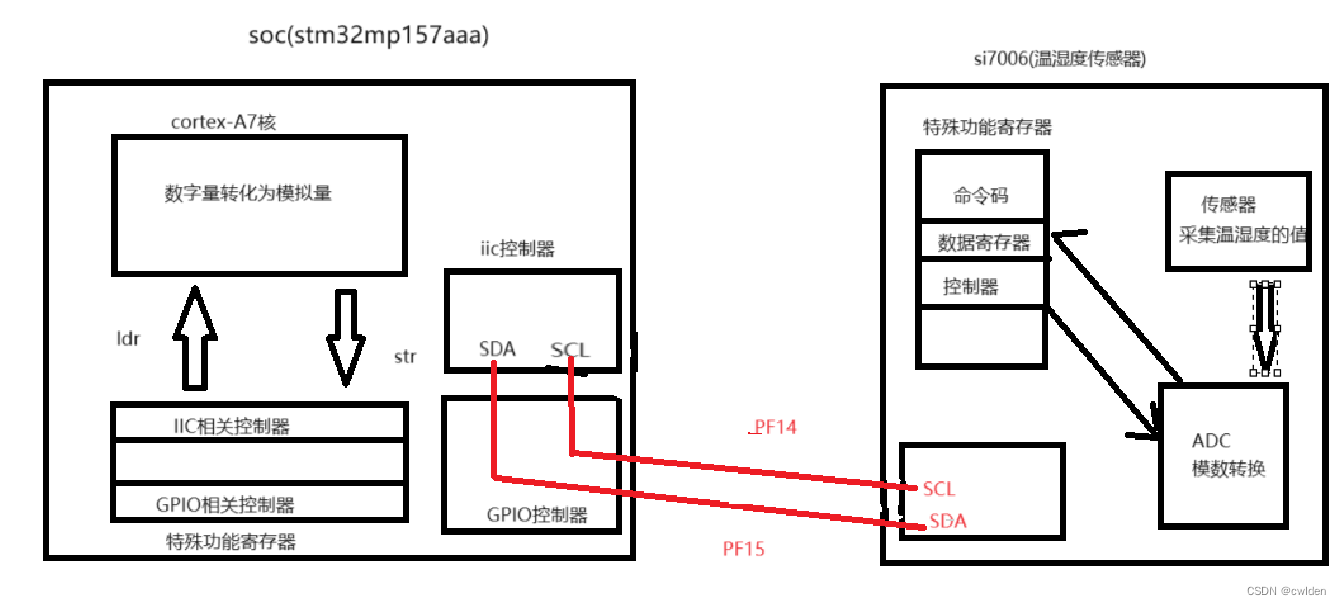
Transformer是深度学习领域的一种重要模型架构,由Google的研究人员于2017年提出。它最初应用于自然语言处理(NLP)任务,如机器翻译和文本分类,但后来扩展到了计算机视觉、音频处理等其他领域。
Transformer的核心创新点在于其使用了自注意力机制(Self-Attention),这使得模型能够更有效地捕获输入序列中的长程依赖关系。与传统的循环神经网络(RNN)相比,Transformer的并行化程度更高,因此在处理大型数据集时速度更快。
Transformer的基本结构包括以下组成部分:
输入层:
- 对输入序列进行嵌入操作,将单词转换为连续向量表示。
- 可选地,可以添加位置编码来保留输入序列的位置信息。
多头自注意力层(Multi-Head Self-Attention Layer):
- 这是Transformer的关键部分,它允许模型关注输入序列中的不同子区域。
- 多头自注意力通过并行计算多个自注意力函数,然后将结果拼接起来,提高模型的学习能力。
前馈神经网络(Feed-Forward Neural Network, FFN)层:
- 每个Transformer块包含两个线性变换(全连接层)和一个激活函数(通常是ReLU)。
- 这些层用于对自注意力层输出的特征进行进一步加工。
残差连接(Residual Connections):
- 在每个自注意力层和FFN层之后,都会添加一个残差连接,以缓解梯度消失问题,并帮助训练更深的网络。
层归一化(Layer Normalization):
- 用于加速模型收敛,并确保每层的输出具有相似的尺度。
解码器(仅在需要生成新序列的任务中使用):
- 解码器类似于编码器,但它使用了遮蔽自注意力(Masked Self-Attention),以防止当前位置获取到未来位置的信息。
- 编码器和解码器之间通常会有一个注意力层,让解码器可以根据编码器的输出生成新的序列。
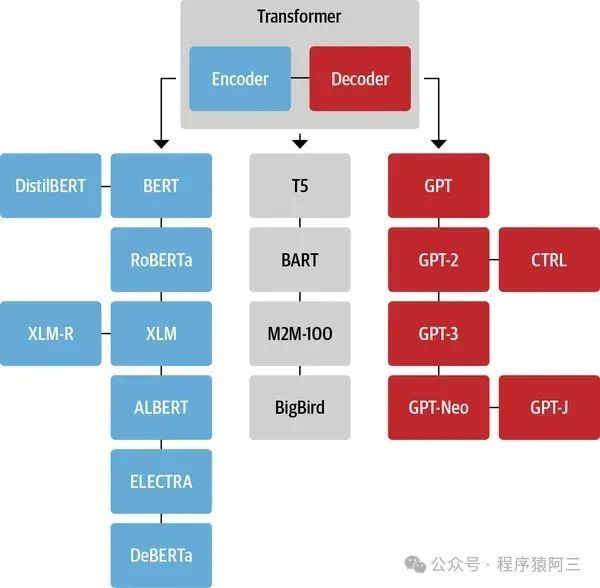
由于Transformer的出色性能和灵活性,它已经成为许多NLP任务的标准模型。此外,研究者们还提出了各种改进和扩展版本的Transformer,如BERT、GPT-3、T5等,这些模型在多项基准测试中取得了顶尖的表现。
Sequence to sequence(Seq2Seq)是一种深度学习架构,主要用于处理序列到序列的转换任务。这种模型最初由Google的研究人员在2014年提出,用于机器翻译任务,但后来被广泛应用于其他自然语言处理(NLP)任务,如对话系统、摘要生成、语音识别等。
Seq2Seq模型的基本结构包括两个主要部分:编码器和解码器。
编码器:
- 对输入序列进行编码,将其转换为一个固定长度的向量表示。
- 通常使用循环神经网络(RNN)、长短时记忆网络(LSTM)或门控循环单元(GRU)来实现。
解码器:
- 根据编码器输出的向量表示,生成新的目标序列。
- 解码器同样可以使用RNN、LSTM或GRU,并且在每个时间步都会利用到上一时间步的输出信息以及编码器的输出向量。
训练Seq2Seq模型时,需要提供一对对齐的输入序列和目标序列作为训练数据。模型会通过最小化预测序列与实际目标序列之间的差异(例如,交叉熵损失)来进行优化。
为了提高性能,Seq2Seq模型通常会采用以下技术:
- 注意力机制(Attention Mechanism):允许解码器在生成新词时关注输入序列中的特定部分,而不仅仅是编码器的输出向量。
- 双向编码器(Bidirectional Encoder):同时考虑输入序列的前后上下文信息,以提高建模能力。
- 多层网络(Multi-Layer Network):使用多层神经网络结构来提取更复杂的特征表示。