Key)和值(Value)操作。自注意力机制通过计算每个元素对序列中所有元素的注意力分数,然后根据这些分数来加权值向量,以此来聚合全局信息。
多头自注意力
多头自注意力机制是对自注意力机制的扩展,它将注意力操作分割成多个“头”,每个头在不同的表示子空间中学习序列的不同方面。这种机制可以提高模型的表达能力,因为它允许模型在不同的表示空间中捕获到序列的多样性信息。
2. Transformer底层
1. 自注意力机制
自注意力机制的核心是根据输入序列计算注意力得分,然后用这些得分来加权输入序列的值。它通过三个向量来实现:查询(Query)、键(Key)、值(Value),这三个向量是通过对输入向量应用线性变换得到的。
- 计算过程:对于序列中的每一个元素,自注意力机制计算其与序列中所有元素(包括自身)的注意力得分,这些得分指示了在生成输出时每个元素的重要性。注意力得分通过查询向量与键向量的点积来计算,然后通过softmax函数进行归一化,最后使用这些归一化的得分对值向量进行加权求和。
- 实现细节:在实现时,查询、键、值向量通常通过对输入序列X应用不同的线性变换(权重矩阵WQ、WK、WV)获得。然后,通过计算查询矩阵和键矩阵的点积,除以根号下的键向量维度(为了缩放点积的大小),应用softmax函数获得注意力权重,最后这些权重用于加权值矩阵,得到输出序列。
2. 多头自注意力
多头自注意力是对自注意力机制的扩展,它将注意力分成多个“头”,每个头在不同的子空间中捕捉输入序列的信息。
- 实现细节:实现多头自注意力时,首先将查询、键、值矩阵分别分割成多个小矩阵,每个小矩阵对应一个注意力“头”。对每个头独立进行自注意力计算,然后将所有头的输出拼接起来,最后通过一个线性变换得到最终输出。这样,模型可以在不同的表示子空间中捕捉序列的不同特征。
3. 位置编码
由于Transformer模型本身不具备捕捉序列中元素位置信息的能力,因此需要通过位置编码来补充这种信息。位置编码向量被添加到输入序列的嵌入向量中,以使模型能够利用序列中元素的位置信息。
- 实现细节:位置编码通常使用正弦和余弦函数的固定公式来生成,对于给定位置的每个维度,使用不同频率的正弦和余弦波形。这种方式能够使模型区分不同位置,并且对于训练中未见过的序列长度具有一定的泛化能力。
4. 前馈网络
在每个Transformer的编码器和解码器层中,都包含一个前馈网络(Feed-Forward Network,FFN),该网络对自注意力层的输出进行进一步处理。
- 实现细节:前馈网络通常是两个线性变换的组合,中间有一个ReLU激活函数。公式可以表示为FFN(x) = max(0, xW1 + b1)W2 + b2,其中W1、W2是权重矩阵,b1、b2是偏置项。这个简单的网络结构能够增加模型的非线性表达能力。
3. 简单的实现
请注意,这里为了简化,我们省略了一些细节,比如层归一化(Layer Normalization)和残差连接(Residual Connections),这些都是完整Transformer模型的重要组成部分。
1. 导入必要的库
首先,确保安装了PyTorch:
pip install torch
2. 实现多头自注意力机制
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Attention mechanism
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
3. 构建Transformer的编码器层
class EncoderLayer(nn.Module):
def __init__(self, embed_size, heads, forward_expansion):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(embed_size, heads)
self.norm = nn.LayerNorm(embed_size)
self.ff = nn.Sequential(
nn.Linear(embed_size, forward_expansion * embed_size),
nn.ReLU(),
nn.Linear(forward_expansion * embed_size, embed_size),
)
def forward(self, x, mask):
attention = self.attention(x, x, x, mask)
x = self.norm(attention + x)
forward = self.ff(x)
out = self.norm(forward + x)
return out
4. 构建Transformer模型
这个简化的版本仅展示了编码器层的实现。完整的Transformer还需要实现解码器层、位置编码等组件。
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size,
embed_size,
num_layers,
heads,
device,
forward_expansion,
dropout,
max_length,
):
super(Transformer, self).__init__()
self.encoder = EncoderLayer(embed_size, heads, forward_expansion)
def forward(self, src, src_mask):
enc_src = self.encoder(src, src_mask)
return enc_src
5. 实例化和使用模型
在实际使用中,你需要根据自己的任务定义输入输出大小、词汇量等参数,并处理输入数据(比如,添加位置编码、应用适当的嵌入层等)。这个示例提供了Transformer的核心组件实现的概览,但在实际应用中,你可能需要根据具体任务做进一步的调整和优化。请记住,这里的代码是为了演示目的而大大简化的。完整的Transformer模型,如BERT或GPT,会包含更多的细节和优化。
应用
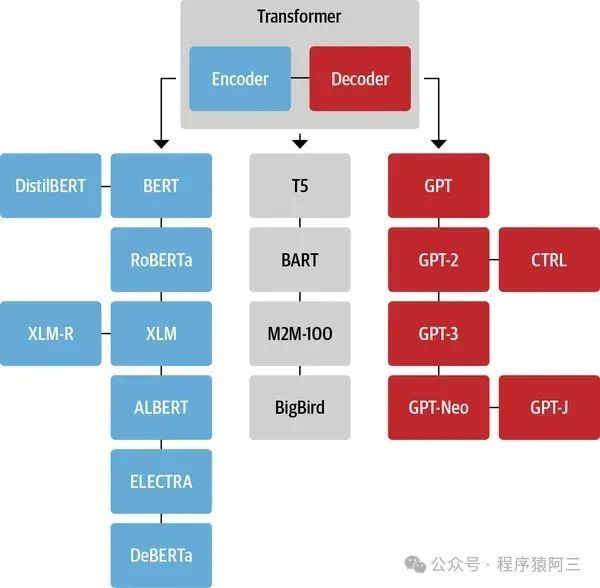
由于其高效的并行计算能力和对长距离依赖关系的良好捕捉能力,Transformer模型已经成为了许多NLP任务的基石,包括机器翻译、文本摘要、情感分析和问答系统等。此外,Transformer的变体,如BERT、GPT等,通过在大规模文本语料库上进行预训练,进一步推动了NLP领域的发展,实现了在多项任务上的最先进性能。Transformer模型的这些特性使其不仅限于NLP领域,还被扩展到了计算机视觉、语音处理等其他领域,展现了其广泛的适用性和强大的功能。