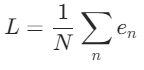【深度学习:多关节嵌入模型】 Meta 解释的 ImageBind 多关节嵌入模型
在不断发展的人工智能领域,Meta 凭借其开源模型 ImageBind 再次提高了标准,突破了可能性的界限,让我们更接近类人学习。
创新是 Meta 使命的核心,他们的最新产品 ImageBind 证明了这一承诺。虽然 Midjourney、Stable Diffusion 和 DALL-E 2 等生成式 AI 模型在单词与图像配对方面取得了重大进展,但 ImageBind 更进一步,撒下了一张涵盖更广泛感官数据的网。
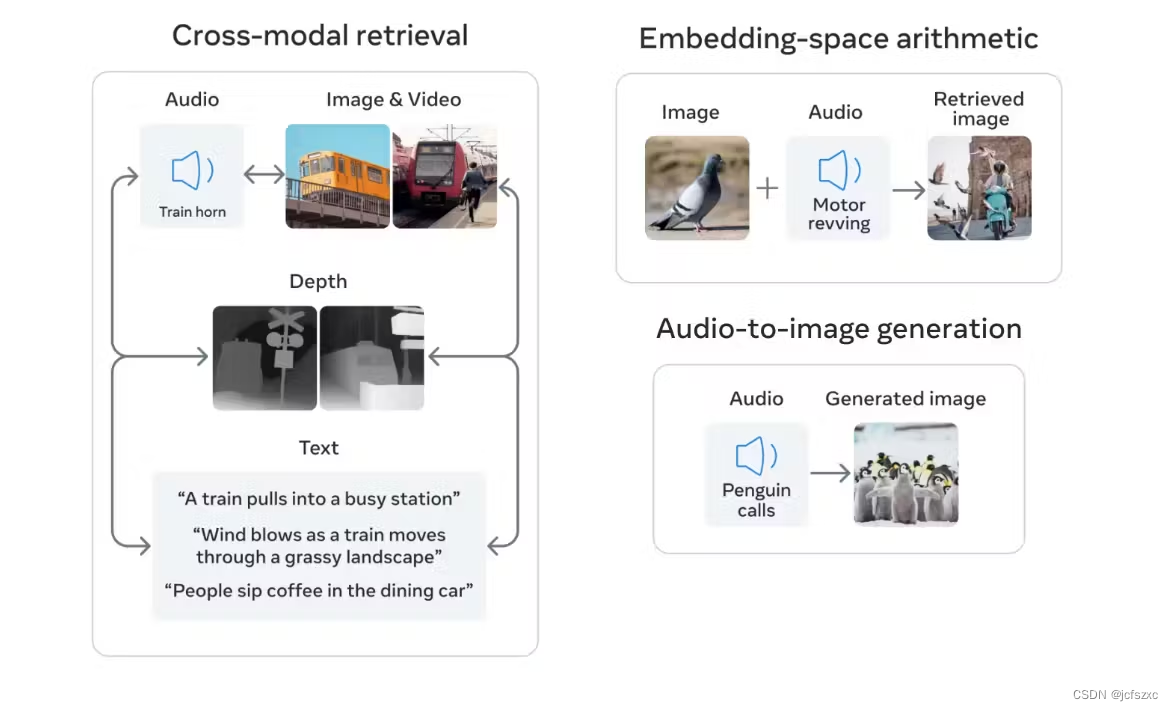
ImageBind 标志着一个框架的诞生,该框架可以通过文本提示、图像或音频记录等简单输入生成复杂的虚拟环境。例如,想象一下仅通过文字或声音即可创建熙熙攘攘的城市或宁静的森林的真实虚拟表示的可能性。
ImageBind 的独特之处在于它能够集成六种类型的数据:视觉数据(图像和视频)、热数据(红外图像)、文本、音频、深度信息,以及有趣的是来自惯性测量单元的运动读数(惯性测量单元)。这种将多种数据类型集成到单个嵌入空间中的概念只会推动生成人工智能的持续繁荣。
该模型利用广泛的图像配对数据来建立统一的表示空间。与传统模型不同,ImageBind 不要求所有模态同时出现在同一数据集中。相反,它利用图像固有的链接性质,证明将每种模态的嵌入与图像嵌入对齐会产生紧急的跨模态对齐。
虽然 ImageBind 目前是一个研究项目,但它是多模式模型未来的有力指标。它还强调了 Meta 致力于分享人工智能研究成果,而其许多竞争对手(如 OpenAI 和谷歌)都保持着保密的面纱。
在本解释中,我们将介绍以下内容:
- What is multimodal learning 什么是多模态学习
- What is an embedding 什么是嵌入
- ImageBind Architecture 图像绑定架构
