回顾
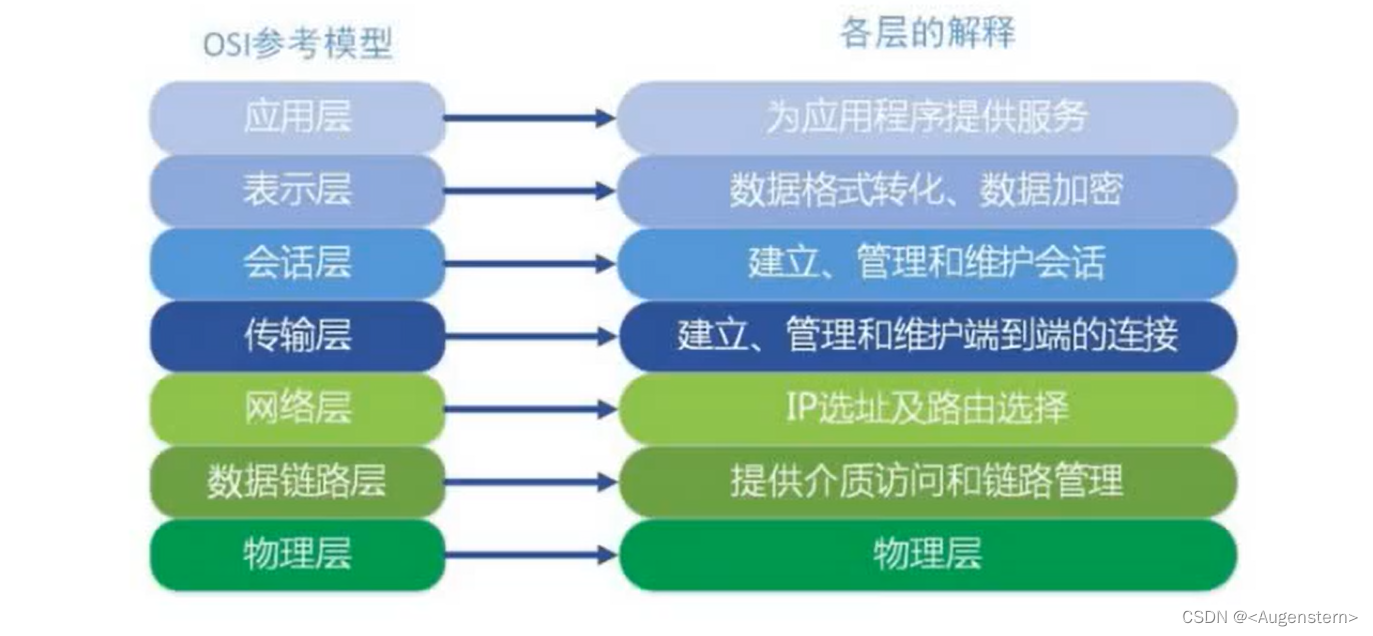
前面我们说到了数据链路层,网络层IP协议,传输层的TCP/UDP协议一些知识点,现在让我们谈谈 应用层的HTTP协议的知识点.
