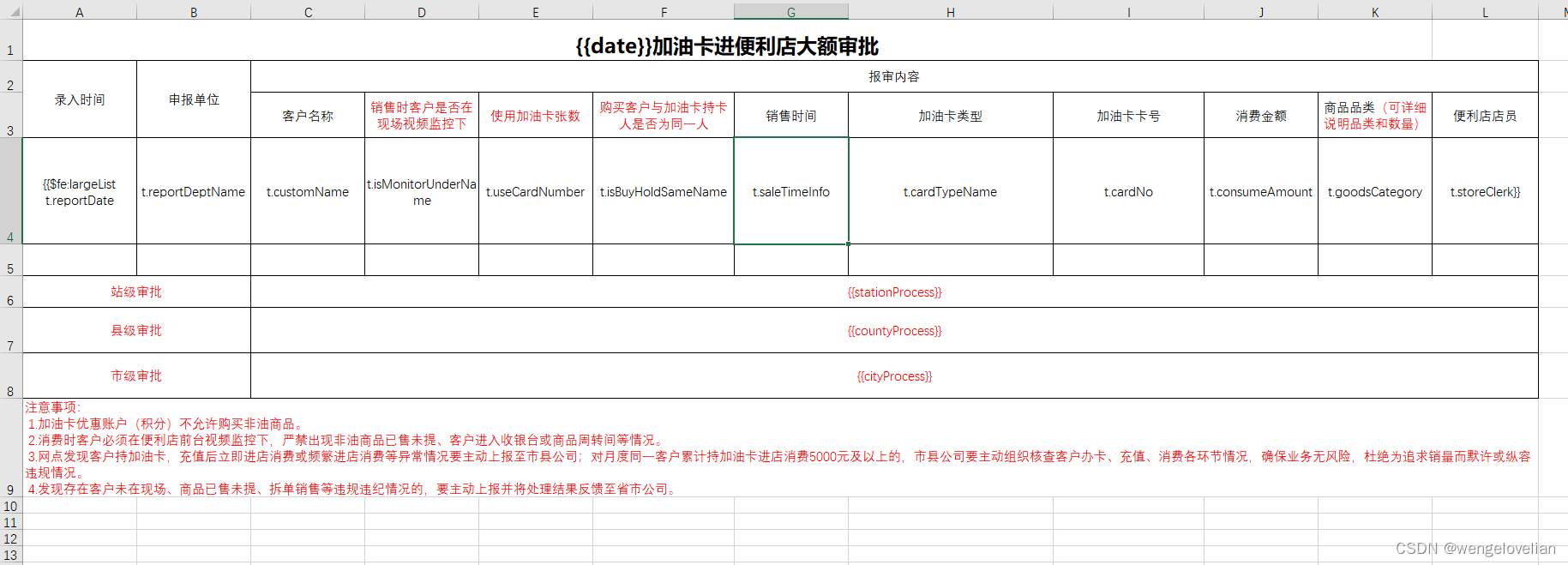
什么是随机森林分类器?
请你先想象一个场景,一个会议室里坐满了来自各个国家的人群,这些人群有着不同的经历,所以都有着不同的见解,现在针对一个分类问题,要让他们进行投票,根据目标对象的特征,投票判断这个目标对象是什么类别。
那这个投票的动作呢,就是分类,这些不同的人群合起来成为的总体就是“森林”。那么为什么叫做森林,不叫作随机人群分类器呢?
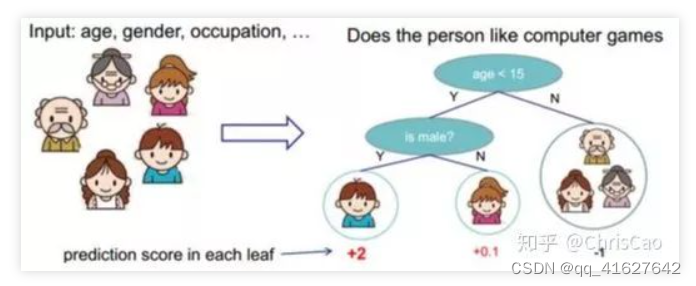
因为有个树状决策结构叫决策树,刚刚例子里的每个人在发起投票之前都要根据自己的经历进行一系列的决策来确定最后的投票行为,所以一个人就是一棵树,一群人就是森林。
所以随机森林分类器到底是怎么学习呢,其实啊,这就是给每颗树一段自己的经历,通过随机抽取数据集中的样本进行学习,之后再把样本放回去,让其他人可以抽取到这个样本进行学习。
这个抽取样本学习的过程需要注意,A抽取了一些样本,之后抽取样本的其他人可能会抽取到A看过的样本,也可能不会抽取到,但一定会有人抽取到A抽取过的样本的,不然和A意见一致的人就没了,别人的投票和A的投票都不一样,那A的投票就没什么影响,甚至可以说没有意义,这也是为什么学习的样本要放回去。
所以一定有一些人会学习到相同的样本,他们的投票最有可能一致(这取决于这些人学习到的其他样本和这些重复的样本有多少区别)。
![[Python] 什么是集成算法,什么是<span style='color:red;'>随机</span><span style='color:red;'>森林</span>?<span style='color:red;'>随机</span><span style='color:red;'>森林</span><span style='color:red;'>分类</span><span style='color:red;'>器</span>(RandomForestClassifier)及其使用案例](https://img-blog.csdnimg.cn/direct/3bb8594f98db400b9e80f4242baf5a5c.png)