原文地址: https://debezium.io/blog/2021/09/16/debezium-1-7-cr1-released/
欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯.
Debezium 1.7.0.CR1 Released
September 16, 2021 by Gunnar Morling
releases mysql postgres sqlserver oracle outbox
我很高兴地宣布 1.7.0.CR1 !
在这个版本中,我们重新设计了在快照处理过程中如何处理列过滤器,对Debezum容器图像进行了更新,以使用Fedura34作为它们的基础,对mysql的支持INVISIBLE 柱,还有更多。
截图过程中的柱滤波
虽然不同的Debezu连接器已经有能力将捕获的表的特定列排除在更改事件之外,但这些过滤器只在连接器中处理数据时才应用。对于初始快照,现在已经实现了一种更有效的方法:将执行定制的SQL选择语句,只获取实际包含的列( DBZ-2525 )。这使业绩显著提高,例如排除了较大的业绩。BLOB 变化事件的列。
更新容器图像库
… 德贝兹容器图像 对于阿帕奇卡夫卡、卡夫卡连接和阿帕奇动物园管理员来说,他们是基于Fedura34最小容器底座图像( DBZ-3939 )。由于不再维持以前使用的基图(来源于中心7),这一改变变得很有必要。虽然这一变化对大多数Debez铵用户来说是透明的,但对于那些从Debez铵中获得自己自定义图像的用户来说,可能需要作出一些调整,例如。使用操作系统的包管理器安装进一步的包。请参阅 释放说明 更多的细节。
进一步的修正
当我们接近1.7的最终版本时,大多数的更改都集中在修复错误和使代码基础成熟上。一些已解决的问题包括:
支持INVISIBLE 自mysql8.0.23( DBZ-3623 );我们也使用了这个八度来更新mysql的Debezum示例图像到8.0版本( DBZ-3936 )
SQL服务器允许使用自定义连接工厂( DBZ-4001 )
对DML和DDL的mysql分析的几个修复( DBZ-3969 , DBZ-3984 )及甲骨文( DBZ-3892 , DBZ-3962 )
一起来, 47个问题 已经为这个版本做好了准备。非常感谢所有投稿人: 阿尼莎 , 兰巴 , 鲍勃·罗丹 , 卡米尔歌曲 , 克兰福德 , Dhrubajyoti , 贡纳·莫林 , , 侯赛因·安萨里 , 因德拉舒克拉 , 杰克布切切克 , , 伊日诺沃特尼 , 伊里·帕坎奇c , 卡特琳娜·加里耶娃 , 勒内·克纳 ,以及 张元 .
展望未来,我们计划在几天内再做一次CR(候选版本)发布,随后是在月底完成1.7.7.0.最后的发布。我们将主要关注的是错误修复和一些特定的性能优化。同时也会有一些令人兴奋的改进 去贝兹界面 ,它应该包含在1.7最终版本中:支持单消息转换(SMTS)的配置,以及配置主题创建设置的能力。
与此同时,我们正在制定Debezum1.8的路线图,计划在今年年底发布。请在下面的评论或 邮寄清单 如果您想为这个版本提出特定的特性请求。
原文地址: https://debezium.io/blog/2021/09/22/deep-dive-into-a-debezium-community-connector-scylla-cdc-source-connector/
我们开发了一个高性能的Nosql数据库 水仙 与阿帕奇卡珊德拉、亚马逊发电机和雷迪斯兼容。今年早些时候,我们开始支持 更改数据采集 在"Scylla4.3"里。这个新功能似乎是阿帕奇卡夫卡生态系统的完美结合,所以我们开发了 疾病预防控制中心源连接器 使用德贝兹框架。在这篇博客中,我们将介绍"Scylla"CDC的基本结构,我们选择"Debezum"框架的原因,以及我们做出的设计决定。
CDC对"Scylla"的支持
更改数据捕获(cds)使用户可以追踪他们的""""数据库中的数据修改。它可以很容易地在任何"Scylla"表上启用/禁用。打开它后,将创建所有修改(插入、更新、删除)的日志并自动更新。
当我们设计在"Scylla"中实施CDC时,我们希望能够更容易地使用CDC的日志。因此,疾病预防控制中心的日志存储为常规的Scyl表,任何现有的CQL驱动程序都可以访问。当对启用了疾病预防控制中心的表进行修改时,有关操作的信息将保存到疾病预防中心的日志表中。
下面是它的一个简单演示:首先,我们将创建一个能够使用疾病预防控制中心的表格:
CREATE TABLE ks.orders(
user text,
order_id int,
order_name text,
PRIMARY KEY(user, order_id)
