论文:https://arxiv.org/pdf/2205.14135.pdf
核心思想
FlashAttention 提出的是为了解决 Transformers 在处理长序列时的速度慢和内存消耗大的问题。
这个问题主要是因为,自注意力模块在长序列上的时间和内存复杂度都是二次方的。
FlashAttention的本质是通过创新的算法设计,实现了对Transformer模型中注意力机制的高效计算。
FlashAttention通过减少HBM访问次数和避免存储大型中间矩阵,使BERT模型比MLPerf 1.1的速度记录快15%,GPT-2的训练速度提高了最高3倍。
使用FlashAttention的GPT-2模型,在4K的上下文长度下训练比Megatron在1K上下文长度下训练还快,同时困惑度(perplexity)更低,说明模型质量提高。
FlashAttention在常见序列长度(最高2K)上比标准注意力实现快3倍,并且其内存占用随序列长度线性增长,证明了其在效率和内存使用上的优势。
块稀疏FlashAttention通过仅计算重要的注意力块来减少计算量和内存使用,使得Transformer模型能够处理高达64K序列长度,且在Path-256任务上达到了63.1%的准确率,显示了其在处理长序列任务上的能力。
它通过以下核心方法和策略,解决了传统注意力计算在长序列处理时遇到的速度慢和内存消耗大的问题:
IO-感知优化:FlashAttention深入考虑了GPU内存层次之间的交互,特别是高带宽内存(HBM)与片上SRAM之间的读写操作,通过优化这些操作来减少内存访问成本,从而提高计算效率。
分块计算(Tiling):通过将输入序列分成小块并逐块处理,FlashAttention避免了一次性加载整个序列到内存中,减轻了内存压力,并使得注意力计算更加高效。
重计算策略:为了减少后向传播时对大型中间矩阵的存储需求,FlashAttention采用了在需要时重新计算这些矩阵的策略,从而节省了大量的内存空间。
核心融合:FlashAttention通过将多个计算步骤融合到一个CUDA核心中执行,减少了内存访问次数,并提高了执行速度。
这些策略共同作用,使FlashAttention能够以更少的内存访问和更低的时间复杂度,准确地计算出注意力,从而在保持模型质量的同时,显著提高了训练速度和效率。
此外,FlashAttention的设计还支持块稀疏注意力,进一步提高了处理长序列能力,使得在资源有限的情况下,Transformer模型能够处理更长的上下文信息,这在自然语言处理和其他需要长序列处理的领域中尤为重要。