- ImageBind Performance 图像绑定性能
- Use cases of ImageBind ImageBind 的用例
Meta 发布开源人工智能工具的历史
在过去的两个月里,Meta 的发布取得了令人难以置信的成功。
分段任何模型
MetaAI 的分段任意模型 (SAM) 通过应用自然语言处理中传统使用的基础模型,改变了未来的图像分割。

SAM 使用即时工程来适应各种分割问题。该模型使用户能够通过使用边界框、关键点、网格或文本与提示进行交互来选择要分割的对象。
当要分割的对象不确定时,SAM可以产生多个有效的掩模,并且可以自动识别和掩模图像中的所有对象。
最值得注意的是,与标签平台集成后,一旦预先计算图像嵌入,SAM 就可以提供实时分割掩模,这对于正常尺寸的图像来说只需几秒钟的时间。

SAM 在降低标签成本方面展现出巨大潜力,为人工智能辅助标签提供了期待已久的解决方案。无论是医疗应用、地理空间分析还是自动驾驶汽车,SAM 都将彻底改变计算机视觉领域。
DINOv2
DINOv2 是一种先进的自监督学习技术,旨在在不使用标记数据的情况下从图像中学习视觉表示,这比依赖大量标记数据进行训练的监督学习模型具有显着优势。

DINO 可以用作强大的特征提取器,用于图像分类或对象检测等任务。该过程通常涉及两个阶段:预训练和微调。
预训练:在此阶段,DINO 模型在未标记图像的大型数据集上进行预训练。目标是使用自我监督学习来学习有用的视觉表示。模型训练完成后,权重将被保存以供下一阶段使用。
微调:在此阶段,预训练的 DINO 模型在特定于任务的数据集上进行微调,该数据集通常包含标记数据。对于图像分类或对象检测任务,您可以使用 DINO 模型作为主干或特征提取器,然后是特定于任务的层(例如用于分类的全连接层或用于对象检测的边界框回归层)。
SSL 的挑战仍然在于设计实际任务、处理域转换以及理解模型的可解释性和鲁棒性。然而,DINOv2 使用无标签自蒸馏 (DINO) 等技术克服了这些挑战,该技术使用 SSL 和知识蒸馏方法将知识从较大模型转移到较小模型。
什么是多模态学习?