这篇我们先从大局入手,仍然是对总体报文进行全局分析,再对细节报文进行拆解分析
版本
首先我们谈谈HTTP协议的版本
HTTP 0.9 (1991)
HTTP 1.0 (1992 - 1996)
HTTP 1.1 (1997 - 1999) 常用
HTTP 2.0 (2012 - 2014) 常用
HTTP 3.0 (未完全完善)
这里的前面的HTTP版本一直到2.0都是基于TCP协议来实现的,然而3.0版本的协议是基于UDP版本的协议实现的/
目前讨论的是HTTP1.1协议,因为它是最常用的
2.0和3.0就是引入了一系列的机制提高传输数据和安全性
3.0基于UDP实现了一些更复杂的机制
例子
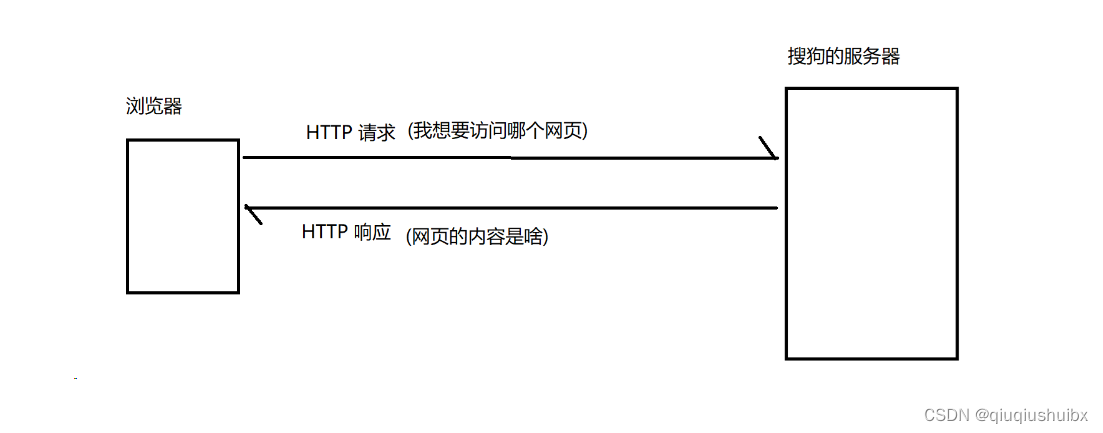
比如当前我们在浏览器输入一个网址,假设是搜狗搜索的网址,这里浏览器就会给搜狗的服务器发送一个HTTP请求,搜狗的服务器返回一个 HTTP响应,这个响应被浏览器解析之后,就展示成我们所看到的页面内容了,这就包含了HTML,CSS,JS等信息,所以称HTTP协议为超文本传输协议,就是能传输图片这样的能表达更多信息的内容
