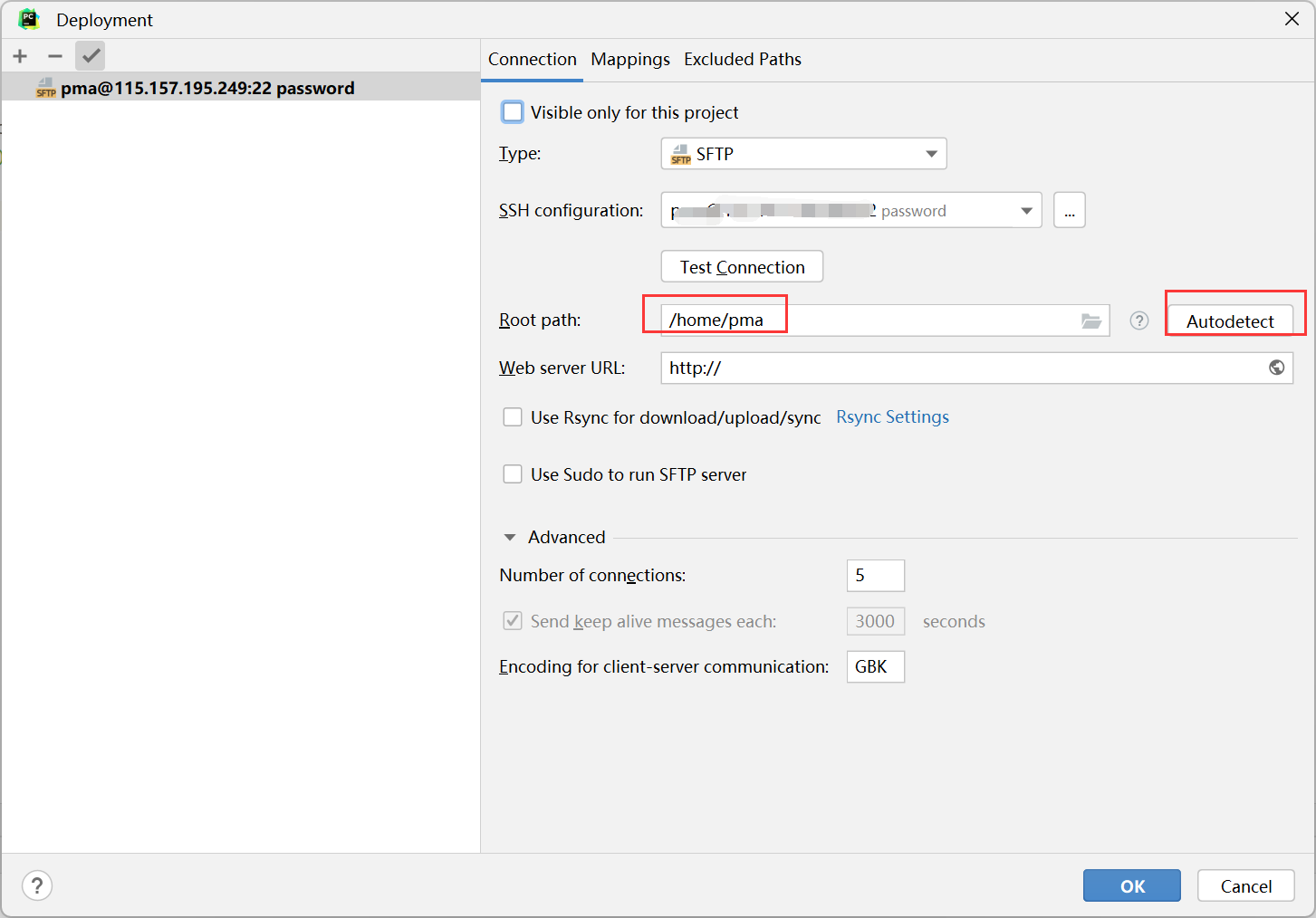
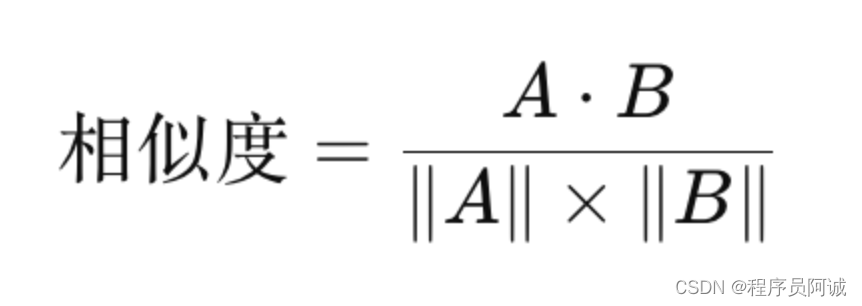协同过滤算法的基本原理
- 关于协同过滤算法,我看过很多老师写的博客以及一些简单的教程,我这里自己也总结了一些(建议大家去阅读王喆老师的深度学习推荐系统)。对于简单的推荐业务,协同过滤算法是必不可少的,也是新人学习推荐算法里绕不开的一个经典之作。
- 协同过滤的核心思想就是对用户历史行为进行处理和挖掘,从而找到用户的喜好,并通过用户所喜好的内容进行召回、推荐(类似于猜你喜欢,购买相同商品的人又购买了哪些,听过相同音乐的人还喜欢听哪些)。
协同过滤算法的分类
- 协同过滤算法可以大致分为两种类型:
- 基于邻域的协同过滤算法
- 基于用户的协同过滤算法(UserCF)
- 基于内容的协同过滤算法(ItemCF)
- 基于模型的协同过滤算法
- 基于矩阵分解算法
- 基于图模型算法
- 基于邻域的协同过滤算法
用户相似度计算
用户相似度计算就是在共现矩阵中,每个用户对应的行向量其实就可以当作一个用户的 Embedding向量,然后对这些Embedding进行相似度计算。用户相似度计算是最关键的步骤,在我推荐算法一栏中也介绍了几种用户相似度计算得算法以及相关代码。这里我就简单总结一下几个常用的。
- 欧氏距离
- 余弦相似度
- 修正余弦相似度
- 皮尔逊相关系数
- Jaccard相似系数
当然业界还有一些升级之后的用户相似度计算的算法阿里的WBcosine(协同过滤etrec),Swing等,这里就不做过多的介绍了。
UserCF && ItemCF
基于用户的协同过滤(User-Based Collaborative Filtering)通过分析用户之间的相似性来实现推荐。简单来说,就是根据用户的历史行为(比如浏览、购买、评分等)来找到与其兴趣相似的其他用户,然后向该用户推荐这些相似用户喜欢的商品或内容。
Q:UserCF真的就那么好用吗?
A:1.其实在典型的互联网电商环境下,往往用户数远大于物品书,而再最后计算Topn的相似用户,对于该用户的相似矩阵存储开销就会非常巨大,而随着时间的推移与业务量的发展,用户相似矩阵的以n^2的形式增长。
