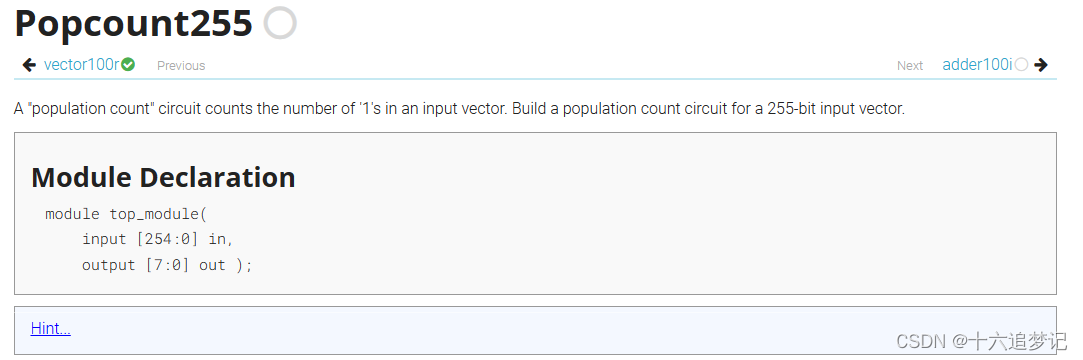
文章目录
通过引入注意力机制,模型可以在每个时间步中为输入序列中不同位置的词分配不同的注意力权重。这使得模型能够更加灵活地有选择地关注输入序列中的重要部分(见下图),从而更好地捕捉上下文相关性,模型的性能也会因此而提高。

注意力有很多种实现方式(也称实现机制),最简单的注意力机制是点积注意力。
点积注意力
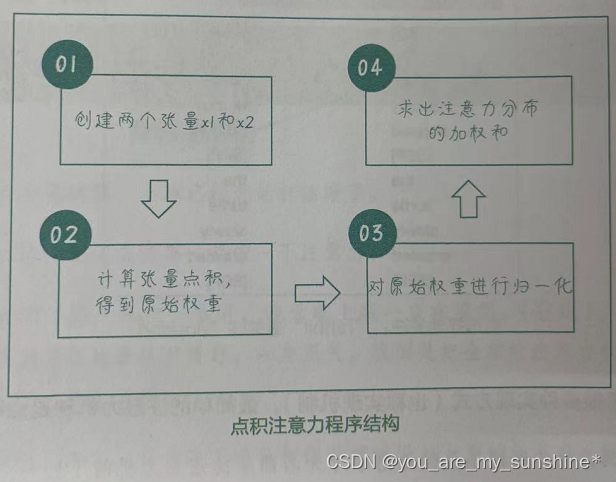
具体来说,要得到x1对x2的点积注意力,我们可以按照以下步骤进行操作。
(1)创建两个形状分别为(batch_size, seq_len1, feature_dim)和(batch_ size, seq_len2, feature_dim)的张量 x1 和 x2。
(2)将x1中的每个元素和x2中的每个元素进行点积,得到形状为(batch_size, seq_len1, seq_len2)的原始权重raw_weights。
(3)用softmax函数对原始权重进行归一化,得到归一化后的注意力权重 attn_weights(注意力权重的值在0和1之间,且每一行的和为1),形状仍为(batch_size, seq_len1, seq_len2)。
(4)用注意力权重attn_weights对x2 中的元素进行加权求和(与x2相乘),得到输出张量 y,形状为(batch_size, seq_len1, feature_dim)。这就是x1对x2的点积注意力。
程序结构如下:
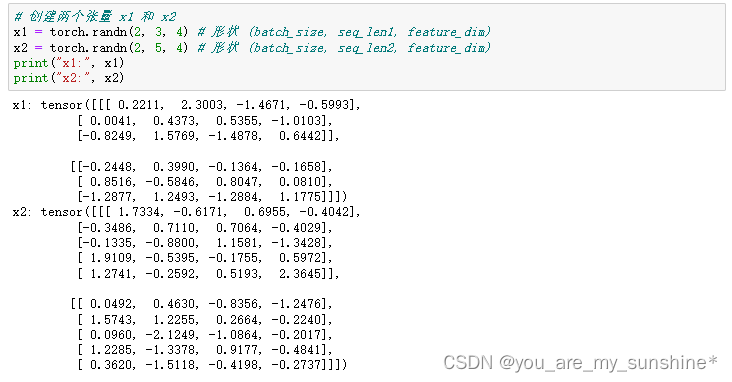
创建两个张量x1和x2
# 创建两个张量 x1 和 x2
x1 = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len1, feature_dim)
x2 = torch.randn(2, 5, 4) # 形状 (batch_size, seq_len2, feature_dim)
print("x1:", x1)
print("x2:", x2)
计算张量点积, 得到原始权重
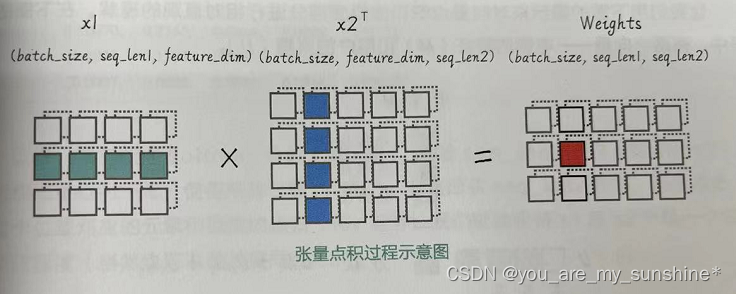

# 计算点积,得到原始权重,形状为 (batch_size, seq_len1, seq_len2)
raw_weights = torch.bmm(x1, x2.transpose(1, 2))
print(" 原始权重:", raw_weights)