多模态学习涉及处理和集成来自多种模态的信息,例如图像、文本、音频、视频和其他形式的数据。
它结合了不同的信息源,以获得对特定概念或现象的更深入的理解。
与重点关注单一模态(例如纯文本或纯图像)的单模态学习相反,多媒体学习利用多种模态的互补性来改善学习成果。
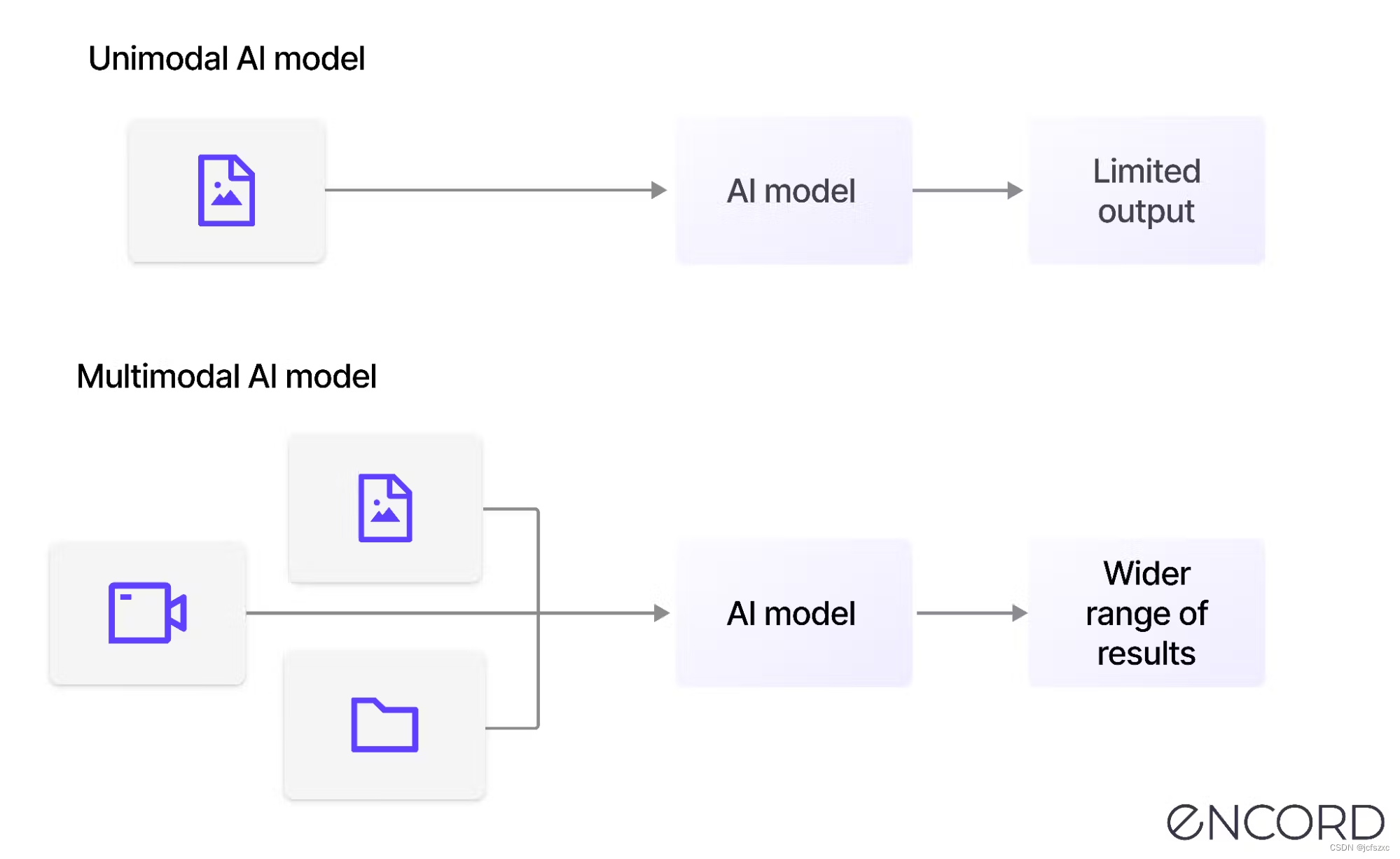
多模态学习旨在使机器学习算法能够从不同来源的复杂数据中学习和理解。它允许人工智能像人类一样全面分析不同类型的数据。
什么是嵌入?
