一、特征5个坐标
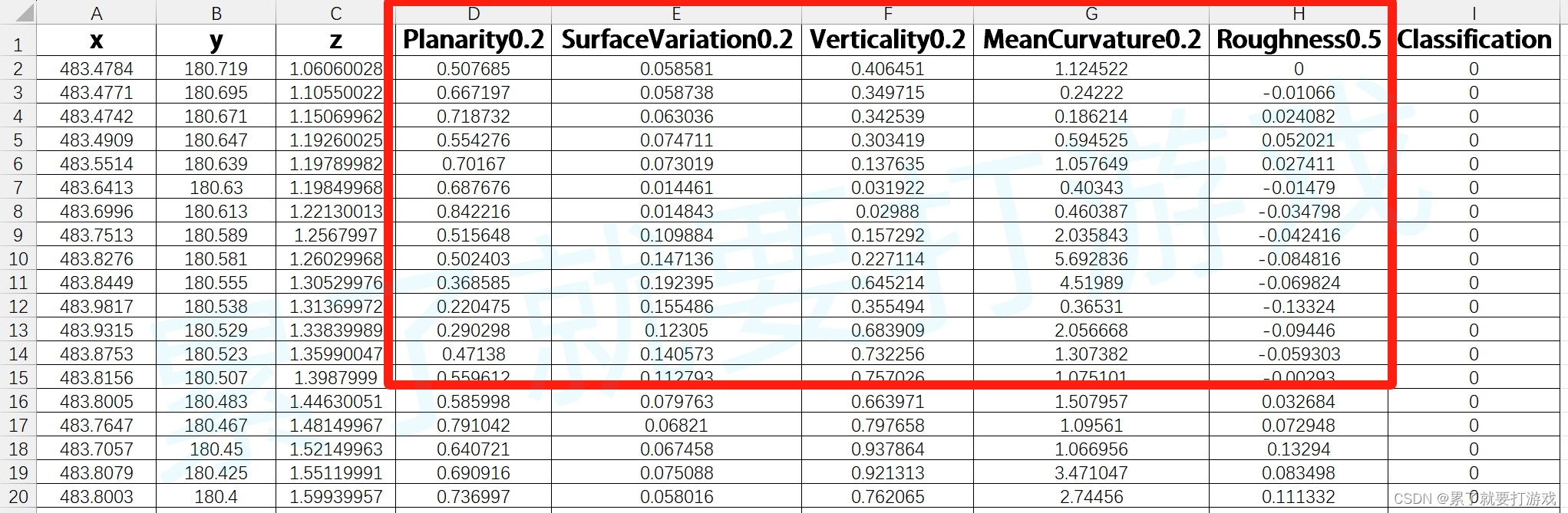
二、模型训练
记录分享给有需要的人,代码质量勿喷
import numpy as np
import pandas as pd
import joblib
#region 1 读取数据
dir = 'D:\\py\\RandomForest\\'
filename1 = 'trainRS'
filename2 = '.csv'
path = dir+filename1+filename2
rawdata = pd.read_csv(path, encoding='gbk')
print('=== 1 读取数据')
#endregion
#region 2 构造数据集
x = rawdata.drop(columns=['x','y','z','Classification'])
y = rawdata['Classification']
#训练集6:验证集4
from sklearn.model_selection import train_test_split
indices = np.arange(x.shape[0]) #索引
x_train,x_test,y_train, y_test, indices_train, indices_test = train_test_split(x,y,indices,test_size=0.4,random_state=0)
print('=== 2 构造训练集和验证集')
#endregion
#region 3 Random Forest 模型训练与保存------------------------最耗时间
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier() #随机森林实例化 默认参数
rfc.fit(x_train, y_train) #模型训练
# 保存模型
joblib.dump(rfc,"modelRS.m")