对原始权重进行归一化

import torch.nn.functional as F # 导入 torch.nn.functional
# 应用 softmax 函数,使权重的值在 0 和 1 之间,且每一行的和为 1
attn_weights = F.softmax(raw_weights, dim=-1) # 归一化
print(" 归一化后的注意力权重:", attn_weights)

求出注意力分布的加权和
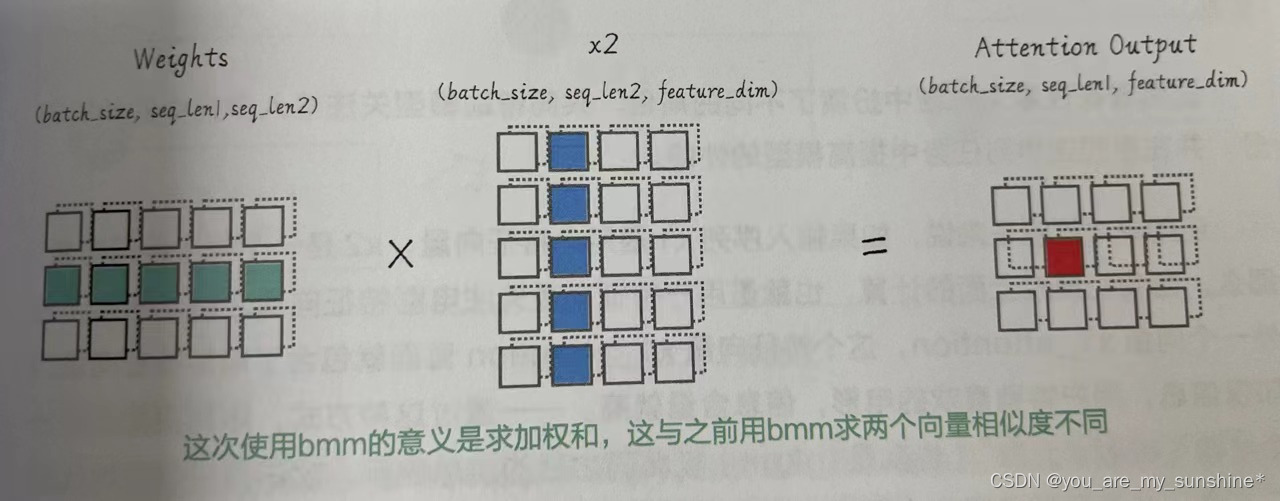
# 与 x2 相乘,得到注意力分布的加权和,形状为 (batch_size, seq_len1, feature_dim)
attn_output = torch.bmm(attn_weights, x2)
print(" 注意力输出 :", attn_output)