FlashAttention本质上是对传统Transformer注意力机制的一个高效、内存友好的改进,它通过深入挖掘和优化计算机内存和计算资源的使用方式,推动了深度学习模型在复杂任务上的应用和发展。
核心操作融合,减少高内存读写成本
- 子解法: IO-感知算法(IO-Awareness)
- 解释: 传统的注意力算法没有考虑到 GPU 内存层次之间的读写成本,导致了大量的内存访问,进而增加了计算时间和内存消耗。
- FlashAttention 通过考虑 IO,即输入/输出操作,特别是在 GPU 高带宽存储器(HBM)与 GPU 上的 SRAM 之间的读写操作,来降低这些成本。
- 例子: 在传统的 Transformer 模型中,整个注意力矩阵需要从 HBM 读入到 SRAM 中进行计算,
- 然后结果再写回 HBM,这个过程中的读写操作非常耗时和耗内存。
- FlashAttention 通过减少这种读写操作的次数,来减少内存访问成本。
在标准注意力计算中,每个操作(如 softmax、矩阵乘法等)都需要从 HBM 读取输入,计算后再将结果写回 HBM,导致高内存访问成本。
如果我们可以将多个操作合并为一个操作(核心融合),那么输入只需从 HBM 加载一次,这样就减少了内存访问次数,从而降低了内存访问成本。
分块计算(Tiling),避免存储一次性整个矩阵
- 子解法: 增量式 softmax 计算(Tiling)
- 解释: 标准的注意力机制需要存储整个注意力矩阵以便于后向传播,这在长序列上是非常内存消耗的。
- FlashAttention 通过将输入分块(tiling)并多次通过输入块逐步执行 softmax 减少(也称为 tiling),避免了一次性处理整个大矩阵。
- 例子: 假设有一个很长的序列,传统方法需要一次性计算和存储整个序列的注意力矩阵。
- FlashAttention 则将序列分成小块,每次只处理一个块,并逐步累积计算结果,从而不需要存储整个大矩阵。
在标准注意力机制中,整个注意力矩阵需要一次性计算并存储,导致对 HBM 的大量访问。
通过将输入矩阵 Q、K、V 分块并逐块计算,我们可以逐步生成注意力输出,减少了一次性对大量数据的访问需求。
一个大型矩阵乘法,通过将矩阵分为小块,每次只处理一部分数据,就可以减少内存的即时需求。
块稀疏注意力,处理长序列时的效率问题
- 子解法: 块稀疏注意力(Block-sparse Attention)
- 解释: 长序列上的注意力计算复杂度高,导致计算缓慢。