嵌入是高维向量的低维表示,可简化对代表数据的稀疏向量等重要输入的处理。提取嵌入的目的是通过在更低维的空间中表示输入数据来捕捉输入数据的语义,从而使语义相似的样本彼此接近。
嵌入解决了机器学习中的 "维度诅咒 "问题,即输入空间过于庞大和稀疏,传统机器学习算法无法高效处理。通过将高维输入数据映射到低维嵌入空间,我们可以降低数据的维度,从而更容易学习输入数据之间的模式和关系。
当输入空间通常非常高维和稀疏时,嵌入就特别有用,比如文本数据。对于文本数据来说,每个单词都由一个单点向量表示,这就是嵌入。通过学习单词的嵌入,我们可以捕捉到单词的语义,并以更紧凑、信息量更大的方式来表示它们。
嵌入式在机器学习中很有价值,因为它们可以从大量数据中学习,并在各种模型中使用。
什么是 ImageBind?
ImageBind 是一种学习六种模式联合嵌入空间的全新方法。该模型由 Meta AI 的 FAIR 实验室开发,于 2023 年 5 月 9 日在 GitHub 上发布,您也可以在 GitHub 上找到 ImageBind 代码。
ImageBind 的出现标志着机器学习和人工智能的重大转变,因为它推动了多模态学习的发展。

通过整合和理解来自多种模式的信息,ImageBind 为更先进的人工智能系统铺平了道路,使其能够更人性化地处理和分析数据。
集成在 ImageBind 中的模式
ImageBind 设计用于处理六种不同的模式,使其能够更全面、整体地学习和处理信息。这些模式包括
- 文本:书面内容或描述,传达意义、背景或有关主题的具体细节。
- 图像/视频:捕捉场景、物体和事件的可视化数据,提供丰富的上下文信息,并在数据中的不同元素之间建立联系。
- 音频:为视觉或文本信息提供额外上下文的声音数据,例如物体发出的噪音或特定环境的声景。
- 深度(三维): 三维数据可提供物体之间的空间关系信息,使人们更好地了解物体之间的位置和大小。
- 热图: 捕捉物体及其周围环境温度变化的数据,让人了解场景中不同元素的热特征。
- IMU:记录运动和位置的传感器数据,让人工智能系统了解特定环境中物体的运动和动态。

通过整合这六种模式,ImageBind 可以创建一个统一的表示空间,使您能够学习和分析各种信息形式的数据。
这可以提高模型对周围世界的理解,使其能够根据处理的数据做出更好的预测,生成更准确的结果。
图像绑定架构
由于 Meta 团队尚未发布 ImageBind 框架,因此该框架仍有可能发生变化。这里讨论的架构是基于该团队发表的研究论文中的信息。
ImageBind 框架为图像、文本、音频、热图像、深度图像和 IMU 模式使用单独的编码器。每个编码器都添加了一个特定于模式的线性投影头,以获得固定维度的嵌入。这种嵌入经过归一化处理后用于 InfoNCE 损失。
ImageBind 的结构由三个主要部分组成:
- A modality-specific encoder 特定模式编码器
- Cross-model attention module 跨模型关注模块
- A joint embedding space 联合嵌入空间

特定模式编码器
第一部分是为每种数据类型训练特定模态的编码器。接下来,编码器将原始数据转换为联合嵌入空间,在此空间中,模型可以学习不同模态之间的关系。
模态编码器采用变换器架构。编码器采用标准的反向传播方法进行训练,损失函数鼓励不同模态的嵌入向量在相关的情况下相互靠近,在不相关的情况下相互远离。
对于图像和视频,它使用 Vision Transformer (ViT)。对于视频输入,在 2 秒的持续时间内对 2 帧视频剪辑进行采样。
使用 AST 中概述的方法将音频输入转换为 2D Mel-Spectrogram 图:音频频谱图转换器,该方法涉及以 26kHz 转换 2 秒的音频样本。由于梅尔频谱图是类似于图像的二维信号,因此使用ViT模型对其进行处理。