) WITH cdc = {‘enabled’: true};
接下来,让我们执行一些操作:
INSERT INTO ks.orders(user, order_id, order_name)
VALUES (‘Tim’, 1, ‘apple’);
INSERT INTO ks.orders(user, order_id, order_name)
VALUES (‘Alice’, 2, ‘blueberries’);
UPDATE ks.orders
SET order_name = ‘pineapple’
WHERE user = ‘Tim’ AND order_id = 1;
最后,让我们看看修改后的表的内容:
SELECT * FROM ks.orders;
user | order_id | order_name
------±---------±------------
Tim | 1 | pineapple
Alice | 2 | blueberries
仅看此表,您无法重构发生的所有修改。更新前蒂姆的订单名。让我们看一下疾病预防控制中心的日志,它可以很容易地作为一个表(为了清楚起见,有些列被截断了):
SELECT * FROM ks.orders_scylla_cdc_log;
cdc s t r e a m i d ∣ c d c stream_id | cdc streamid∣cdctime | | cdc o p e r a t i o n ∣ o r d e r i d ∣ o r d e r n a m e ∣ u s e r − − − − − − − − − − − − − − − + − − − − − − − − − − + − . . . − + − − − − − − − − − − − − − − − + − − − − − − − − − − + − − − − − − − − − − − − − + − − − − − − − − − − 0 x 2 e 46 a . . . ∣ 7604... ∣ . . . ∣ 2 ∣ 1 ∣ a p p l e ∣ T i m 0 x 2 e 46 a . . . ∣ 8 f d c . . . ∣ . . . ∣ 1 ∣ 1 ∣ p i n e a p p l e ∣ T i m 0 x 41400... ∣ 808 e . . . ∣ . . . ∣ 2 ∣ 2 ∣ b l u e b e r r i e s ∣ A l i c e 在 疾 病 预 防 控 制 中 心 的 日 志 中 可 以 看 到 这 三 种 操 作 。 有 两 个 插 入 ( c d c operation | order_id | order_name | user ---------------+----------+-...-+---------------+----------+-------------+---------- 0x2e46a... | 7604... | ... | 2 | 1 | apple | Tim 0x2e46a... | 8fdc... | ... | 1 | 1 | pineapple | Tim 0x41400... | 808e... | ... | 2 | 2 | blueberries | Alice 在疾病预防控制中心的日志中可以看到这三种操作。有两个插入(cdc operation∣orderid∣ordername∣user−−−−−−−−−−−−−−−+−−−−−−−−−−+−...−+−−−−−−−−−−−−−−−+−−−−−−−−−−+−−−−−−−−−−−−−+−−−−−−−−−−0x2e46a...∣7604...∣...∣2∣1∣apple∣Tim0x2e46a...∣8fdc...∣...∣1∣1∣pineapple∣Tim0x41400...∣808e...∣...∣2∣2∣blueberries∣Alice在疾病预防控制中心的日志中可以看到这三种操作。有两个插入(cdcoperation = 2 )及一次更新(cdc o p e r a t i o n = 1 ) 。 对 于 每 个 操 作 , 其 时 间 戳 也 保 存 在 c d c operation = 1 )。对于每个操作,其时间戳也保存在cdc operation=1)。对于每个操作,其时间戳也保存在cdctime 圆柱。时间戳编码为基于时间的UUID值,由 RFC4122 说明书,可以使用""""""驱动程序中的辅助方法进行解码。
选择去贝兹
如前一部分所示,可以很容易地作为一个常规表查询"Scylla"CDC。为了获得最新的实时操作,您可以用适当的时间范围对表进行轮询。为了方便起见,我们开发了客户机库 爪哇河 和 前进 .