- FlashAttention 引入了块稀疏技术,通过只计算序列中重要部分的注意力,忽略其他不重要的部分,从而减少计算量。
- 例子: 在处理一个长文本时,可能只有部分词语之间存在强关联,而其他词语的关联性较弱。块稀疏注意力允许模型只关注那些重要的词语间的关联,忽略其他,从而加速计算并降低内存使用。
利用快速 SRAM,处理内存与计算速度不匹配
- 子解法: 利用快速 SRAM
- 原因: 现代 GPU 的计算速度相比内存速度增长得更快,使得大多数操作成为内存访问受限。
- 例子: 通过更多地利用每个流式多处理器上的快速 SRAM(与 HBM 相比,SRAM 速度快得多但容量小得多),我们可以加速那些内存访问受限的操作,例如通过在 SRAM 中计算部分结果来减少对 HBM 的访问。
算术强度优化,处理计算与内存访问的不平衡
- 子解法: 算术强度优化
- 原因: 操作可以根据计算和内存访问之间的平衡被分类为计算密集型或内存访问密集型。
- 标准注意力实现中,很多操作(如 softmax)是内存访问密集型的。
- 例子: 通过优化算术强度,即每字节内存访问的算术操作数量,我们可以尽量将操作转变为计算密集型,从而减轻内存访问的瓶颈。
重计算,解决后向传递中存储大型中间矩阵的需求
- 子解法: 重计算(Recomputation)
- 原因: 标准实现中,后向传递需要访问前向传递计算时产生的大型中间矩阵(如 S 和 P 矩阵)。通过存储必要的统计量而非整个矩阵,并在需要时重计算这些矩阵,可以避免大量的内存使用。
- 例子: 类似于梯度检查点技术,我们不存储整个计算过程中的中间状态,而是仅存储关键节点,需要时再重建整个状态。
通过子解法的组合,FlashAttention 成功地解决了 Transformers 在处理长序列时速度慢和内存消耗大的问题。
FlashAttention 提出了一种计算精确注意力的算法,其关键在于通过减少对高带宽内存(HBM)的读写操作以及避免在后向传递中存储大型中间矩阵,从而实现了既节省内存又加速计算的目标。
在探索传统注意力机制在现代硬件(尤其是 GPU)上的执行效率时,遇到了一系列的具体问题,这些问题导致了处理速度慢和高内存消耗。
每种解决方案都直接针对了标准注意力实现中的效率瓶颈,通过改善内存访问模式、减少不必要的内存写入和读取、以及优化计算流程来提高整体性能。
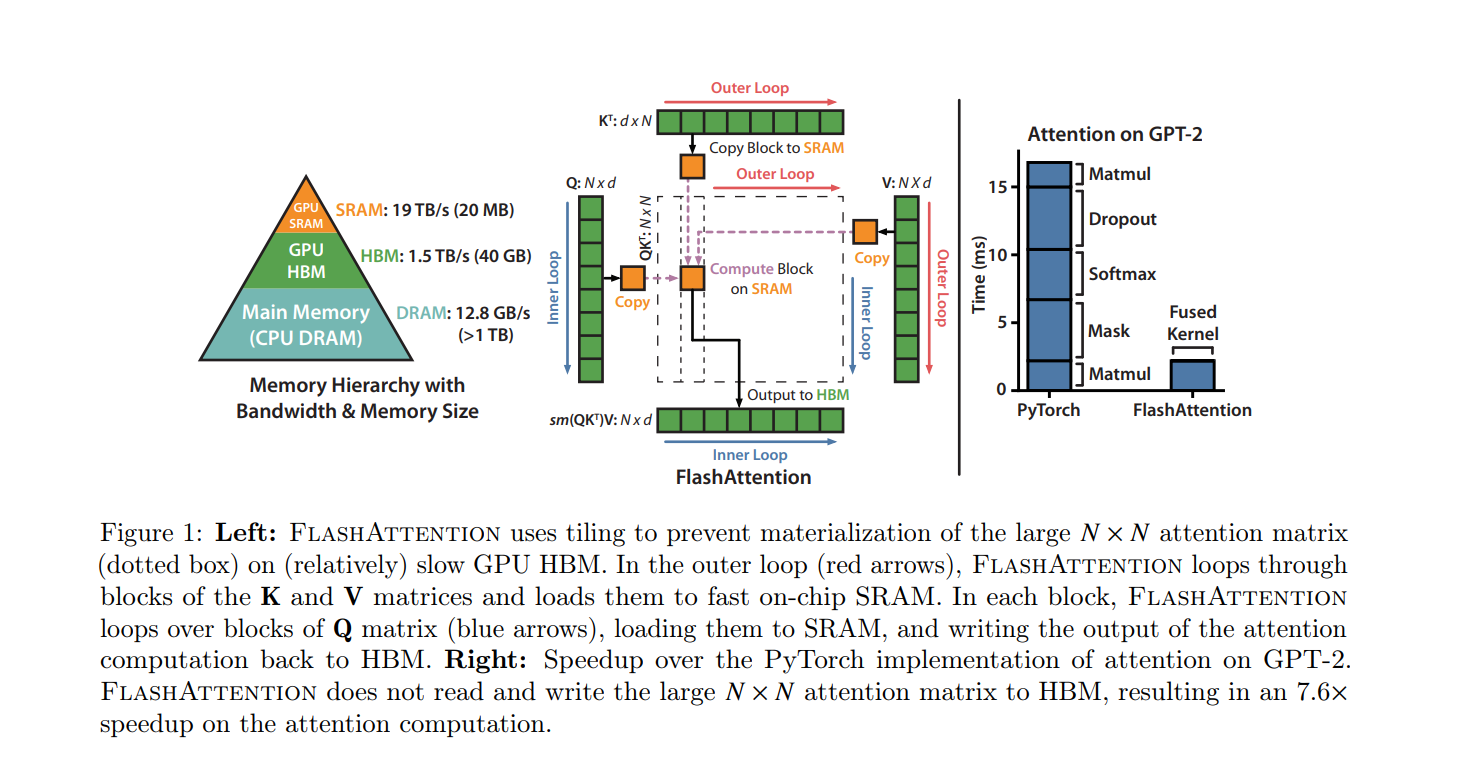
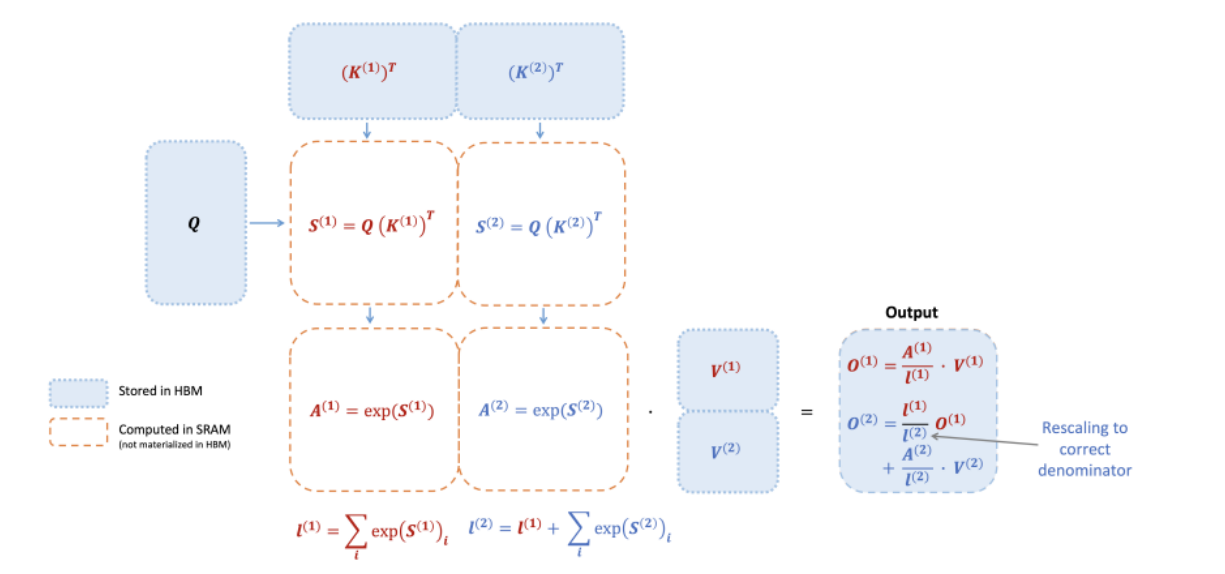