缩放点积注意力
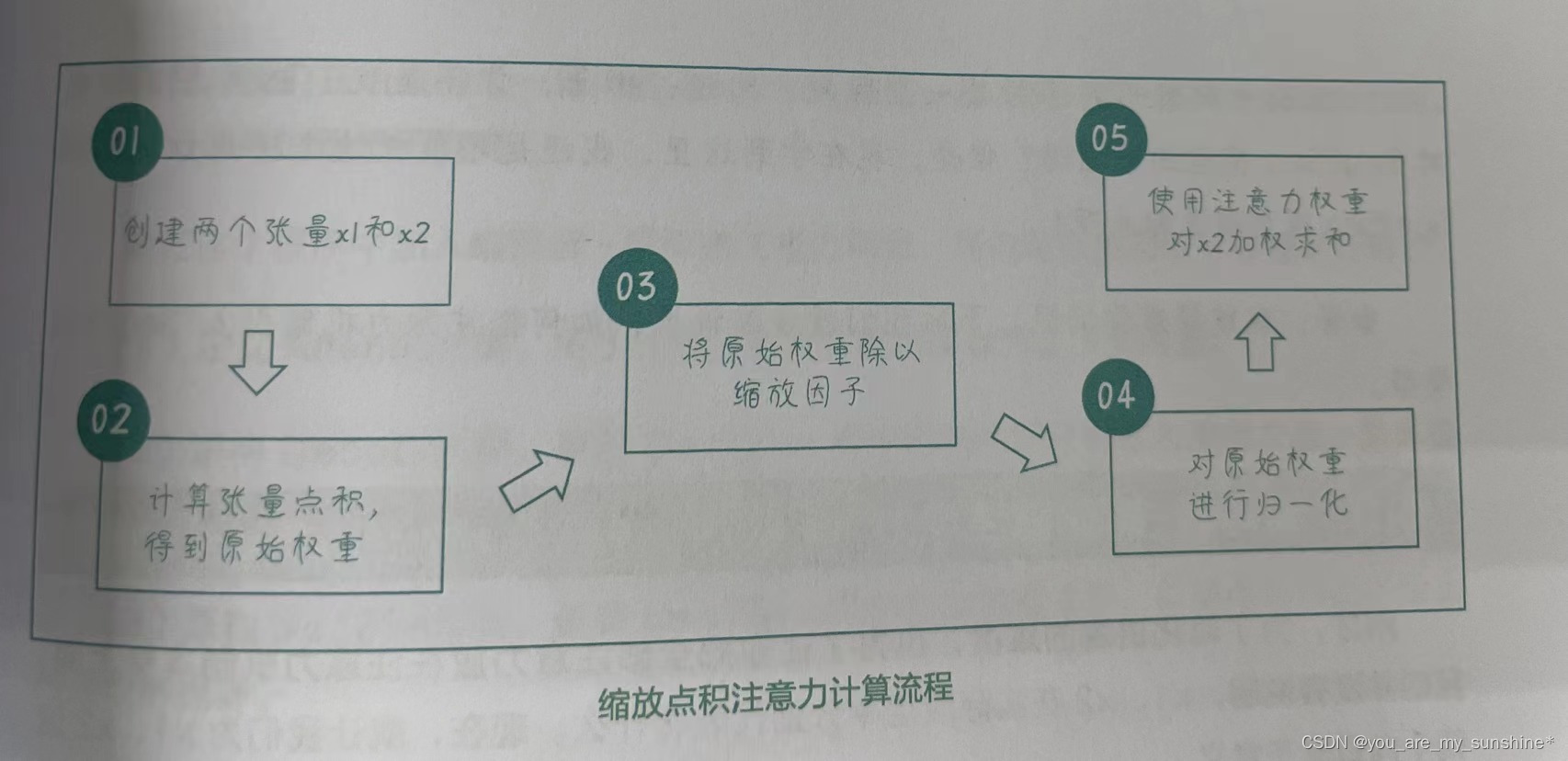
缩放点积注意力(Scaled Dot-Product Attention)和点积注意力(Dot-Product Attention)之间的主要区别在于:缩放点积注意力在计算注意力权重之前,会将点积结果也就是原始权重除以一个缩放因子,得到缩放后的原始权重。通常,这个缩放因子是输入特征维度的平方根。
为什么要使用缩放因子呢?在深度学习模型中,点积的值可能会变得非常大,尤其是当特征维度较大时。当点积值特别大时,softmax函数可能会在一个非常陡峭的区域内运行,导致梯度变得非常小,也可能会导致训练过程中梯度消失。通过使用缩放因子,可以确保 softmax函数在一个较为平缓的区域内工作,从而减轻梯度消失问题,提高模型的稳定性。
缩放点积注意力的计算流程如下:
import torch # 导入 torch
import torch.nn.functional as F # 导入 nn.functional
# 1. 创建两个张量 x1 和 x2
x1 = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len1, feature_dim)
x2 = torch.randn(2, 5, 4) # 形状 (batch_size, seq_len2, feature_dim)
# 2. 计算张量点积,得到原始权重
raw_weights = torch.bmm(x1, x2.transpose(1, 2)) # 形状 (batch_size, seq_len1, seq_len2)
# 3. 将原始权重除以缩放因子
scaling_factor = x1.size(-1) ** 0.5
scaled_weights = raw_weights / scaling_factor # 形状 (batch_size, seq_len1, seq_len2)
# 4. 对原始权重进行归一化
attn_weights = F.softmax(scaled_weights, dim=2) # 形 状 (batch_size, seq_len1, seq_len2)
# 5. 使用注意力权重对 x2 加权求和
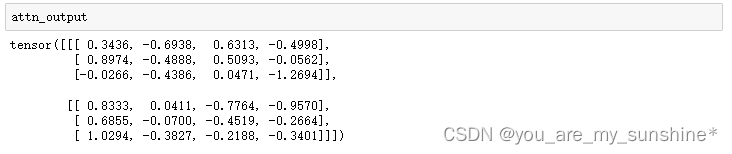
attn_output = torch.bmm(attn_weights, x2) # 形状 (batch_size, seq_len1, feature_dim)
attn_output
编码器-解码器注意力
刚才,为了简化讲解的难度,也为了让你把全部注意力放在注意力机制本身上面。我们并没有说明,x1、x2在实际应用中分别代表着什么。现在,就让我们为x1、x2这两个向量赋予意义。
在Seq2Seq架构中,点积注意力通常用于将编码器的隐藏状态与解码器的隐藏状态联系起来。在这种情况下,x1和x2对应的内容分别如下。
- x1:这是解码器在各个时间步的隐藏状态,形状为(batch_size,seq_len1, feature_dim)。其中,seq_len1是解码器序列的长度,feature_dim 是隐藏状态的维度。
- x2:这是编码器在各个时间步的隐藏状态,形状为(batch_size,seq_len2, feature_dim)。其中,seq_len2是编码器序列的长度,feature_dim 是隐藏状态的维度。
当我们应用点积注意力时,解码器的每个时间步都会根据编码器的隐藏状态计算一个注意力权重,然后将这些权重应用于编码器隐藏状态,以生成一个上下文向量(编码器一解码器注意力的输出)。这个上下文向量将包含关于编码器输入序列的有用信息,解码器可以利用这个信息生成更准确的输出序列,如下图所示。

开始重构上一节中的Seq2Seq模型,加入编码器一解码器注意力机制。数据集和训练过程都不改变。
要在这个程序中加入编码器——解码器注意力机制,我们可以按照以下步骤进行修改。
(1)定义Attention类。用于计算注意力权重和注意力上下文向量。
(2)重构Decoder类。更新Decoder类的初始化部分和前向传播方法,使其包含注意力层并在解码过程中利用注意力权重。
(3)重构Seq2Seq类。更新 Seq2Seq类的前向传播方法,以便将编码器的输出传递给解码器。
(4)可视化注意力权重。
# 构建语料库,每行包含中文、英文(解码器输入)和翻译成英文后的目标输出 3 个句子
sentences = [
['哒哥 喜欢 爬山', '<sos> DaGe likes climb', 'DaGe likes climb <eos>'],
['我 爱 学习 人工智能', '<sos> I love studying AI', 'I love studying AI <eos>'],
['深度学习 改变 世界', '<sos> DL changed the world', 'DL changed the world <eos>'],
['自然 语言 处理 很 强大', '<sos> NLP is so powerful', 'NLP is so powerful <eos>'],
['神经网络 非常 复杂', '<sos> Neural-Nets are complex', 'Neural-Nets are complex <eos>']]
word_list_cn, word_list_en = [], [] # 初始化中英文词汇表
# 遍历每一个句子并将单词添加到词汇表中
for s in sentences:
word_list_cn.extend(s[0].split())
word_list_en.extend(s[1].split())
word_list_en.extend(s[2].split())
# 去重,得到没有重复单词的词汇表
word_list_cn = list(set(word_list_cn))
word_list_en = list(set(word_list_en))
# 构建单词到索引的映射
word2idx_cn = {
w: i for i, w in enumerate(word_list_cn)}
word2idx_en = {
w: i for i, w in enumerate(word_list_en)}
# 构建索引到单词的映射
idx2word_cn = {
i: w for i, w in enumerate(word_list_cn)}
idx2word_en = {
i: w for i, w in enumerate(word_list_en)}
# 计算词汇表的大小
voc_size_cn = len(word_list_cn)
voc_size_en = len(word_list_en)
print(" 句子数量:", len(sentences)) # 打印句子数
print(" 中文词汇表大小:", voc_size_cn) # 打印中文词汇表大小
print(" 英文词汇表大小:", voc_size_en) # 打印英文词汇表大小
print(" 中文词汇到索引的字典:", word2idx_cn) # 打印中文词汇到索引的字典
print(" 英文词汇到索引的字典:", word2idx_en) # 打印英文词汇到索引的字典