当我们考虑到我们的客户如何能够访问cdf日志时,使用它和卡夫卡看起来是最容易使用的方法。因此,我们决定开发一个来源连接器为"Scylla"CDC。
对于我们的第一个验证概念,我们使用 卡夫卡连接API .这个原型对我们确定连接器是否可以横向扩展至关重要(稍后在本博客中描述)。
然而,我们很快意识到,如果只使用卡夫卡连接API,我们将不得不重新实现其他连接器中已经存在的许多功能。我们也希望我们的连接器成为一个良好的卡夫卡社区公民,坚持最佳做法和惯例。这就是为什么我们选择德贝兹!
有鉴于此,当您启动"Scyc"源连接器时,配置参数马上就会熟悉,因为其中许多参数与其他德贝兹连接器相同。生成的数据更改事件有相同的 信封 其他德贝兹接头产生的结构。这种相似性允许使用很多标准的德贝兹特性,例如: 新记录状态提取 .
事件陈述
在我们决定使用德贝佐姆框架之后,我们研究了""""CDC的业务应该如何以德贝佐姆的信封格式来表示。
信封格式包括以下方面:
op -业务类型:c 为了创造,u 为了更新,d 删除和删除r 供阅读
before-事件发生前的行状态
after-事件发生后的行状态
source-活动的元数据
ts_ms-连接器处理事件的时间
把"Scylla"的行动映射到op 场地很容易:c 插入时,u 为了更新,d 删除。
我们决定删除跨多个行的事件,例如范围删除:
DELETE FROM ks.table
WHERE pk = 1 AND ck > 0 AND ck < 5
代表此类业务将使格式不必要地复杂化,以容纳额外的范围信息。此外,它还会打破人们对信封代表对一行的修改的期望。
在ScyllaCDC"中,范围删除在"CDC"表中表示为两行:第一行编码关于删除范围开始的信息(在上面的例子中:pk = 1, ck > 0 )和第二行编码删除范围的末尾(在上面的例子中:pk = 1, ck < 5 )。关于该范围中存在的每个行的信息不会持久化。这相当于一个事实,在"Scylla"中删除会在数据库中生成一个墓碑。
在默认情况下,"Scylla"的CDC只存储一个操作的主键和修改过的列。例如,假设我创建了一个表并插入了一行:
CREATE TABLE ks.example(
pk int,
v1 int,
v2 int,
v3 int,
PRIMARY KEY(pk)) WITH cdc = {‘enabled’: true};
INSERT INTO ks.example(pk, v1, v2, v3)
VALUES (1, 2, 3, 4);
你可以发布另一个插入语句,它将覆盖一些列:
INSERT INTO ks.example(pk, v1, v3)