左侧:展示了在GPU中的内存层次结构和FlashAttention如何在这种结构中工作。
它说明了:
- GPU的不同内存层次及其带宽和大小,包括片上SRAM(20MB, 19TB/s),高带宽内存HBM(40GB, 1.5TB/s),以及主内存DRAM(12.8GB/s, 大于1TB)。
- FlashAttention使用分块计算(Tiling)来避免实现大型 N×N 注意力矩阵。
- 在外部循环(红色箭头)中,FlashAttention遍历K和V矩阵的块,并将它们加载到快速的片上SRAM中。
- 在每个块中,FlashAttention遍历Q矩阵的块(蓝色箭头),加载到SRAM中,并将注意力计算的输出写回到HBM。
右侧:显示了使用PyTorch实现的注意力计算与FlashAttention实现在GPT-2模型上的速度对比。
它说明了:
- FlashAttention与PyTorch实现相比在各个组件(矩阵乘法、Dropout、Softmax、Mask和Fused Kernel)上的时间消耗。
- FlashAttention没有读写大型 N×N 注意力矩阵到HBM,因此在注意力计算上得到了约7.6倍的加速。
当前FlashAttention实现的局限性,并提出了未来发展的方向
低级语言编程的复杂性
- 子解法1: 高级语言到CUDA的自动编译
- 原因: 目前,IO-感知的注意力实现需要在CUDA中手动编写新的核函数,这不仅需要在比PyTorch这样的高级语言更低级的语言中编程,而且还需要大量的工程努力。
- 例子: 类似于图像处理领域的Halide工具,可以让研究人员用高级语言编写算法,然后自动编译成优化的CUDA代码,减少直接使用CUDA编程的复杂性。
IO-感知优化的普遍性
- 子解法2: 扩展IO-感知实现到其他模块
- 原因: 虽然注意力计算是Transformer模型中最耗内存的部分,但模型的每一层都需要与GPU的高带宽内存(HBM)交互。
- 例子: 在深度学习模型的其他组件,如卷积层或循环层,也采用IO-感知的实现方法,可以进一步提高整个模型的效率。
多GPU并行计算的IO优化
- 子解法3: 多GPU间的IO-感知方法
- 原因: FlashAttention的当前实现在单GPU上是最优的,但注意力计算可以跨多GPU并行化,这引入了考虑GPU间数据传输的额外IO分析层。
- 例子: 通过设计能够优化GPU间数据传输的IO-感知算法,可以在不牺牲性能的前提下,实现更大规模的模型训练和更高效的并行计算。
从提高开发效率、扩展IO-感知优化的应用范围,到优化多GPU并行计算的效率。