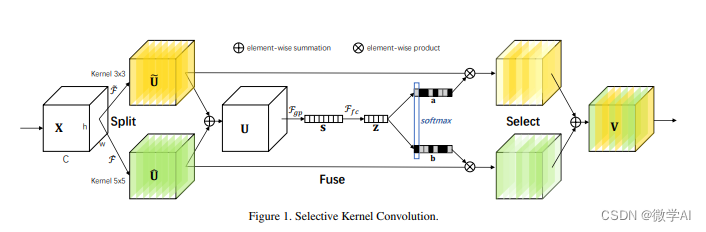
torchaudio 是 PyTorch 深度学习框架的一部分,是 PyTorch 中处理音频信号的库,专门用于处理和分析音频数据。它提供了丰富的音频信号处理工具、特征提取功能以及与深度学习模型结合的接口,使得在 PyTorch 中进行音频相关的机器学习和深度学习任务变得更加便捷。通过使用 torchaudio,开发者能够轻松地将音频数据转换为适合深度学习模型输入的形式,并利用 PyTorch 的高效张量运算和自动梯度功能进行训练和推理。此外,torchaudio 还支持多声道音频处理和GPU加速,以满足不同应用场景的需求。
1. torchaudio其内部构成和组织结构
torchaudio其内部构成和组织结构主要包括以下几个核心部分:
torchaudio.io:
这个模块主要负责音频文件的读写操作,提供load()、save()等函数来加载和保存不同格式(如 WAV、MP3、FLAC 等)的音频文件。torchaudio.functional:
提供了一系列用于音频信号处理和特征提取的底层功能。例如计算短时傅里叶变换 (STFT) 和逆 STFT,梅尔频率谱图 (Mel Spectrogram),MFCCs(梅尔频率倒谱系数),重采样等。torchaudio.transforms:
包含一系列预定义的音频转换类,可以作为数据预处理流水线的一部分。这些转换器能够方便地应用于音频张量上,如 MelSpectrogram、MFCC 以及各类归一化、增强技术等。torchaudio.datasets:
虽然 torchaudio 不直接内置音频数据集,但该模块提供了构建和加载自定义音频数据集的基础框架,用户可以根据需要创建自己的数据加载器。torchaudio.models:
提供了一些预先训练好的模型或者模型组件,用于特定的音频处理任务,比如声学特征提取等。torchaudio.prototype:
试验性的新功能和算法通常会先在这个模块中发布,以便开发者尝试并提供反馈,这些功能未来可能成为稳定版的一部分。其他辅助模块:
torchaudio 还包括一些辅助工具和兼容性模块,例如与 Kaldi ASR 框架相关的接口(如 torchaudio.compliance.kaldi_io)。
总之,torchaudio 的内部结构旨在简化音频数据的加载、预处理、特征提取和模型构建过程,使其无缝集成到 PyTorch 的深度学习工作流程中。
2. torchaudio.functional模块
torchaudio.functional 模块提供了许多用于音频信号处理和特征提取的功能,以下是一些 torchaudio.functional 中的关键功能:
频谱分析:
stft():计算短时傅里叶变换(Short-Time Fourier Transform, STFT),将时域的音频信号转换为频域-时间表示。istft():计算逆短时傅里叶变换(Inverse Short-Time Fourier Transform, iSTFT),从频域-时间表示还原回时域信号。
梅尔频率相关操作:
mel_spectrogram():计算 Mel 频谱图,将音频信号转换为基于 Mel 频率尺度的频谱表示。amplitude_to_db():将功率谱或 Mel 频谱图转换为对数分贝(dB)尺度。
MFCC 计算:
mfcc():计算梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients, MFCCs),这是一种广泛应用于语音识别和其他音频处理任务的声学特征。
其他音频处理函数:
griffinlim():实现 Griffin-Lim 算法,用于从幅度谱重建时域信号。mu_law_encoding()和mu_law_decoding():实现 μ-law 压缩编码和解码,常用于语音压缩和传输。resample():进行重采样操作,改变音频信号的采样率。
增强与预处理:
normalize():标准化音频信号,使其具有零均值和单位方差。- 其他可能的函数包括噪声添加、增益控制等,但请注意 torchaudio 的具体版本和文档以获取最新信息。
总之,torchaudio.functional 包含了一系列底层音频处理函数,这些函数在构建和训练基于音频的深度学习模型时是必不可少的。通过使用这些函数,开发者可以方便地对原始音频数据进行预处理,将其转化为适合神经网络输入的特征表示形式。
3. torchaudio.transforms模块
torchaudio.transforms 是 torchaudio 库中提供的音频转换模块,它包含了多种预定义的音频特征提取和信号处理方法,可以方便地应用于深度学习模型的输入数据预处理。以下是一些常用的 transforms:
MelSpectrogram:
用于将音频信号转换为梅尔频率谱图(Mel Spectrogram),这是一种在语音识别、音乐信息检索等领域广泛应用的音频表示形式。MFCC:
提供了 Mel-Frequency Cepstral Coefficients (MFCCs) 的计算功能,MFCC 是一种从音频信号中提取的人耳对声音感知特性的近似表示。AmplitudeToDB:
将功率谱或梅尔频谱转换为分贝(dB)表示,常用于归一化和稳定音频特征的动态范围。Resample:
对音频信号进行重采样,改变其采样率以适应不同深度学习模型的要求。MuLawEncoding / MuLawDecoding:
实现 A-law 或 μ-law 压缩编码和解码,通常用于降低音频数据的存储空间需求。TimeStretch:
改变音频信号的时间尺度,即加快或减慢音频的速度,但保持音高不变。PitchShift:
调整音频的音调(pitch),同时调整播放速度以保持原始时长。Normalize:
对音频信号进行标准化处理,使其具有零均值和单位方差,有助于优化模型训练过程。
使用这些变换类,用户可以创建一个自定义的数据预处理流水线,从而轻松准备音频数据作为深度学习模型的输入。例如:
Python
1import torchaudio
2
3# 创建 Mel Spectrogram 转换器
4mel_spec = torchaudio.transforms.MelSpectrogram(sample_rate=16000, n_mels=64)
5
6# 加载音频文件
7audio, sample_rate = torchaudio.load('example_audio.wav')
8
9# 计算 Mel Spectrogram
10mel_spectrogram = mel_spec(audio)
11
12# 其他变换操作...通过这种方式,torchaudio.transforms 提供了一个简洁且统一的接口来处理各种音频预处理任务,并与 PyTorch 生态系统紧密结合,使得音频相关的深度学习研究更加便捷高效。
4. torchaudio.models
torchaudio.models 是 torchaudio 库中用于提供预训练音频处理模型的部分。尽管目前 torchaudio.models 模块提供的功能相对有限,但随着库的发展,可能会增加更多预训练模型。以下是一些可能存在的模型或组件:
声学特征提取器(Acoustic Feature Extractors):
在某些版本的 torchaudio 中,可能存在预定义的声学特征提取器,如 MFCC(梅尔频率倒谱系数)提取器,这类模型通常用来将原始音频数据转换为深度学习模型可以使用的特征向量。语音识别相关模型(Speech Recognition Models):
虽然torchaudio.models目前并未直接提供完整的预训练语音识别模型,但可能会包含部分模型组件,例如基于 LSTM 或 Transformer 的声学模型架构的基础构建模块。文本转语音(Text-to-Speech, TTS)模型组件:
可能会有一些 TTS 模型相关的基础层和组件,如 Tacotron 系列模型的一部分结构,或者 Mel-spectrogram 预测网络等。声音事件检测(Sound Event Detection, SED)模型:
未来可能会支持预训练的声音事件检测模型,这些模型能够从音频片段中识别特定的声音事件。
请注意,上述内容是基于对 torchaudio 功能发展的推测和理解,并非当前最新版 torchaudio 的准确描述。实际使用时,请查阅官方文档以获取最新的模块支持信息。
5. 支持的音频数据集
torchaudio 不直接提供音频数据集,但它支持与常见的音频数据集集成,并提供了方便的接口来加载这些数据。以下是一些 torchaudio 可能会用到或官方文档中提到的音频数据集:
LibriSpeech:
- LibriSpeech 是一个大规模英语阅读语音数据集,包含大约 1000 小时的有声读物朗读内容,由 LibriVox 项目中的公开领域有声读物制作而成。
- 虽然 torchaudio 没有内置对 LibriSpeech 的加载器,但可以使用
torch.utils.data.Dataset和其子类自定义数据集加载方式,或者结合其他库(如datasets库)来加载 LibriSpeech。
VCTK:
- VCTK (Voice Cloning Toolkit) 是一个包含超过 100 名不同说话者的英语口语数据集,每个说话者都朗读了多篇文本,用于语音合成和说话人识别的研究。
- 类似于 LibriSpeech,torchaudio 并没有直接内建 VCTK 加载器,但是可以通过类似的自定义方法或第三方库加载该数据集。
LJSpeech:
- LJSpeech 是一个单个女性说话人的英文朗读数据集,包含约 24 小时的录音,通常用于端到端的文本转语音(TTS)系统训练。
- 使用 torchaudio 加载 LJSpeech 数据集同样需要自定义数据加载逻辑。
在实际应用中,用户可以编写脚本来下载、解压和预处理这些数据集,然后将其转换为适合 torchaudio 处理的张量格式。同时,社区中存在许多基于 PyTorch 或 torchaudio 的开源项目,它们可能已经实现了针对特定数据集的加载器和预处理步骤,可以作为参考或直接使用。