VALUES (1, 20, null);
…v2 在此查询之后,列保持不变,我们没有关于其先前值的任何信息。
我们必须能够表示三种可能性:一个列没有修改,一个列被指定为NULL 给值或列指定了一个非NULL值。我们选择的代表受到了 卡珊德拉德贝兹接头 ,其工作方法是将列的值包装在一个结构中:
“v1”: {“value”: 1},
“v2”: null,
“v3”: {“value”: null}
Anull 结构值表示列未被修改(v2 )。如果列被指定为NULL 价值(v3 ),将会有一个结构NULL value 场地。一个非新的列分配(v1 填妥)value 场地。这种格式使我们能够正确地表示所有的可能性并区分分配NULL 以及不修改。
然而,大多数汇连接器无法正确解析这样的结构。因此,我们决定发展我们自己的SMT,基于德贝齐斯的 新记录状态提取 .我们的 ScyllaExtractNewState SMT的工作原理是应用德贝兹的新记录状态提取{“value”: …} 结构(以无法辨别为代价)NULL 值和缺列值):
“v1”: 1,
“v2”: null,
“v3”: null
"Scylla"的CDC也支持记录每一个操作的前和后的图像(增加成本)。我们计划在未来版本的"Scylla"CDC源连接器中增加对它们的支持。
水平尺度
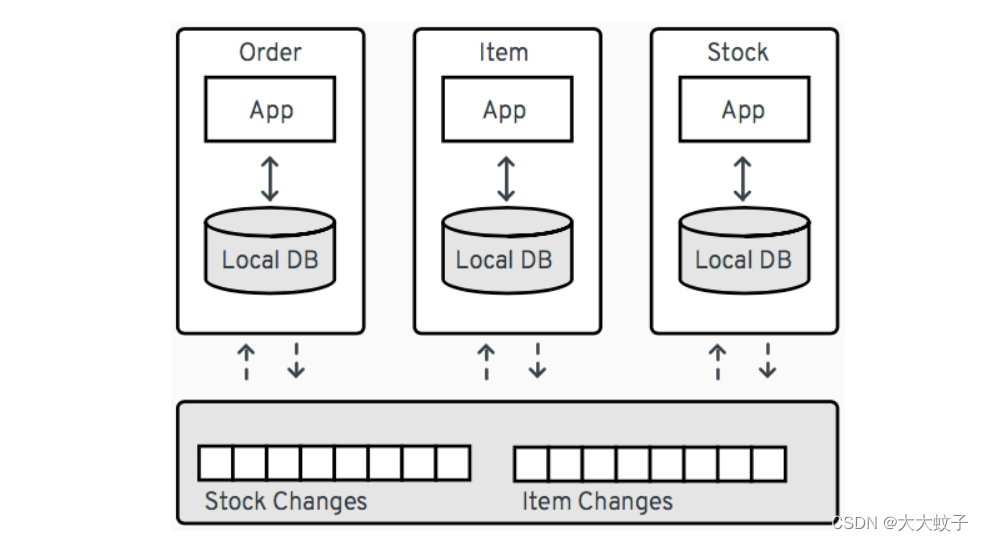
即使在概念验证阶段,出色的表现也是最重要的要求。Scylla数据库可以扩展到数百个节点和PBS数据,因此很明显,一个卡夫卡连接工作节点(甚至多线程)无法处理大的Scylla集群的负载。
谢天谢地,我们在实施"Scylla"CDC的功能时考虑到了这一点。一般来说,您可以将更改数据捕获看作是更改的时间顺序队列。为了允许横向扩展,"Scylla"维护了一组被称为流的多个变化的时间顺序队列。如果只有一个消费者使用cdf日志,它就必须查询所有流,以便正确读取所有更改。这种设计的一个好处是,您可以引入额外的消费者,为每个消费者分配一个分离流集。因此,您可以大大增加处理的计算机控制中心日志的并行性。
这就是我们在"Scylla"CDC源连接器中实现的方法。启动时,连接器首先读取所有可用流的标识符。其次,它将它们分布在许多卡夫卡连接任务中(可通过tasks.max ).
每个创建的卡夫卡连接任务(可以在一个单独的卡夫卡连接节点上运行)都从其分配的流集中读取cdf的更改。如果任务数量增加一倍,每个任务只需要读取流数量的一半,即数据吞吐量的一半,这样就有可能处理更高的负载。
解决大型河流清点问题