import numpy as np # 导入 numpy
import torch # 导入 torch
import random # 导入 random 库
# 定义一个函数,随机选择一个句子和词汇表生成输入、输出和目标数据
def make_data(sentences):
# 随机选择一个句子进行训练
random_sentence = random.choice(sentences)
# 将输入句子中的单词转换为对应的索引
encoder_input = np.array([[word2idx_cn[n] for n in random_sentence[0].split()]])
# 将输出句子中的单词转换为对应的索引
decoder_input = np.array([[word2idx_en[n] for n in random_sentence[1].split()]])
# 将目标句子中的单词转换为对应的索引
target = np.array([[word2idx_en[n] for n in random_sentence[2].split()]])
# 将输入、输出和目标批次转换为 LongTensor
encoder_input = torch.LongTensor(encoder_input)
decoder_input = torch.LongTensor(decoder_input)
target = torch.LongTensor(target)
return encoder_input, decoder_input, target
# 使用 make_data 函数生成输入、输出和目标张量
encoder_input, decoder_input, target = make_data(sentences)
for s in sentences: # 获取原始句子
if all([word2idx_cn[w] in encoder_input[0] for w in s[0].split()]):
original_sentence = s
break
print(" 原始句子:", original_sentence) # 打印原始句子
print(" 编码器输入张量的形状:", encoder_input.shape) # 打印输入张量形状
print(" 解码器输入张量的形状:", decoder_input.shape) # 打印输出张量形状
print(" 目标张量的形状:", target.shape) # 打印目标张量形状
print(" 编码器输入张量:", encoder_input) # 打印输入张量
print(" 解码器输入张量:", decoder_input) # 打印输出张量
print(" 目标张量:", target) # 打印目标张量

定义Attention类
# 定义 Attention 类
import torch.nn as nn # 导入 torch.nn 库
class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
def forward(self, decoder_context, encoder_context):
# 计算 decoder_context 和 encoder_context 的点积,得到注意力分数
scores = torch.matmul(decoder_context, encoder_context.transpose(-2, -1))
# 归一化分数
attn_weights = nn.functional.softmax(scores, dim=-1)
# 将注意力权重乘以 encoder_context,得到加权的上下文向量
context = torch.matmul(attn_weights, encoder_context)
return context, attn_weights
重构Decoder类
import torch.nn as nn # 导入 torch.nn 库
# 定义编码器类
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.hidden_size = hidden_size # 设置隐藏层大小
self.embedding = nn.Embedding(input_size, hidden_size) # 创建词嵌入层
self.rnn = nn.RNN(hidden_size, hidden_size, batch_first=True) # 创建 RNN 层
def forward(self, inputs, hidden): # 前向传播函数
embedded = self.embedding(inputs) # 将输入转换为嵌入向量
output, hidden = self.rnn(embedded, hidden) # 将嵌入向量输入 RNN 层并获取输出
return output, hidden
# 定义解码器类
class DecoderWithAttention(nn.Module):
def __init__(self, hidden_size, output_size):
super(DecoderWithAttention, self).__init__()
self.hidden_size = hidden_size # 设置隐藏层大小
self.embedding = nn.Embedding(output_size, hidden_size) # 创建词嵌入层
self.rnn = nn.RNN(hidden_size, hidden_size, batch_first=True) # 创建 RNN 层
self.attention = Attention() # 创建注意力层
self.out = nn.Linear(2 * hidden_size, output_size) # 修改线性输出层,考虑隐藏状态和上下文向量
def forward(self, dec_input, hidden, enc_output):
embedded = self.embedding(dec_input) # 将输入转换为嵌入向量
rnn_output, hidden = self.rnn(embedded, hidden) # 将嵌入向量输入 RNN 层并获取输出
context, attn_weights = self.attention(rnn_output, enc_output) # 计算注意力上下文向量
dec_output = torch.cat((rnn_output, context), dim=-1) # 将上下文向量与解码器的输出拼接
dec_output = self.out(dec_output) # 使用线性层生成最终输出
return dec_output, hidden, attn_weights
n_hidden = 128 # 设置隐藏层数量
# 创建编码器和解码器
encoder = Encoder(voc_size_cn, n_hidden)
decoder = DecoderWithAttention(n_hidden, voc_size_en)
print(' 编码器结构:', encoder) # 打印编码器的结构
print(' 解码器结构:', decoder) # 打印解码器的结构