这里的响应就是指HTML+CSS+JS写成的网页
这里的文本指的是 字符串,能用utf8或gbk表示的合法字符串
超文本就是在这个基础上加上了图片等特殊格式
富文本 就是类似于word这种对格式有强要求的数据
HTTP协议的交互过程基本上也是一问一答的形式
但是点进去一个网页,如果出现这样的交互式窗口,称之为消息推送
HTTP抓包
为了更好地理解HTTP协议的报文内容,我们选择抓取传输的数据包来分析内容数据
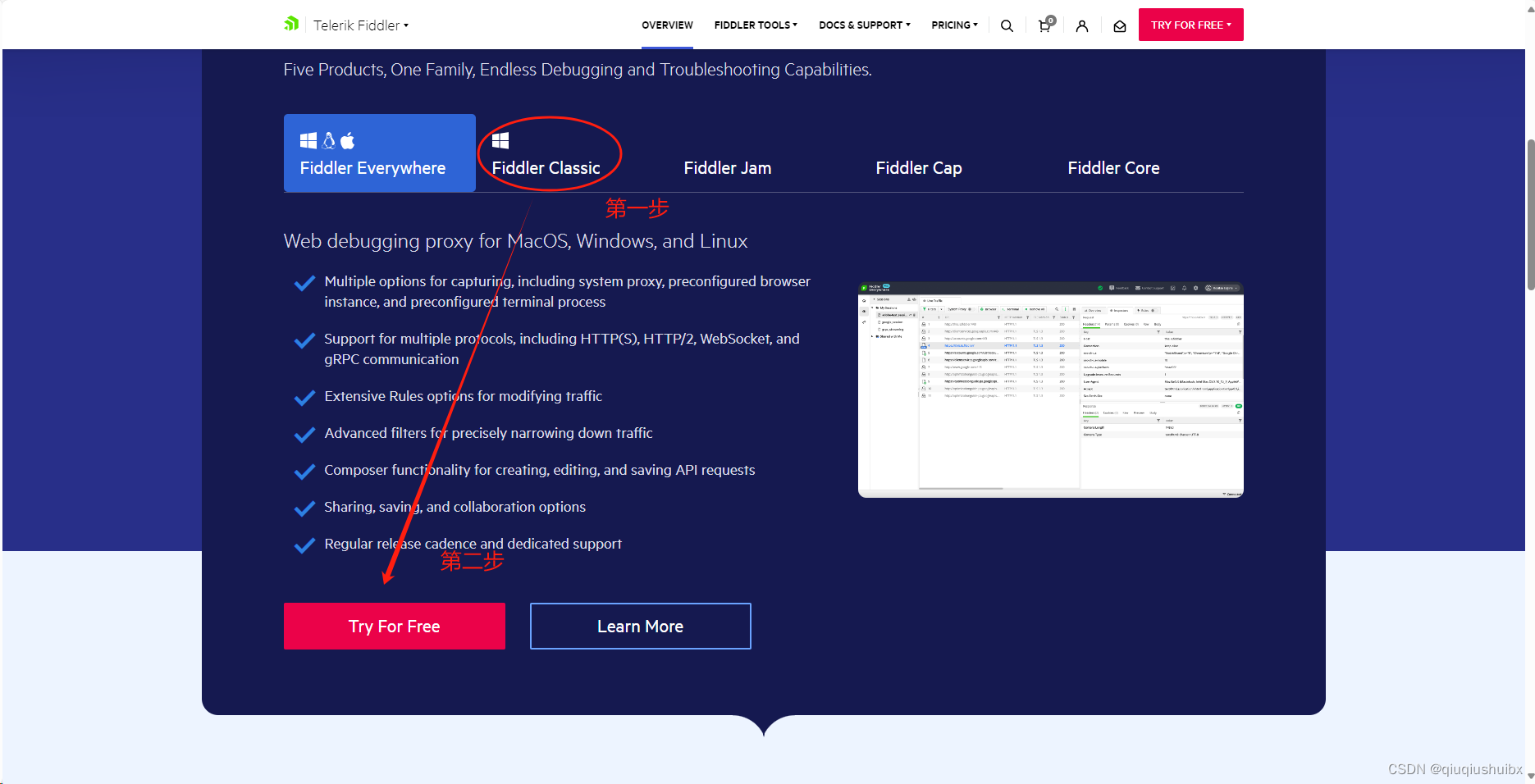
这里推荐使用Fiddler(专注HTTP协议,使用更便捷)
官网 Fiddler | Web Debugging Proxy and Troubleshooting Solutions (telerik.com)
点击社区版本
然后填写信息无脑安装即可
安装好之后,点击Tools
将这里的都勾选,就可以开始简单的抓包了
记得弹出的窗口问你是否同意证书记得得勾选
注:除了上述操作以外,电脑上的代理记得关闭,fiddler本质上也是一个代理程序,之间可能会产生冲突.