2. 对于用户历史数据往往向量是比较稀疏,简单的说就是用户点击和购买次数非常少,找到相似用户的准确度是比较低的,同样也不适用于UserCF。基于内容的协同过滤(Item-Based Collaborative Filtering)与基于用户的协同过滤类似,但是其推荐的对象不是与目标用户相似的其他用户,而是与该用户曾经感兴趣的内容相似的其他内容。
应用场景
- UserCF是基于用户相似度进行推荐,具有比较强大的社交属性,用户能快速得知与自己相似兴趣的人最近又关注了哪些,即使某些内容曾经并不感兴趣,但是通过朋友的推荐点击,也会动态更新在自己的推荐列表中(类似于抖音朋友推荐了xxx视频),应用场景:新闻热点类。
- ItemCF更用于兴趣变化比较稳定的应用,比如一个用户在某个时间段内比较关注篮球鞋,这时候根据物品相似度就会推荐球衣或者体育器材等商品。应用场景:电商购物网站,音乐推荐,电影推荐。
协同过滤算法的优缺点
优点
- 个性化推荐
- 没有约束条件
- 灵活性高
- 可扩展性好
- 算法效果好
缺点
- 稀疏性问题
- 冷启动问题
- 数据稳定性问题
- 算法适用性问题
协同过滤算法的总结与展望
- 协同过滤是个比较直观且解释性较强的一类模型算法,但是没有较强的泛化能力,也就是两两物品的相似性无法推广到其他商品相似度计算中,这样就会存在一个很严重的问题,就是对于近期具有头部热门商品,容易跟大量物品产生相似性,而尾部的稀疏向量就无法与其他物品产生相似性计算而减少对其的推荐。总结一下来说,推荐结果头部效应比较明显,但处理稀疏向量能力弱。
- 对于解决此类问题,我们可以引用矩阵分解技术来增强模型的泛化能力,在协同过滤共现矩阵的基础上,添加用户与物品之间稠密的隐向量,从而挖掘隐含特征,来解决稀疏性问题。
Q&A
- Q:对于日增大量商品,文章,电影(十万,百万级别)的情况下,如何考虑相似度计算?
- A:在每天新增大量物品的情况下,一次性对所有物品进行相似度计算可能会非常耗时和占用大量的计算资源。为了提高计算效率,可以考虑以下几种方法:
-
- 增量计算:只对每天新增的商品与以往商品进行相似度计算。
-
- 分布式计算:使用Hadoop Spark大数据框架进行分布式计算,将商品数据分割成多个分区,利用服务器并行计算各个分区之间的相似度,最后再合并结果。
-
- 近似相似度计算:在实际应用中,并不需要精确的相似度计算。可以考虑使用一些近似相似度计算的方法(如LSH、MinHash等),通过降低计算复杂度来快速估计文章之间的相似度。
-