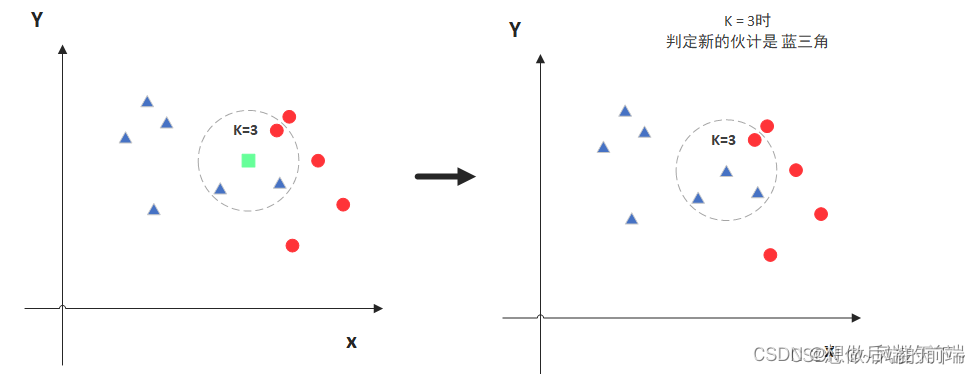
K 近邻算法概述
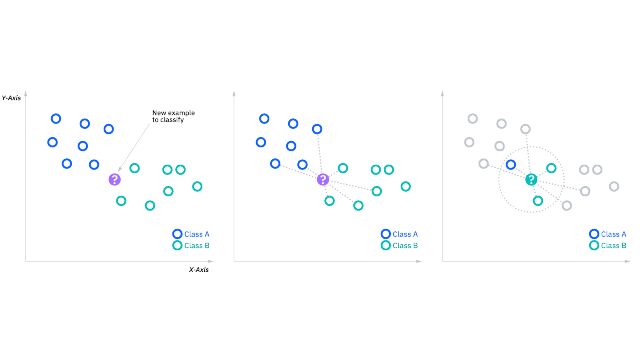
- K近邻算法的核心思想:距离接近的事物具有相同属性的可能性要大于距离相对较远的。
基本概念
K近邻算法(KNN):KNN表示K个最近的邻居的意思,即每个样本都可以用它最接近的K个邻居来代表。KNN核心思想是,如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
- 适用于类域交叉或重叠较多的带分样本集。
KNN常用的算法:
- Brute Force
- K-D Tree
- Ball Tree
常用算法解释
- 当使用K最近邻(KNN)算法时,有几种不同的实现方式,其中常用的包括Brute Force、K-D Tree和Ball Tree。
Brute Force(暴力法):
- 原理: 暴力法是最直接的方法,它计算每个点与数据集中所有其他点的距离,然后选择最近的邻居。
- 代码中的使用: 在代码中,可以通过将
algorithm参数设置为'brute'来使用暴力法。例如:from sklearn.neighbors import NearestNeighbors nbrs_brute = NearestNeighbors(n_neighbors=2, algorithm='brute').fit(X)
K-D Tree(K维树):
- 原理: K-D Tree是一种树形数据结构,可以提高KNN算法的性能。它通过在每个节点上选择一个维度进行划分,将数据集分成子集,从而减少距离计算的次数。
- 代码中的使用: 通过将
algorithm参数设置为'kd_tree'来使用K-D Tree。例如:from sklearn.neighbors import NearestNeighbors nbrs_kd_tree = NearestNeighbors(n_neighbors=2, algorithm='kd_tree').fit(X)
Ball Tree(球树):
- 原理: 类似于K-D Tree,球树也是一种树形数据结构,但它使用球体来划分数据集。球树在高维空间中通常比K-D Tree更高效。
- 代码中的使用: 通过将
algorithm参数设置为'ball_tree'来使用球树。例如:from sklearn.neighbors import NearestNeighbors nbrs_ball_tree = NearestNeighbors(n_neighbors=2, algorithm='ball_tree').fit(X)
- 选择算法取决于数据集的大小和维度。对于小型数据集,暴力法可能足够高效,而对于大型高维数据集,K-D Tree或球树可能更适合。在实际应用中,可以通过尝试不同的算法并评估它们的性能来选择合适的算法。
算法区别
这些K最近邻算法的本质都是基于计算样本点之间的距离,然后找到最近的邻居。它们的区别在于计算距离的方法和效率上的不同。
Brute Force(暴力法): 最简单直接的方法,计算每个点与所有其他点的距离,因此复杂度较高。
K-D Tree(K维树): 使用树形结构,通过在每个节点上选择一个维度进行划分,减少了距离计算的次数,适用于低维数据集。
Ball Tree(球树): 同样使用树形结构,但使用球体来划分数据集,特别适用于高维数据集,可以在某些情况下比K-D Tree更高效。
尽管它们的计算方法和效率不同,但它们都遵循了KNN的基本原理,即通过测量样本点之间的距离来找到最近的邻居。在实际应用中,选择合适的算法通常取决于数据集的特征,以及对性能和内存的要求。





























![【蓝桥杯冲冲冲】k 短路 / [SDOI2010] 魔法猪学院](https://img-blog.csdnimg.cn/direct/7003ab3546a94f21876f60180a88e6ed.jpeg#pic_center)