对于文本,使用递归神经网络 (RNN) 或转换器作为编码器。转换器将原始文本作为输入,并生成一系列隐藏状态,然后聚合这些状态以生成音频嵌入向量。
热输入和深度输入被视为单通道图像,分别使用 ViT-B 和 ViT-S 编码器。
跨模态注意力模块
第二个部分是跨模态注意力模块,由三个主要子部分组成:
- 特定模式的注意力模块
- 跨模态注意力融合模块
- 跨模态注意力模块
特定模态注意力模块将每种模态的嵌入向量作为输入。该模块会产生一组注意力权重,以显示每种模态中不同元素的相对重要性。这样,模型就能关注与任务相关的每种模态的特定方面。
跨模态注意力融合模块从每种模态中提取注意力权重,并将其组合在一起,生成一组单一的注意力权重,以确定在执行任务时对每种模态的重视程度。通过根据不同模态在当前任务中的重要性对其进行选择性关注,该模型可以有效捕捉不同数据类型之间的复杂关系和相互作用。
跨模态注意力模块与模型的其他部分采用反向传播和特定任务损失函数进行端到端训练。通过联合学习特定模态注意力权重和跨模态注意力融合权重,该模型可以有效整合来自多种模态的信息,从而提高各种多模态机器学习任务的性能。
联合嵌入
第三部分是联合嵌入空间,所有模态都在一个单一的向量空间中表示。嵌入向量通过共享投影层映射到一个共同的联合嵌入空间,该投影层也是在训练过程中学习的。这一过程确保不同模态的嵌入向量位于同一空间,可以直接进行比较和组合。
联合嵌入空间旨在捕捉不同模式之间的复杂关系和相互作用。例如,相关的图像和文本应相互靠近,而不相关的图像和文本应相互远离。
ImageBind 使用联合嵌入空间,可以直接比较和组合不同的模态,可以有效地整合来自多种模态的信息,以提高各种多模态机器学习任务的性能。
ImageBind 训练数据
ImageBind 是一种新颖的多模态学习方法,它利用图像固有的“绑定”属性来连接不同的感官体验。
它使用图像配对数据(image,X)进行训练,这意味着每个图像都与其他五种类型的数据(X)之一相关联:文本,音频,深度,IMU或热数据。在 ImageBind 训练期间,图像和文本编码器模型不会更新,而其他模式的编码器会更新。
OpenCLIP ViT-H 编码器:此编码器用于初始化和冻结图像和文本编码器。ViT-H 编码器是 OpenCLIP 模型的一部分,OpenCLIP 模型是一种强大的视觉语言模型,可提供丰富的图像和文本表示。
音频嵌入:ImageBind 使用 Audioset 数据集来训练音频嵌入。Audioset 是音频事件注释和录音的综合集合,为模型提供了广泛的学习声音。
深度嵌入:SUN RGB-D 数据集用于训练深度嵌入。该数据集包括使用深度信息注释的图像,使模型能够理解图像中的空间关系。
IMU 数据:Ego4D 数据集用于 IMU 数据。该数据集提供 IMU 读数,有助于理解与图像相关的运动和方向。
热嵌入:LLVIP 数据集用于训练热嵌入。该数据集提供热成像数据,为模型对图像的理解增加了另一层信息。
ImageBind 性能
ImageBind 模型的性能以几种最先进的方法为基准。此外,它还与之前在零样本检索和分类任务中的工作进行了比较。
ImageBIND 在训练期间无需对音频进行任何文本配对,即可实现更好的零样本文本到音频检索和分类性能。例如,在 Clotho 数据集上,与监督式 AudioCLIP 模型相比,ImageBIND 的性能是 AVFIC 的两倍,并且在 ESC 上实现了相当的音频分类性能。在 AudioSet 数据集上,它可以使用预训练的 DALLE-2 解码器从音频输入生成高质量图像。

ImageBind 是开源的吗?