正确配置之后,程序中就会抓取到很多的数据包
肯呢个并不是浏览器的数据包
电脑上后台也会有很多应用程序在你感知不到的情况下做很多事情,比如向服务器发送一些HTTP/HTTPS请求
通常来说打开一个浏览器,浏览器和服务器之间的交互不仅仅只有一次,通常来说是有很多次的
比如说第一次拿到页面的HTML
在拿到CSS,JS等
当执行JS的时候又出现了很多http请求,获取到一些数据,经过这样的反复拉扯,就出现了呈现在你面前的网页
fiddler抓取的蓝色的往往是返回的HTML,往往是网站入站请求
双击就可以查看明细
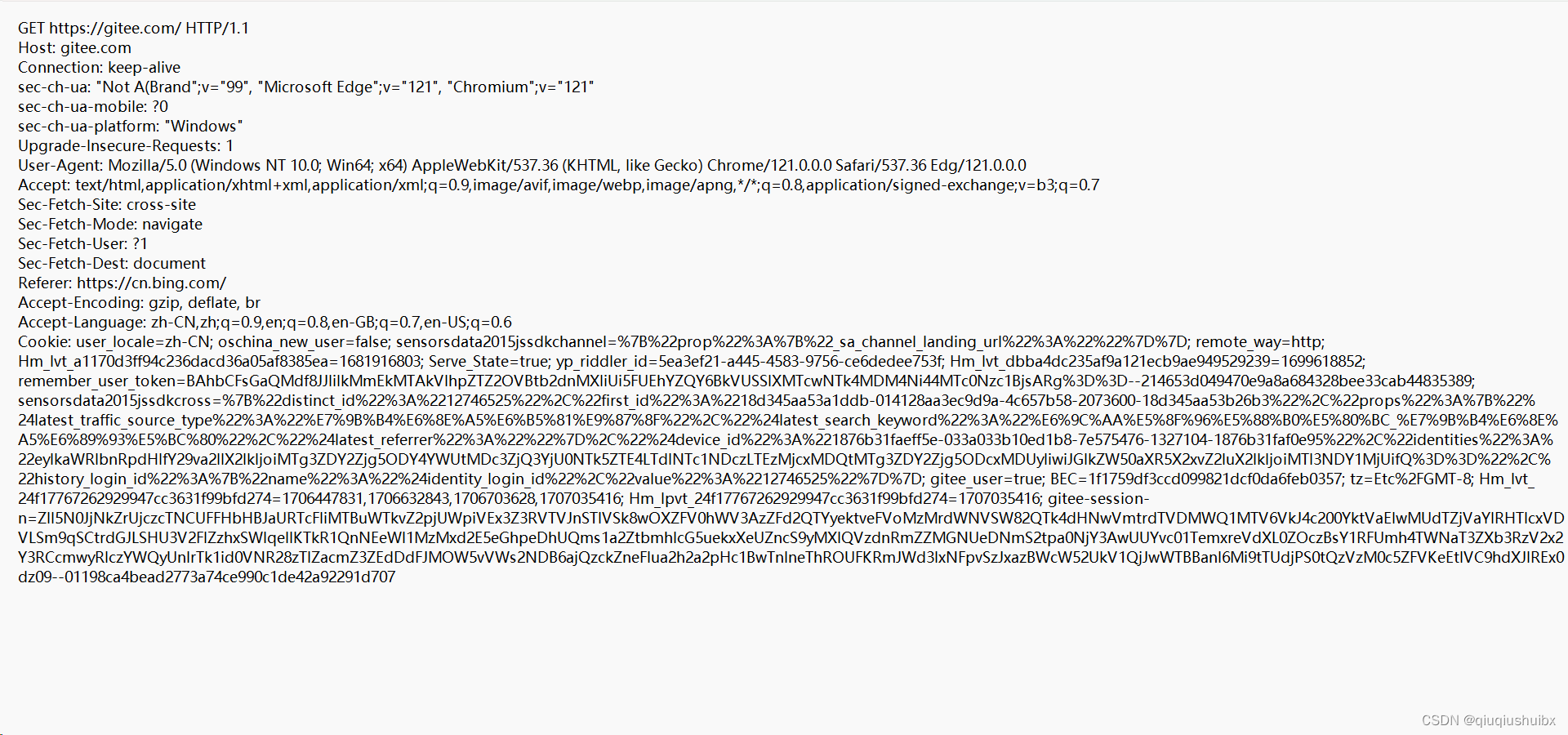
点击这两个之后就可以看到HTTP请求的组成格式
上面的raw表示的是显示原始数据,这里的请求会一定程度的压缩,因为网络带宽是有限的
下面那个是在记事本中查看,这样更加方便
下面的就是显示响应的报文 (记得点击黄色的框decode)
这里就是被压缩了,为了减少占用的网络带宽
为什么发送的请求报文没有压缩呢?
