1. 流式数据倾斜
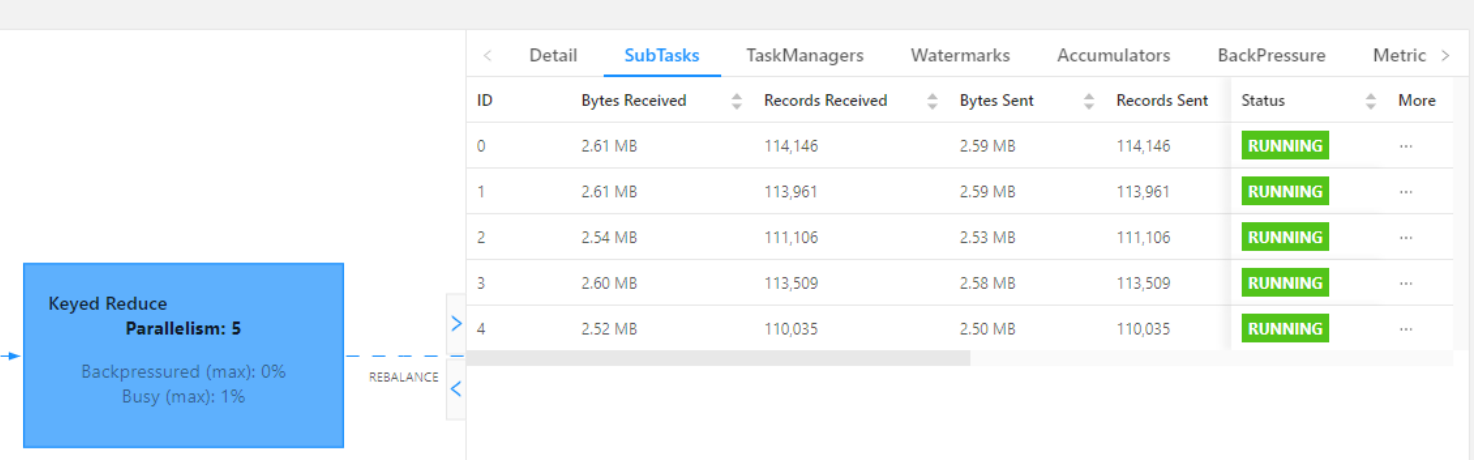
流式处理的数据倾斜和 Spark 的离线或者微批处理都是某一个 SubTask 数据过多这种数据不均匀导致的,但是因为流式处理的特性其中又有些许不同
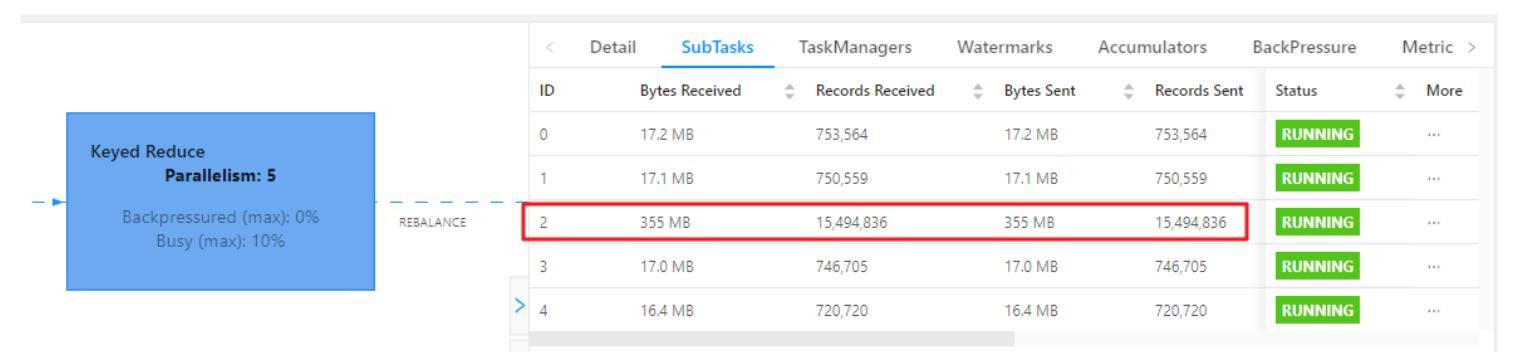
2. 如何解决
2.1 窗口有界流倾斜
窗口操作类似Spark的微批处理,直接两阶段聚合的方式来解决就可以
select date,
type,
sum(pv) as pv
from(
select
date,
type,
sum(count) as pv
from table
group by
date,
type,
floor(rand()*100) --随机打散成100份
)
group by
date,
type;2.2 数据本身不均匀
KeyBy 前数据已经不均匀了,可能是Topic 每个分区的数据不一致(较为少见),或者上游task处理以后导致的数据不均匀,导致下游operate chains的某个task压力很大
这种可以加一个随机数 redistributiing 一下之类打散
2.3 keyby类
加盐
开启minibatch 和 global,牺牲时效性,减少输出数据量