在设计"Scylla"中的CDC功能时,我们不得不仔细挑选将要创建的流的数量。如果我们选择太少的流,那么使用者可能无法跟上单个流的数据吞吐量。这也会减缓插入、更新和删除操作的速度,因为许多并发操作将会为访问单个流而斗争。然而,如果"Scylla"创建了太多的流,那么消费者就不得不对"Scylla"(覆盖每个流)发布大量的查询,从而造成不必要的负载。
在"Scylla"控制中心的实施过程中number_of_nodes * number_of_vnodes_per_node * number_of_shards 每个集群的流量。虚拟节点的数量是指"Scyla"使用的是 环结构 ,每个节点默认有256个V节点。每个"Scyla"节点由几个独立的碎片组成,其中包含它们在节点总数据中的份额。通常,每个超线程或物理核心都有一个碎片。
例如,如果您创建一个4节点I3.金属(每个节点72个VCSP)的"Scyla"集群,每秒大约可以运行600K操作(一半插入,一半选择),这将是:4 * 256 * 72 = 73728 流。
我们很快意识到,在更大的集群中,这些流可能是一个问题:
对于"Scyla"来说,太多的查询–每个流一个查询
太多卡夫卡连接补偿-每个流一个偏移。存储补偿意味着连接器可以从崩溃后的最后保存位置恢复。
为了缓解这些问题,我们决定对客户端的流进行分组。我们选择了按V节点对流进行分组。从这个数字减少到number_of_nodes * number_of_vnodes_per_node * number_of_shards 到number_of_nodes * number_of_vnodes_per_node .在4节点I的情况下,金属意味着从73728减少到1024:仅1024次查询"Scyla"和1024次抵消存储在卡夫卡上。
然而,我们仍然对存储在卡夫卡上的补偿数量感到不安。当我们查看其他连接器时,大多数连接器只存储一个偏移量,或每个复制表最多存储几十个偏移量(作为一个可伸缩性有限的效果)。
要理解为什么在卡夫卡连接上存储成千上万条流可能是一个问题,让我们看看它在引擎盖下是如何工作的。源连接器创建的每个卡夫卡连接记录都包含一个键/值偏移,例如:键-my_table ; offset -25 ,这表示连接器在my_table .定期(由offset.flush.interval.ms ),这些补偿变成了一个叫做卡夫卡的话题connect-offsets ,像卡夫卡一样。
不幸的是,卡夫卡不是一个钥匙/价值存储库。当连接器启动时,它必须扫描在connect-offsets 去找它需要的人。当它更新先前保存的偏移量时,它只需将新值追加到此主题,而不删除先前的条目。对于只有一个偏移量的连接器来说,这并不是问题–当每分钟更新一次时,这个主题一周后大约会容纳10,000条消息。然而,在Scycda源连接器的情况下,这个数字可能是几个数量级更大!