因为请求的报文本来就很短 就不需要压缩了





HTTP请求报文简介
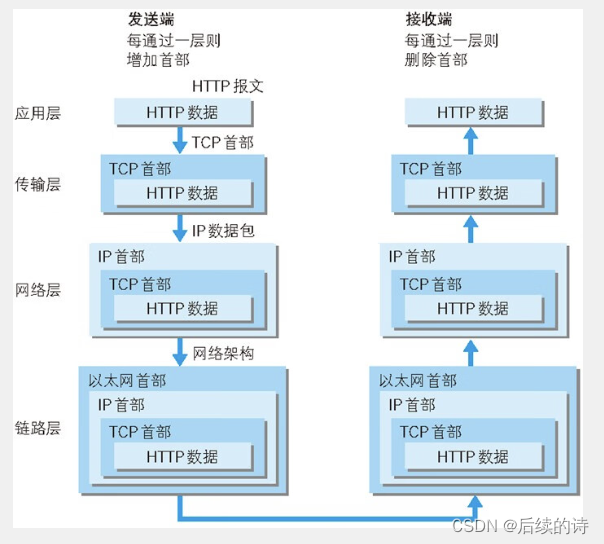
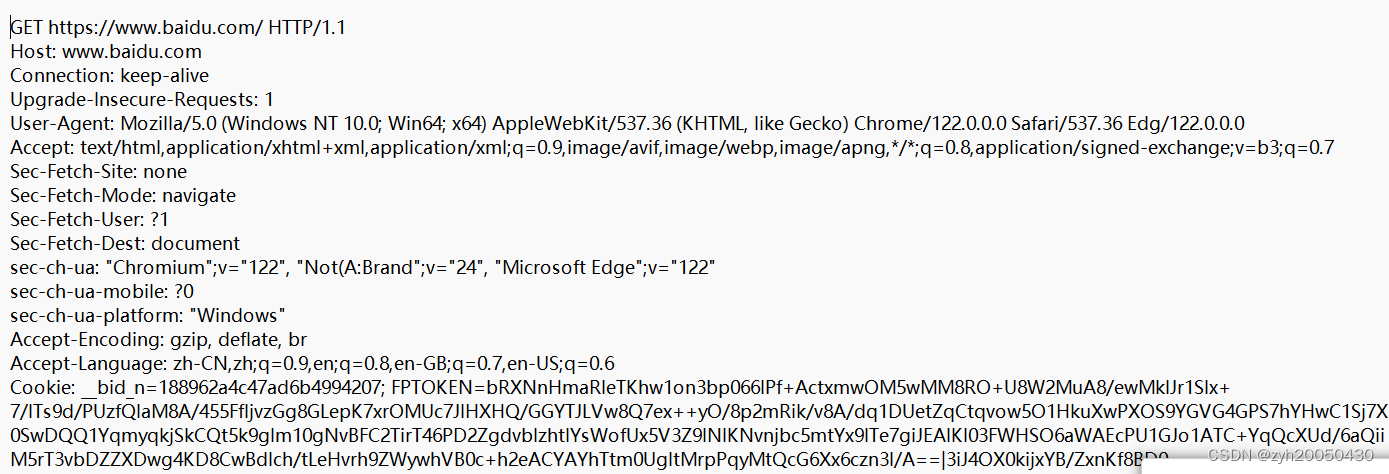
首先我们从整体上来看HTTP请求报文就是首行 + 请求头 + 空行 + 正文(可有可无)
这里首行就表示了 使用的请求方法 + URL + 请求使用的协议以及版本号
这里上文的请求报文从第二行到最后一行表示的就是 请求头
类似于TCP协议,包含着一些重要的属性信息 以键值对的方式呈现
最后是一个空行,代表报文的结束标记
大部分的请求不包含正文部分
HTTP响应报文简介
和请求的报文类似
以 首行 + 响应头 + 空行 + 正文 组成
这里的正文一般是存在的
首行包含的是 版本号 状态码 状态描述
比如 HTTP/1.1 200 OK
响应头仍然是以键值对方式来描述的一些属性信息
这里空行就不能作为结束标记了
这里的结束标记是以Content-Length来标记的
这就表示如何区分响应报文的结束标志

URL(网络资源定位符)
这里HTTP协议中的URL就描述了网络上唯一定位某个资源的定位符
这里的URL不仅仅只是在HTTP协议中使用到
像我们之前使用JDBC链接数据库也是使用到类似的内容的
下面我们来介绍一下HTTP协议中的URL的具体组成部分
一般常见的URL是以上的组成方式
协议方案名:HTTP/HTTPS
登录信息:user:pass 放在URL中对于现在来说不太安全,现在的登录信息都是有另外的页面来完成身份验证的
服务器ip:定位服务器地址
服务器端口号:确定应用程序,如果URL中不包含端口就会配置默认端口
带层次的文件路径:表示待访问资源的位置
查询字符串:对于资源地址查询的补充(不同的网站定义的规则不同)
片段标识符:一般是小说页面使用的,用通过不同的片段符能表示页面的跳转
下面还是以一家店铺买吃的来举例
eg:http://上海某饭店:18/招牌菜/红烧肉?餐具=需要&外带=是
URL encode
这里的URL encode一般是在query string 这里使用
在URL中一般会有很多字符代表着特殊的含义
比如 + / @ 等 或者是汉字也是需要转义的,如果直接使用就会导致浏览器的解析失败等等
所以我们常常就是将字符的ASCII码拿出来然后转为16进制加上%进行分割
这里搜索的C++ 就转义成了C%2B%2B
实际开发中,在URL中需要包含中文的时候一定要进行encode


HTTP方法
常见的方法如下,但是最常用的还是get方法(相对更多)和post方法
注:这里的方法使用说明只是编辑标注文档的作者的一厢情愿,其实我们可以任意搭配和使用这些方法
post方法常常有body,get方法常常没有body,假设一个登录的场景
post方法常常会将登录信息放到body中
