Paper: Kirillov A, Mintun E, Ravi N, et al. Segment anything[J]. arXiv preprint arXiv:2304.02643, 2023.
Introduction: https://segment-anything.com/
Code: https://github.com/facebookresearch/segment-anything
SAM 是 Meta AI 开发的一款基于 prompt 的通用视觉大模型,能够 zero-shot 识别并分割给定图像中任意类型的目标,并且能够迁移到其他任务中。SAM 的动机是为了建立一个通用的图像分割基础模型,类似于 NLP 领域的 GPT-3,可以在不需要额外训练的情况下,适应各种下游任务和数据集。

本文不再按照论文解读的方式逐段记录,只专注于介绍 SAM 技术本身,参考 五分钟看明白分割一切模型 SAM。
一. 背景
SAM 模型的目标是实现图像的交互式分割,即根据用户提供的 prompt 来划分图像中的不同对象或区域。但想要根据用户 prompt 分割图像是一个复杂的问题,因为 prompt 可能不完整、不清晰、甚至不准确,图像中的对象或区域也可能是多样、复杂、模糊或重叠的。
为了能够理解图像内容和用户意图,SAM 使用基于 transformer 的视觉模型,可以在不需要任何标注的情况下,对任意图像进行分割。它的输入包括一个图像和 prompt,prompt 可以是点、框、文本或者掩码,用来指示要分割的目标;输出是一个分割掩码,表示图像中每个像素属于前景或背景的概率。

二. SAM 模型
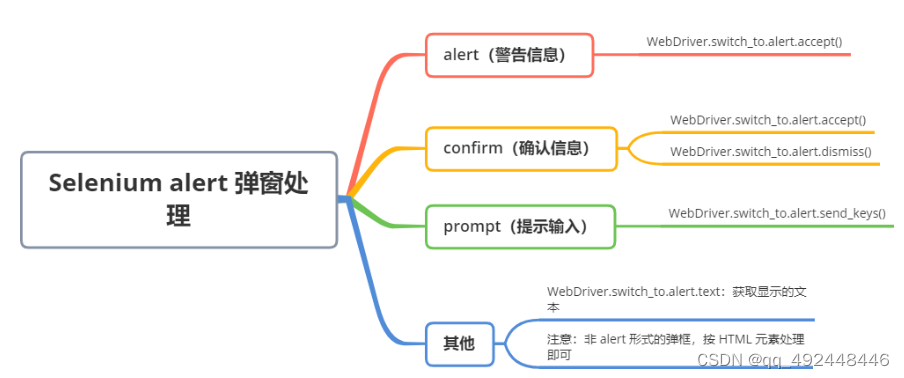
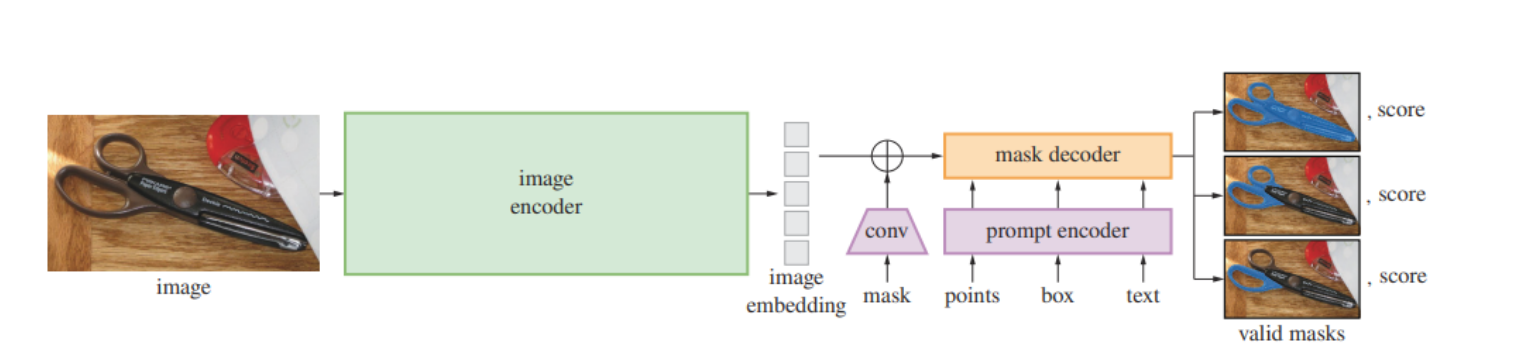
SAM 模型基于 Transformer 架构,主体包含以下三个部分:
- 图像编码器 (image encoder):使用 ViT 将图像编码为特征向量;
- 提示编码器 (prompt encoder):使用 MLP 将用户提供的 prompt(点、框、文本等)编码为 prompt 向量;
- 掩码解码器 (mask decoder):使用另一个 MLP 将图像特征向量和 prompt 向量结合起来,生成每个像素的掩码概率;

