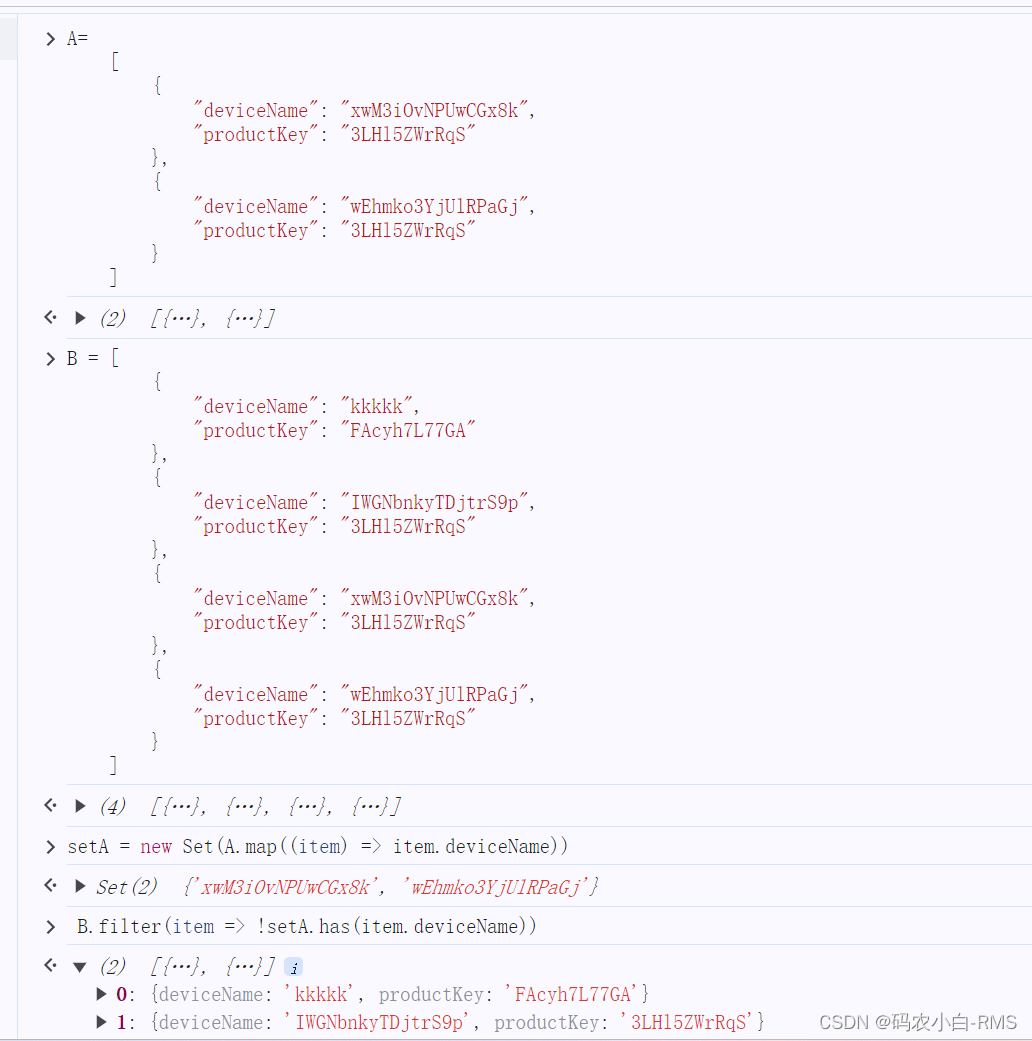
library(dplyr)
data <- metadata %>%
group_by(type) %>% # 根据你要筛选的列进行分组
filter(duplicated(type)|n()!=1) %>% # 将该列中有重复的行挑选出来
ungroup()方法二
# 示例向量
x <- c(1, 2, 3, 2, 4, 5, 5, 6)
# 找出所有重复的元素(包括第一次出现的)
duplicates <- duplicated(x) | duplicated(x, fromLast = TRUE)
# 提取所有重复的元素
duplicated_elements <- x[duplicates]
# 打印结果
print(duplicated_elements)
duplicated(x)会标记向量x中从左至右检查时的重复元素(不包括它们第一次出现的位置)。duplicated(x, fromLast = TRUE)会从向量的末尾开始检查重复元素,这样可以确保即使是第一次出现的元素,只要它在向量中再次出现,也会被标记为TRUE。- 使用
|运算符结合以上两个条件,我们就能得到一个逻辑向量,该向量对于所有重复出现的元素(包括它们第一次出现的位置)为TRUE。- 最后,使用这个逻辑向量作为索引,我们可以从原始向量中提取所有重复的元素。
这种方法能够有效地找出并提取向量中所有重复的元素,包括它们第一次出现的位置。