get方法则会放到URL中
我们可以通过抓包查看(这里不做演示了)
post方法常用于登录,上传
get和post方法的区别
定论:两个没有啥区别,可以相互替代使用(大部分可以相互替代使用)
小部分浏览器不支持
但是两者在使用习惯上还是有区别的
1.post请求常常将数据写到body中传输,而get请求常常将数据放到URL中传输
2.语义的区别
get请求常常用来获取数据,post请求常常用来传输数据给服务器
3.标准文档中get请求要求是幂等的,post请求没有要求
幂等:输入内容一定,输出的内容也是一定的,称为幂等
4.get请求是可以被浏览器收藏的
post请求不可以被浏览器收藏的
关于post请求个get请求在互联网上广为流传的一些误解
1.post请求比get请求更安全???
论据:get请求的数据和登录信息放在URL,可以之间看到,所以不安全
结论:这完全就是扯,假设是post,我抓个包还不是能看到嘛,所以真正重要的是以什么方式来加密的
2.get传输的数据量小,post传输的数据量大?
这描述的是以前,以前的浏览器对URL是有大小限制的,现在则没有
3.get只能携带文本信息,post可以携带二进制数据?
这个结论不完全错误,其实URL通过query string携带数据
这里我们将二进制数据进行 URL encode,然后服务器进行decode就可以还原成二进制数据了post请求一般也不是直接携带二进制数据的,而是以base64编码或者是urlencode进行携带

报头简单解释(header)
1.Host 表示服务器的地址和端口
2.Content-Type Content-Length
这两个属性就表示了正文body中的内容长度和编码格式
也就是标志着结束在哪里,避免粘包问题
注:如果没有body部分其实就是空行作为结束标志
Type类型
1.application/json json格式
2.application/x-www-form-urlencoded form表单,通过HTML中的form标签构造的一种格式
可以认为是把query string 放到body里
3.multipart / form-data
上传文件的时候使用的,暂时不做过多介绍
响应中的报头格式
3.UA(user-agent)
也可以表示浏览器的使用设备是什么,就能依据这个信息来给不同的设备来匹配不同的页面显示,这样只需维护一套代码即可,但是现在越来越多的网站不使用UA进行区分了,因为CSS3出现了一个新特性,"媒体查询",可以根据不同的设备的尺寸大小来匹配不同的设备
5.referer
可以表示是从哪个页面来跳转过来的,比方说很多公司接广告,在早期移动这些网络运营商会在路由器上面搞小动作,修改成自己的referer,从而就能获取一定的广告费用,这样就很舒服
这是通过点击量来赚钱的.