重构Seq2Seq类
# 定义 Seq2Seq 类
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2Seq, self).__init__()
# 初始化编码器和解码器
self.encoder = encoder
self.decoder = decoder
def forward(self, encoder_input, hidden, decoder_input):
# 将输入序列通过编码器并获取输出和隐藏状态
encoder_output, encoder_hidden = self.encoder(encoder_input, hidden)
# 将编码器的隐藏状态传递给解码器作为初始隐藏状态
decoder_hidden = encoder_hidden
# 将目标序列通过解码器并获取输出 - 此处更新解码器调用
decoder_output, _, attn_weights = self.decoder(decoder_input, decoder_hidden, encoder_output)
return decoder_output, attn_weights
# 创建 Seq2Seq 模型
model = Seq2Seq(encoder, decoder)
print('S2S 模型结构:', model) # 打印模型的结构

# 定义训练函数
def train_seq2seq(model, criterion, optimizer, epochs):
for epoch in range(epochs):
encoder_input, decoder_input, target = make_data(sentences) # 训练数据的创建
hidden = torch.zeros(1, encoder_input.size(0), n_hidden) # 初始化隐藏状态
optimizer.zero_grad()# 梯度清零
output, _ = model(encoder_input, hidden, decoder_input) # 获取模型输出
loss = criterion(output.view(-1, voc_size_en), target.view(-1)) # 计算损失
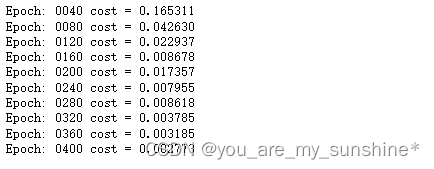
if (epoch + 1) % 40 == 0: # 打印损失
print(f"Epoch: {
epoch + 1:04d} cost = {
loss:.6f}")
loss.backward()# 反向传播
optimizer.step()# 更新参数
# 训练模型
epochs = 400 # 训练轮次
criterion = nn.CrossEntropyLoss() # 损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 优化器
train_seq2seq(model, criterion, optimizer, epochs) # 调用函数训练模型
可视化注意力权重
import matplotlib.pyplot as plt # 导入 matplotlib
import seaborn as sns # 导入 seaborn
plt.rcParams["font.family"]=['SimHei'] # 用来设定字体样式
plt.rcParams['font.sans-serif']=['SimHei'] # 用来设定无衬线字体样式
plt.rcParams['axes.unicode_minus']=False # 用 来 正 常 显 示 负 号
def visualize_attention(source_sentence, predicted_sentence, attn_weights):
plt.figure(figsize=(10, 10)) # 画布
ax = sns.heatmap(attn_weights, annot=True, cbar=False,
xticklabels=source_sentence.split(),
yticklabels=predicted_sentence, cmap="Greens") # 热力图
plt.xlabel(" 源序列 ")
plt.ylabel(" 目标序列 ")
plt.show() # 显示图片
# 定义测试函数
def test_seq2seq(model, source_sentence):
# 将输入的句子转换为索引
encoder_input = np.array([[word2idx_cn[n] for n in source_sentence.split()]])
# 构建输出的句子的索引,以 '<sos>' 开始,后面跟 '<eos>',长度与输入句子相同
decoder_input = np.array([word2idx_en['<sos>']] + [word2idx_en['<eos>']]*(len(encoder_input[0])-1))
# 转换为 LongTensor 类型
encoder_input = torch.LongTensor(encoder_input)
decoder_input = torch.LongTensor(decoder_input).unsqueeze(0) # 增加一维
hidden = torch.zeros(1, encoder_input.size(0), n_hidden) # 初始化隐藏状态
# 获取模型输出和注意力权重
predict, attn_weights = model(encoder_input, hidden, decoder_input)
predict = predict.data.max(2, keepdim=True)[1] # 获取概率最大的索引
# 打印输入的句子和预测的句子
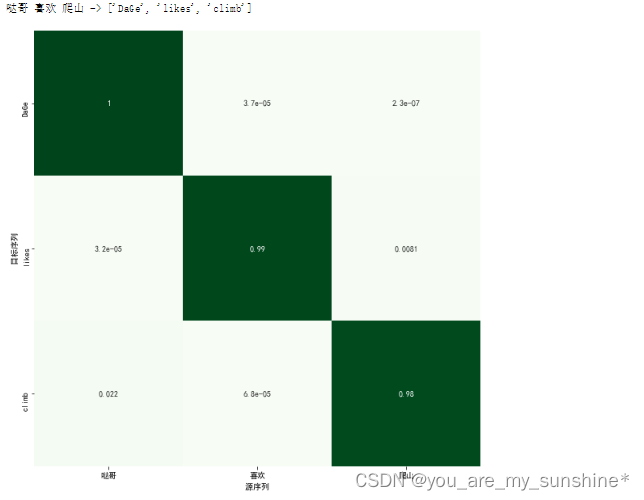
print(source_sentence, '->', [idx2word_en[n.item()] for n in predict.squeeze()])
# 可视化注意力权重
attn_weights = attn_weights.squeeze(0).cpu().detach().numpy()
visualize_attention(source_sentence, [idx2word_en[n.item()] for n in predict.squeeze()], attn_weights)
# 测试模型
test_seq2seq(model, '哒哥 喜欢 爬山')
test_seq2seq(model, '自然 语言 处理 很 强大')