# rfc2 = joblib.load("modelRS.m") #调用
print('=== 3 Random Forest 模型训练与保存')
#endregion
#region 4 模型评分与验证结果
score_rfc = rfc.score(x_test,y_test)
print('score_rfc =',score_rfc)
#验证集预测
yPre = rfc.predict(x_test)
print('=== 4 模型评分与验证集预测')
#endregion
#region 5 查看特征的重要性占比
feature_importance = rfc.feature_importances_
cols = rawdata.columns
fi = pd.DataFrame({'特征':np.array(cols)[3:-1], '重要性占比':feature_importance}).sort_values(by='重要性占比',axis=0, ascending=False)
print('=== 5 查看特征列的重要性')
print(fi)
#endregion
#region 6 输出验证集结果
test_data = rawdata.loc[indices_test]
test_data_np = test_data.to_numpy()
#合并原始数据和预测结果
test_data_pre = np.hstack((test_data_np, yPre.reshape(-1, 1))) #水平(沿着列方向)合并数组
output_file = filename1 + "_ValidateResult.txt"
np.savetxt(output_file, test_data_pre, fmt="%f", delimiter="\t")
print('=== 6 输出验证集结果')
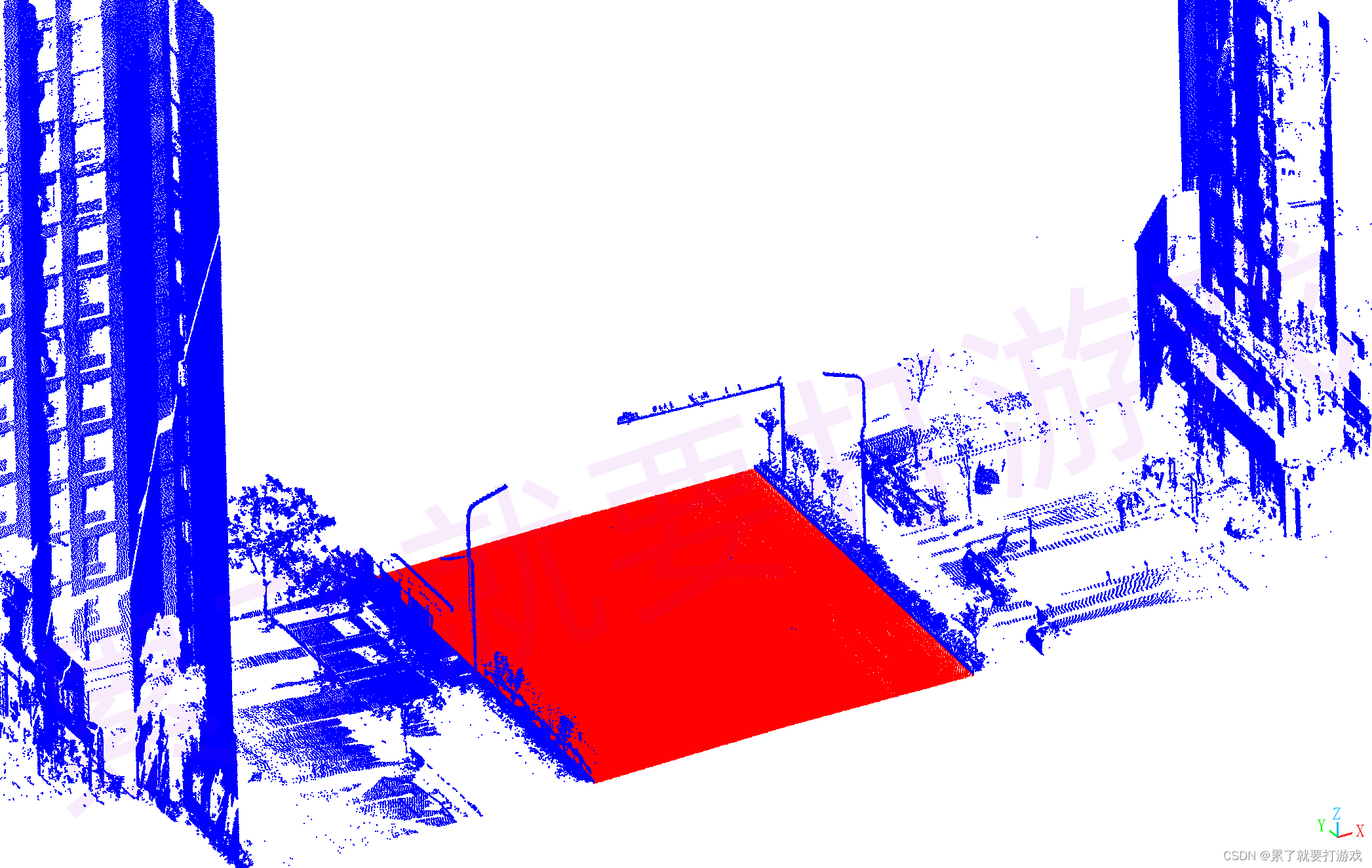
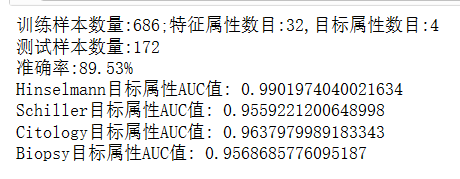