幸运的是,这个问题可以很容易地通过在connect-offsets 专题。使用默认配置retention.ms 7天和7天segment.bytes 在1GB的范围内,这个话题在仅仅几个小时之后就会发展到几百兆字节(使用一个有几十个节点和非常小的Scyrala集群)。offset.flush.interval.ms )。这使得连接器启动时间变慢,因为它必须在启动/重新启动后扫描整个偏移主题。通过调整segment.bytes ,segment.ms 或cleanup.policy ,retention.ms 我们缓解了这个问题,大大减少了connect-offsets主题尺寸。前两个选项指定日志压缩过程的频率。当一个段被压缩时,所有使用相同键的消息都将减少到最新的消息(最新的偏移量)。另外,设置一个较短的保留时间(但一个比"Scyla"控制中心的保留时间更长)被证明是减少偏移主题尺寸的一个好选择。
基准:接近线性尺度
为了验证我们的连接器实际上能够水平地扩展,我们执行了一个基准来测量在越来越大的卡夫卡连接集群上的"Scyla"CDC源连接器的最大吞吐量。
首先,我们启动了一个单节点I3.4倍的"Scyla"集群(以""""官方"为基础)。接下来,我们将5,000万行(总尺寸为5,33GB)插入到启用CDC的表中。稍后,我们启动了阿帕奇卡夫卡2.6.0集群和卡夫卡连接集群,它们位于1、3或5个节点(R5N.2x)上。我们启动了"Scyrac"CDC的源连接器,以使用先前填充的CDC启用表中的数据,并测量了生成所有5000万卡夫卡信息所花费的时间。
我们的连接器能够将吞吐量按线性的比例增加:
图片来自官网原文
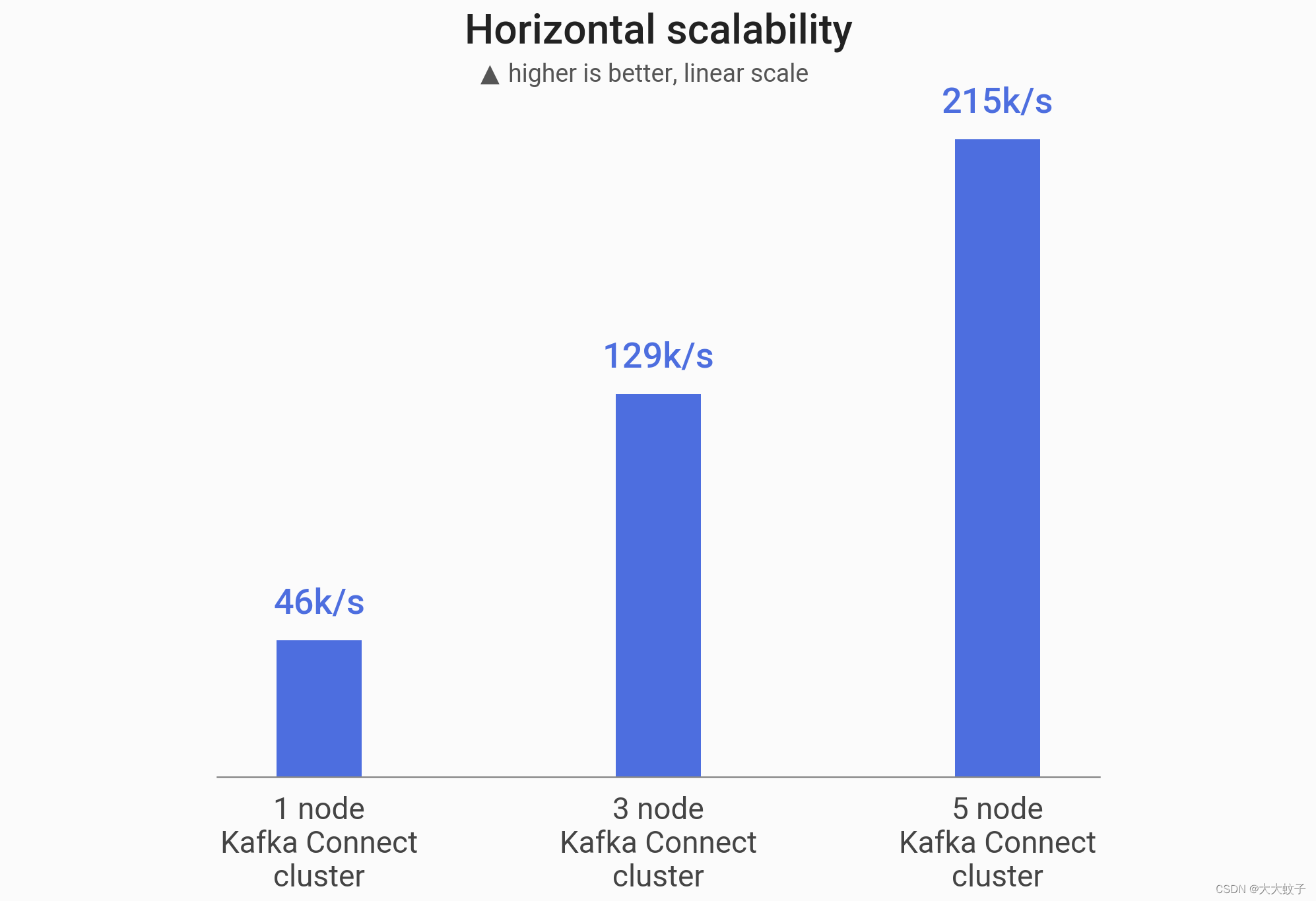
卡夫卡集群大小 产量 加速
1个节点
46k/s
1x
3个节点
129k/s
2.8x
5个节点
215k/s
4.7x
结论
在这篇博文中,我们深入研究了"Scylla"CDC源连接器的开发。我们首先概述了在"Scylla"实施CDC的情况。我们讨论了我们选择Debezum而不仅仅是卡夫卡连接API来构建连接器的原因,这反过来又让用户和卡夫卡习以为常。接下来,我们研究了我们遇到的两个问题:如何表示""""更改并使连接器具有可伸缩性。
我们非常兴奋地继续改进我们的连接器,使其具有更多的性能。我们热切地期待着看到德贝兹生态系统的发展,以及最新版本的德贝兹的集成功能。
如果您想自己查看连接器,则在这里可以使用带源代码的github存储库: 信息来源连接器 .你可以在这里了解更多关于"Scylla"的信息: 网站 .