注意力机制中的 Q、K、V
在注意力机制中,查询(Query)、键(Key)和值(Value)是三个关键部分。
- 查询(Query):是指当前需要处理的信息。模型根据查询向量在输入序列中查找相关信息。
- 键(Key):是指来自输入序列的一组表示。它们用于根据查询向量计算注意力权重。注意力权重反映了不同位置的输入数据与查询的相关性。
- 值(Value):是指来自输入序列的一组表示。它们用于根据注意力权重计算加权和,得到最终的注意力输出向量,其包含了与查询最相关的输入信息。
注意力机制通过计算查询向量与各个键向量之间的相似性,为每个值向量分配一个权重。然后,将加权的值相加,也就是将每个值向量乘以其对应的权重(即注意力分数),得到一个蕴含输入序列最相关信息的输出向量。这个输出向量的形状和查询向量相同,将用于下一步模型计算的输入。
import torch # 导入 torch
import torch.nn.functional as F # 导入 nn.functional
# 1. 创建两个张量 x1 和 x2
x1 = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len1, feature_dim)
x2 = torch.randn(2, 5, 4) # 形状 (batch_size, seq_len2, feature_dim)
# 2. 计算原始权重
raw_weights = torch.bmm(x1, x2.transpose(1, 2)) # 形状 (batch_size, seq_len1, seq_len2)
# 3. 用 softmax 函数对原始权重进行归一化
attn_weights = F.softmax(raw_weights, dim=2) # 形状 (batch_size, seq_len1, seq_len2)
# 4. 将注意力权重与 x2 相乘,计算加权和
attn_output = torch.bmm(attn_weights, x2) # 形状 (batch_size, seq_len1, feature_dim)
在这个示例中,我们仅使用了两个张量x1 和x2 来说明最基本的注意力机制。在这个简化的情况下,我们可以将x1 视为查询(Query,Q)向量,将x2视为键(Key,K)和值(Value,V)向量。这是因为我们直接使用xl和x2的点积作为相似度得分,并将权重应用于x2 本身来计算加权信息。所以,在这个简化示例中,Q对应于x1,K和V都对应于x2。
然而,在Transformer中,Q、K和V通常是从相同的输入序列经过不同的线性 。
下面的代码创建三个独立的张量来分别代表Q、K和V,并进行注意力的计算。
import torch
import torch.nn.functional as F
#1. 创建 Query、Key 和 Value 张量
q = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len1, feature_dim)
k = torch.randn(2, 4, 4) # 形状 (batch_size, seq_len2, feature_dim)
v = torch.randn(2, 4, 4) # 形状 (batch_size, seq_len2, feature_dim)
# 2. 计算点积,得到原始权重,形状为 (batch_size, seq_len1, seq_len2)
raw_weights = torch.bmm(q, k.transpose(1, 2))
# 3. 将原始权重进行缩放(可选),形状仍为 (batch_size, seq_len1, seq_len2)
scaling_factor = q.size(-1) ** 0.5
scaled_weights = raw_weights / scaling_factor
# 4. 应用 softmax 函数,使结果的值在 0 和 1 之间,且每一行的和为 1
attn_weights = F.softmax(scaled_weights, dim=-1) # 形状仍为 (batch_size, seq_len1, seq_len2)
# 5. 与 Value 相乘,得到注意力分布的加权和 , 形状为 (batch_size, seq_len1, feature_dim)
attn_output = torch.bmm(attn_weights, v)
attn_output

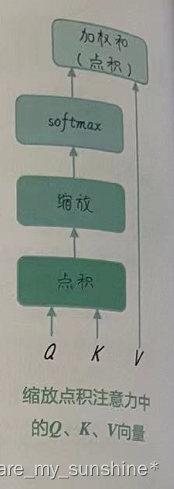
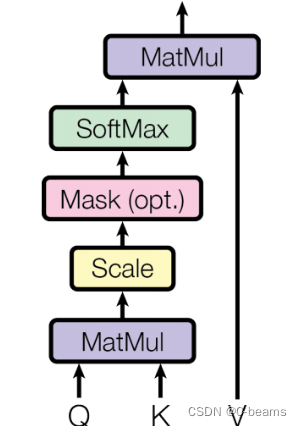
现在,重写缩放点积注意力的计算过程,如下所述。
(1)计算Q向量和K向量的点积。
(2)将点积结果除以缩放因子(Q向量特征维度的平方根)。
(3)应用softmax 函数得到注意力权重。
(4)使用注意力权重对V向量进行加权求和。
这个过程的图示如下图所示。
Q向量代表了解码器在当前时间步的表示,用于和K向量进行匹配,以计算注意力权重。Q向量通常是解码器隐藏状态的线性变换。
K向量是编码器输出的一种表示,用于和Q向量进行匹配,以确定哪些编码器输出对于当前解码器时间步来说最相关。K向量通常是编码器隐藏状态的线性变换。
V向量是编码器输出的另一种表示,用于计算加权求和,生成注意力上下文向量。注意力权重会作用在V向量上,以便在解码过程中关注输入序列中的特定部分。V向量通常也是编码器隐藏状态的线性变换。
在刚才的编码器一解码器注意力示例中,直接使用了编码器隐藏状态和解码器隐藏状态来计算注意力。这里的Q、K和V向量并没有显式地表示出来(而且,此处K和V是同一个向量),但它们的概念仍然隐含在实现中:
- 编码器隐藏状态(encoder_hidden_states )充当了K和V向量的角色。
- 解码器隐藏状态(decoder_hidden_states )充当了Q向量的角色。
我们计算Q向量(解码器隐藏状态)与K向量(编码器隐藏状态)之间的点积来得到注意力权重,然后用这些权重对V向量(编码器隐藏状态)进行加权求和,得到上下文向量。
当然了,在一些更复杂的注意力机制(如Transformer中的多头自注意力机制)中,Q、K、V向量通常会更明确地表示出来,因为我们需要通过使用不同的线性层将相
同的输入序列显式地映射到不同的Q、K、V向量空间。
自注意力
**自注意力就是自己对自己的注意,它允许模型在同一序列中的不同位置之间建立依赖关系。**用我们刚才讲过的最简单的注意力来理解,如果我们把x2替换为x1 自身,那么我们其实就实现了x1每一个位置对自身其他序列的所有位置的加权和。
下面的代码就实现了一个最简单的自注意力机制。
import torch
import torch.nn.functional as F
# 一个形状为 (batch_size, seq_len, feature_dim) 的张量 x
x = torch.randn(2, 3, 4)
# 计算原始权重,形状为 (batch_size, seq_len, seq_len)
raw_weights = torch.bmm(x, x.transpose(1, 2))
# 对原始权重进行 softmax 归一化,形状为 (batch_size, seq_len, seq_len)
attn_weights = F.softmax(raw_weights, dim=2)
# 计算加权和,形状为 (batch_size, seq_len, feature_dim)
attn_outputs = torch.bmm(attn_weights, x)
# 一个形状为 (batch_size, seq_len, feature_dim) 的张量 x
x = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len, feature_dim)
# 定义线性层用于将 x 转换为 Q, K, V 向量
linear_q = torch.nn.Linear(4, 4)
linear_k = torch.nn.Linear(4, 4)
linear_v = torch.nn.Linear(4, 4)
# 通过线性层计算 Q, K, V
Q = linear_q(x) # 形状 (batch_size, seq_len, feature_dim)
K = linear_k(x) # 形状 (batch_size, seq_len, feature_dim)
V = linear_v(x) # 形状 (batch_size, seq_len, feature_dim)
# 计算 Q 和 K 的点积,作为相似度分数 , 也就是自注意力原始权重
raw_weights = torch.bmm(Q, K.transpose(1, 2)) # 形状 (batch_size, seq_len, seq_len)
# 将自注意力原始权重进行缩放
scale_factor = K.size(-1) ** 0.5 # 这里是 4 ** 0.5
scaled_weights = raw_weights / scale_factor # 形状 (batch_size, seq_len, seq_len)
# 对缩放后的权重进行 softmax 归一化,得到注意力权重
attn_weights = F.softmax(scaled_weights, dim=2) # 形状 (batch_size, seq_len, seq_len)
# 将注意力权重应用于 V 向量,计算加权和,得到加权信息
attn_outputs = torch.bmm(attn_weights, V) # 形状 (batch_size, seq_len, feature_dim)
print(" 加权信息 :", attn_outputs)