现在就有了HTTPS 这个s可以理解为SSL(加密协议)
这里的正文信息等都是有密文加密的,不容易破解
就算破解了也很容易被感知到
6.cookie
cookie本质上是一个将数据持久化在硬盘上的一种方案
浏览器是可以读写电脑硬盘设备的,调用操作系统的api即可
其实理论上网页也是可以这样执行操作的,但是浏览器禁止了这种操作,为了安全起见
所以就提供了这样的api来退而求其次,能有限度的存储数据,而不是无限度的访问文件系统
重要结论:
1.cookie是服务器返回给客户端的,通常是首次访问或者登录之后
2.cookie会存储在浏览器本地硬盘中,后续访问服务器会带有cookie
3.cookie中存储的信息和query string样是程序员自定义的键值对信息
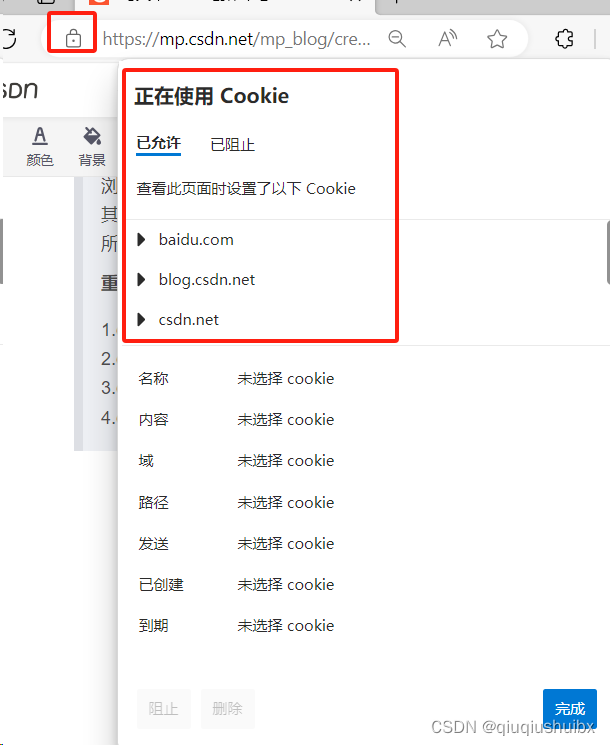
4.cookie在浏览器中的组织方式按照不同的域名为维度存储的,可以这样查看
5.cookie一般是保存用户的身份标识,这样服务器就可以通过不同的身份标识来区分用户了
注:HTTPS关注的是不能被篡改而不是不能被解密,所以密码放到cookie中不合适







![[<span style='color:red;'>HTTP</span><span style='color:red;'>协议</span>]<span style='color:red;'>应用</span><span style='color:red;'>层</span>的<span style='color:red;'>HTTP</span> <span style='color:red;'>协议</span>介绍](https://img-blog.csdnimg.cn/direct/b4ffcb01354a401e9b95a4110c74f68d.png)

























![【蓝桥杯冲冲冲】k 短路 / [SDOI2010] 魔法猪学院](https://img-blog.csdnimg.cn/direct/7003ab3546a94f21876f60180a88e6ed.jpeg#pic_center)