可悲的是,ImageBind 的代码和模型权重是在 CC-BY-NC 4.0 许可下发布的。这意味着它只能用于研究目的,并且严格禁止所有商业用例。
利用 ImageBind 进行多模态学习的未来潜力
凭借其结合来自六种不同模式的信息的能力,ImageBind 有可能创建令人兴奋的新 AI 应用程序,特别是对于创作者和 AI 研究社区。
ImageBind 如何开辟新途径
ImageBind 的多模态功能有望开启一个充满创意可能性的世界。无缝集成各种数据表单使创作者能够:
生成富媒体内容:ImageBind 绑定多种模态的能力使创作者能够生成更具沉浸感和上下文相关的内容。例如,想象一下根据音频输入创建图像或视频,例如生成与繁华的市场、幸福的热带雨林或繁忙街道的声音相匹配的视觉效果。
通过跨模态检索增强内容:创作者可以轻松搜索并整合来自不同模态的相关内容,以增强他们的工作。例如,电影制作人可以使用 ImageBind 找到与特定视觉场景相匹配的完美音频剪辑,从而简化创作过程。
结合不同模态的嵌入:联合嵌入空间允许我们组合两个嵌入:例如,桌子上的水果图像+鸟儿的啁啾声,并检索包含这两个概念的图像,即树上的果实与鸟。涌现的组合性可能会使广泛的组合任务成为可能,它允许将来自各种模态的语义内容组合在一起。
开发身临其境的体验:ImageBind 能够处理和理解来自各种传感器(如深度和 IMU)的数据,为开发更逼真、更具吸引力的虚拟现实和增强现实体验打开了大门。
在更传统的行业中,其他未来的用例包括:
自动驾驶汽车:凭借其理解深度和运动数据的能力,ImageBind可以在开发自动驾驶汽车方面发挥关键作用,帮助它们更有效地感知和解释周围环境。
医疗保健和医学成像:ImageBind 可用于处理和理解各种类型的医疗数据(视觉、听觉、PDF 等),以协助诊断、治疗计划和患者监测。
智能家居和物联网:ImageBind 可以通过使智能家居设备能够处理和理解各种形式的感官数据来增强智能家居设备的功能,从而实现更直观、更有效的自动化。
环境监测:ImageBind 可用于无人机或其他监测设备,以分析各种环境数据并检测变化或异常,从而有助于野生动物跟踪、气候监测或灾难响应等任务。
安全和监控:通过处理和理解视觉、热和运动数据,ImageBind 可以提高安全系统的有效性,使其能够更准确、更高效地检测和响应威胁。
多模态学习的未来
ImageBind 代表了多模态学习的重大飞跃。这对人工智能和多模态学习的未来有几点影响:
扩展模式:随着研究人员继续探索和整合其他模式,如触觉、语音、嗅觉,甚至大脑信号,像 ImageBind 这样的模型可以在开发更丰富、更以人为本的 AI 系统方面发挥关键作用。
降低数据需求:ImageBind 表明,无需大量配对数据即可跨多种模态学习联合嵌入空间,从而可能减少训练所需的数据并使 AI 系统更高效。
跨学科应用:ImageBind在多模态学习方面的成功可以激发新的跨学科应用,例如将人工智能与神经科学、语言学和认知科学相结合,进一步增强我们对人类智能和认知的理解。
随着多模态学习领域的发展,ImageBind 有望在塑造 AI 的未来方面发挥关键作用,并为创作者和研究人员开启新的可能性。
结论
ImageBind是第一个将六种模态信息绑定在一起的模型,无疑是人工智能和多模态学习领域的游戏规则改变者。
它能够跨多种形式的数据创建单一的共享表示空间,这是朝着可以像人类一样全面分析数据的机器迈出的重要一步。对于人工智能研究社区和创作者来说,这是一个令人兴奋的前景,他们可以在未来利用这些功能来制作更丰富、更身临其境的内容。
此外,ImageBind 为未来的开源模型提供了蓝图,表明使用特定的图像配对数据可以跨多种模态创建联合嵌入空间。这可能会导致更高效、更强大的模型,这些模型可以以以前无法想象的方式学习和适应。
但是,该模型仍处于非商业许可之下,因此,我们将不得不拭目以待,看看该模型如何整合到商业应用中。在 2023 年底之前,是否会有多个完全开源的类似模型可用,这是值得怀疑的。