多头自注意力
多头自注意力(Multi-head Attention)机制是注意力机制的一种扩展,它可以帮助模型从不同的表示子空间捕获输入数据的多种特征。具体而言,多头自注意力在计算注意力权重和输出时,会对Q、K、V向量分别进行多次线性变换,从而获得不同的头( Head),并进行并行计算,如下图所示。
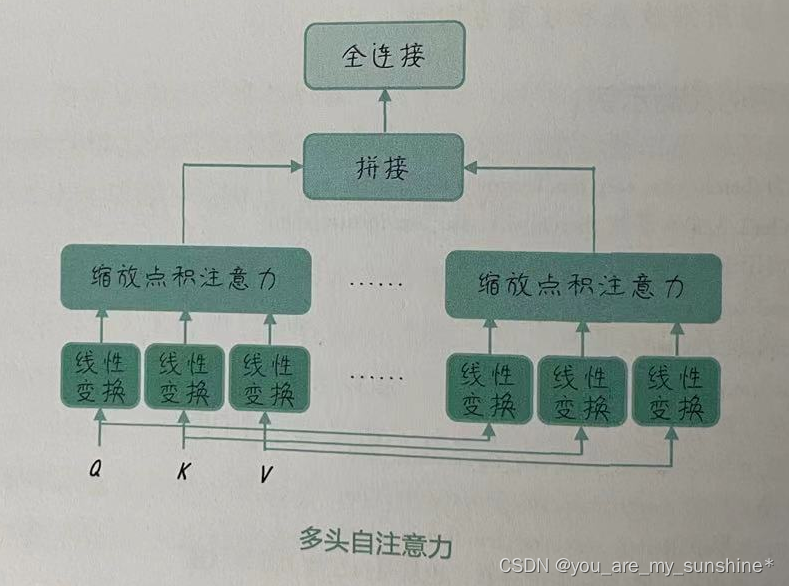
以下是多头自注意力的计算过程。
(1)初始化:设定多头自注意力的头数。每个头将处理输入数据的一个子空间。
(2)线性变换:对 Q、K、V向量进行数次线性变换,每次变换使用不同的权重矩阵。这样,我们可以获得多组不同的Q、K、V向量。
(3)缩放点积注意力:将每组Q、K、V向量输入缩放点积注意力中进行计算,每个头将生成一个加权输出。
(4)合并:将所有头的加权输出拼接起来,并进行一次线性变换,得到多头自注意力的最终输出。
多头自注意力机制的优势在于,通过同时学习多个子空间的特征,可以提高模型捕捉长距离依赖和不同语义层次的能力。
下面是一个简单的实现多头自注意力机制的代码示例。
import torch
import torch.nn.functional as F
# 一个形状为 (batch_size, seq_len, feature_dim) 的张量 x
x = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len, feature_dim)
# 定义头数和每个头的维度
num_heads = 2
head_dim = 2
# feature_dim 必须是 num_heads * head_dim 的整数倍
assert x.size(-1) == num_heads * head_dim
# 定义线性层用于将 x 转换为 Q, K, V 向量
linear_q = torch.nn.Linear(4, 4)
linear_k = torch.nn.Linear(4, 4)
linear_v = torch.nn.Linear(4, 4)
# 通过线性层计算 Q, K, V
Q = linear_q(x) # 形状 (batch_size, seq_len, feature_dim)
K = linear_k(x) # 形状 (batch_size, seq_len, feature_dim)
V = linear_v(x) # 形状 (batch_size, seq_len, feature_dim)
# 将 Q, K, V 分割成 num_heads 个头
def split_heads(tensor, num_heads):
batch_size, seq_len, feature_dim = tensor.size()
head_dim = feature_dim // num_heads
output = tensor.view(batch_size, seq_len, num_heads, head_dim).transpose(1, 2)
return output # 形状 (batch_size, num_heads, seq_len, feature_dim)
Q = split_heads(Q, num_heads) # 形状 (batch_size, num_heads, seq_len, head_dim)
K = split_heads(K, num_heads) # 形状 (batch_size, num_heads, seq_len, head_dim)
V = split_heads(V, num_heads) # 形状 (batch_size, num_heads, seq_len, head_dim)
# 计算 Q 和 K 的点积,作为相似度分数 , 也就是自注意力原始权重
raw_weights = torch.matmul(Q, K.transpose(-2, -1)) # 形状 (batch_size, num_heads, seq_len, seq_len)
# 对自注意力原始权重进行缩放
scale_factor = K.size(-1) ** 0.5
scaled_weights = raw_weights / scale_factor # 形状 (batch_size, num_heads, seq_len, seq_len)
# 对缩放后的权重进行 softmax 归一化,得到注意力权重
attn_weights = F.softmax(scaled_weights, dim=-1) # 形状 (batch_size, num_heads, seq_len, seq_len)
# 将注意力权重应用于 V 向量,计算加权和,得到加权信息
attn_outputs = torch.matmul(attn_weights, V) # 形状 (batch_size, num_heads, seq_len, head_dim)
# 将所有头的结果拼接起来
def combine_heads(tensor):
batch_size, num_heads, seq_len, head_dim = tensor.size()
feature_dim = num_heads * head_dim
output = tensor.transpose(1, 2).contiguous().view(batch_size, seq_len, feature_dim)
return output# 形状 : (batch_size, seq_len, feature_dim)
attn_outputs = combine_heads(attn_outputs) # 形状 (batch_size, seq_len, feature_dim)
# 对拼接后的结果进行线性变换
linear_out = torch.nn.Linear(4, 4)
attn_outputs = linear_out(attn_outputs) # 形状 (batch_size, seq_len, feature_dim)
print(" 加权信息 :", attn_outputs)