#endregion三、验证集结果
验证集98%,hhhhhhhhh
特征占比有点超乎想象

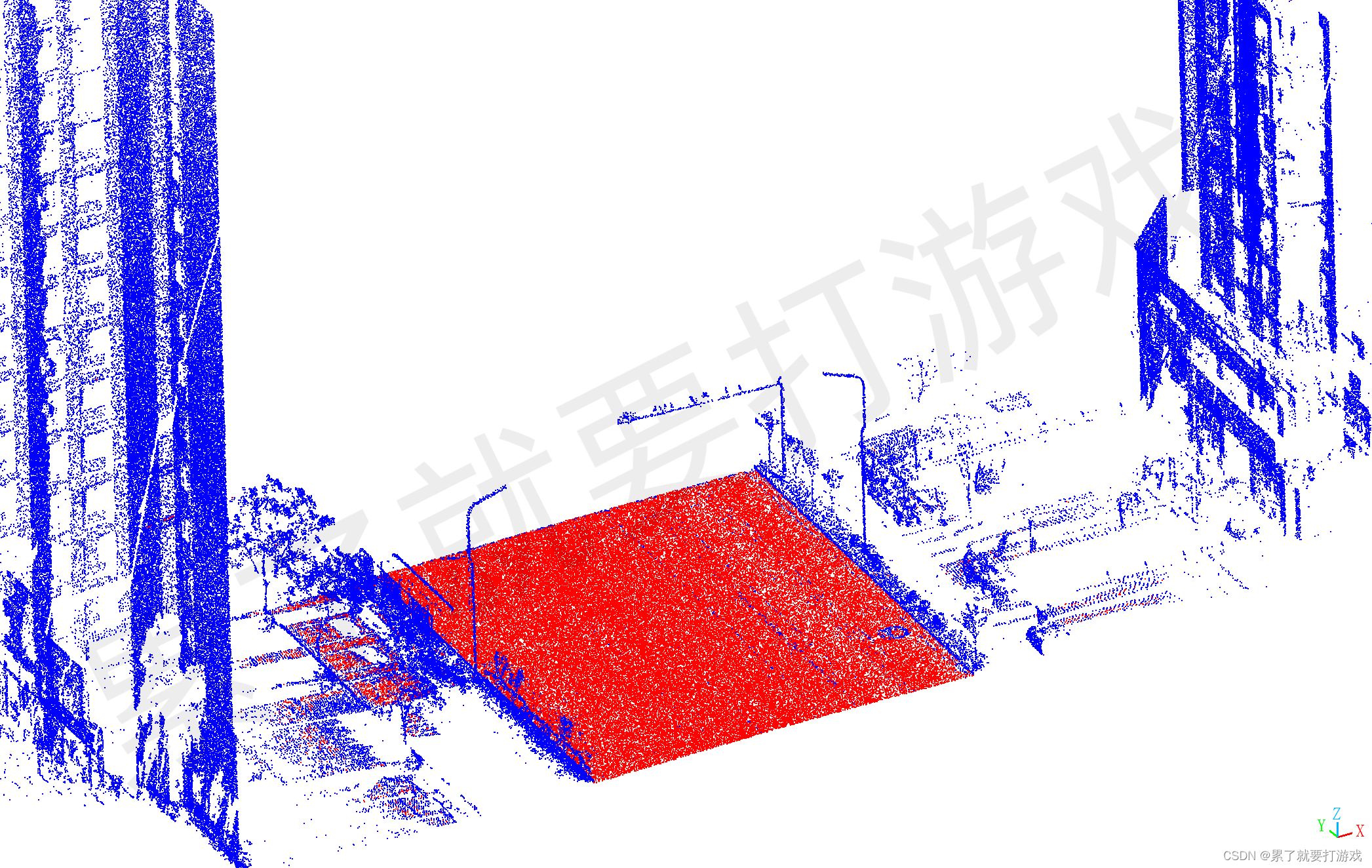
四、测试
记录分享给有需要的人,代码质量勿喷
import numpy as np
import pandas as pd
import joblib
#region 1 读取数据
dir = 'D:\\py\\RandomForest\\'
filename1 = 'testRS2'
filename2 = '.csv'
path = dir+filename1+filename2
data = pd.read_csv(path,encoding='gbk')
test = data.drop(columns=['x','y','z','Classification'])
print('=== 1 读取数据')
#endregion
#region 2 调用模型预测
rfc = joblib.load("modelRS.m") #调用
pre = rfc.predict(test)
print('=== 2 调用模型预测')
#endregion
#region 3 输出结果
data_np = data.to_numpy()
data_pre = np.hstack((data_np, pre.reshape(-1, 1))) #水平(沿着列方向)合并数组
output_file = filename1 + "_PreResult.txt"
np.savetxt(output_file, data_pre, fmt="%f", delimiter="\t")
print('=== 3 输出结果')
#endregion还是有效果的






























![[c]比较月亮大小](https://img-blog.csdnimg.cn/direct/54476faebd3f4efebeeb60460f9a5789.png)