Pipeline 如下图所示,图像编码器将图像编码为特征向量,提示编码器将 prompt 映射到同样的特征空间,掩码解码器将两个特征融合并解码出最终的分割掩码。如果 prompt 较为模糊,对应多个对象,SAM 还可以输出多个有效的掩码和相关的置信度:

为了将 Transformer 应用到图像上,图像编码器 首先将图像划分为多个小块,每个小块对应一个像素块,然后将每个像素块的颜色值转化成一个向量,作为 Transformer 的输入序列。这样,每个像素块就相当于 Transformer 中的一个词,而图像就相当于 Transformer 中的一个句子。
为了将用户 prompt 作为 Transformer 的输入,提示编码器 将不同类型的提示转换为统一的向量表示,然后与图像特征向量拼接在一起,作为 Transformer 的输入序列。这样,每个提示就相当于 Transformer 中的一个词,而图像和提示的组合就相当于 Transformer 中的一个句子。
通过 Transformer 的 self-attention 机制,掩码解码器 可以计算图像中每个像素块与其他像素块以及用户的提示之间的相关性,从而学习图像的结构和语义信息,以及用户的意图信息。然后,SAM 模型使用一个线性层,将 Transformer 的输出序列映射为一个分割掩码,表示每个像素块的标签:

三. 训练方法
SAM 强大的分割能力源于它庞大的数据集 SA-1B —— 一个包含超过 10 亿 mask 的大规模视觉数据集,覆盖了各种物体、场景和类别。这使得它具有强大的 视觉表示能力 和 零样本泛化能力,可以直接使用预训练的模型通过简单的提示来分割未见过的目标,而不需要像以往的分割模型那样为每个任务进行专门的训练或微调,从而节省了大量的时间和资源。

为了实现强大的泛化能力,SAM 需要在大规模和多样化的 mask 上进行训练。但现有 mask 的训练数据较少,不能够满足 SAM 的需求。因此,SAM 提出了 数据引擎 (data engine) 策略,即收集数据与模型训练协同进行,包含以下三个阶段:
- 协助手动 (assisted-manual) 阶段:SAM 协作标注员手动标注 mask;
- 半自动 (semi-automatic) 阶段:SAM 提示对象可能的位置并自动生成部分 mask,标注员专注于标注 SAM 未能自动生成的其他物体的 mask;
- 全自动 (fully automatic) 阶段:SAM 接收对象的 foreground points,从而在每张图像上生成多个高质量 mask。
四. 总结
SAM 是一个通用的基于 prompt 的图像分割大模型,可以分割给定图像中的任何目标。其优势在于它可以处理多种类型的 prompt,甚至是多个 prompt 的组合,还可以处理未见过的对象或场景,而不需要额外的训练。这些优势使得 SAM 模型具有强大的泛化能力和灵活性,可以应对各种复杂的图像分割任务。

自从 SAM 发布以来,基于 SAM 的二次应用和衍生项目越来越多,如:
- 图像修复:利用 SAM 的 mask 生成能力,可以实现对图像中的缺失或损坏区域的修复,例如去除水印、恢复老照片等;
- 图像编辑:利用 SAM 的分割能力,可以实现对图像中的对象的编辑,例如更换背景、调整颜色、添加滤镜等;
- 目标检测:利用 SAM 的边界框提示,可以实现对图像中的对象的检测,例如识别人脸、车辆、动物等;
- 图像标注:利用 SAM 的文本提示,可以实现对图像中的对象的标注,例如生成图像描述、图像标题、图像问答等;
- 视频跟踪:利用 SAM 的视频输入,可以实现对视频中的对象的跟踪,例如跟踪运动员、行人、车辆等;
- 3D 检测:利用 SAM 的点云输入,可以实现对 3D 场景中的对象的检测,例如检测房屋、树木、人群等。
五. 复现
Meta AI 开源了 SAM 的代码,也提供了 在线 demo,支持 point、box、everything三种方式。由于 text prompt 效果不太稳定,因此 demo 和代码中都没有该部分。
以 Demo 为例,鼠标悬停即可显示该位置的分割结果:

Hover & Click:Add Mask 可以增加 point 以选中目标区域,Remove Area 可以删除 point 以删除不必要的部分;


Box:Add Mask 可以增加 point 以选中目标区域,Remove Area 可以删除 point 以删除不必要的部分;


Everything:可以将图片中所有物体的分割 mask 都展示出来;































![[Mac软件]Amadeus Pro 2.8.13 (2662) Beta多轨音频编辑器激活版](https://img-blog.csdnimg.cn/img_convert/49e348c21cb8bf733223084738fe4234.png)