注意力掩码
注意力中的掩码机制,不同于 BERT训练过程中的那种对训练文本的“掩码”。注意力掩码的作用是避免模型在计算注意力分数时,将不相关的单词考虑进来。掩码操作可以防止模型学习到不必要的信息。
要直观地解释掩码,我们先回忆一下填充(Padding)的概念。在NLP任务中,我们经常需要将不同长度的文本输入模型。为了能够批量处理这些文本,我们需要将它们填充至相同的长度。
以这段有关损失函数的代码为例。
criterion = nn.CrossEntropyLoss(ignore_index=word2idx_en['<pad>'])# 损失函数
这段代码中的ignore_index=word2idx_en[‘《pad》’],就是为了告诉模型,《pad》 是附加的冗余信息,模型在反向传播更新参数的时候没有必要关注它,因此也没有什么单词会被翻译成《pad》。
填充掩码(Padding Mask)的作用和上面损失函数中的ignore_index参数有点类似,都是避免在计算注意力分数时,将填充位置的单词考虑进来(见右图)。因为填充位置的单词对于实际任务来说是无意义的,而且可能会引入噪声,影响模型的性能。

加入了掩码机制之后的注意力如下图所示,我们会把将注意力权重矩阵与一个注意力掩码矩阵相加,使得不需要的信息所对应的权重变得非常小(接近负无穷)。然后,通过应用 softmax函数,将不需要的信息对应的权重变得接近于0,从而实现忽略它们的目的。
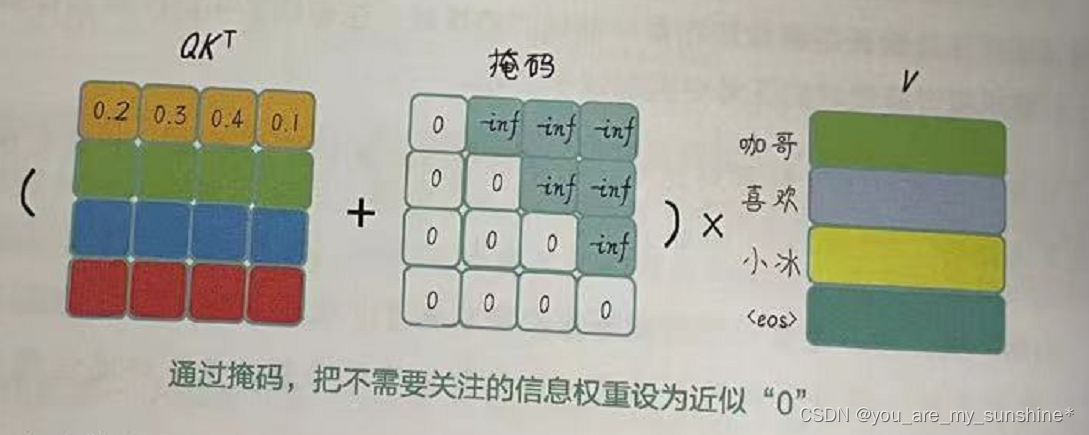
Transformer中,使用了自注意力机制、多头自注意力机制和掩码,不仅有前面介绍的填充掩码,还有一种解码器专用的后续注意力掩码(Subsequent Attention Mask),简称后续掩码,也叫前瞻掩码(Look-ahead Masking ),这是为了在训练时为解码器遮蔽未来的信息。
小结
通过引入注意力机制,模型可以在每个时间步中为输入序列中不同位置的词分配不同的注意力权重。这使得模型能够更加灵活地有选择地关注输入序列中的重要部分,从而更好地捕捉上下文相关性,模型的性能也会因此而提高。
学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
动手学深度学习(pytorch)
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
慕课网
海贼宝藏
…




























![[职场] 如何通过运营面试_1 #笔记#媒体#经验分享](https://img-blog.csdnimg.cn/img_convert/84ff96ce89b437afcc33c058527b4fc4.jpeg)