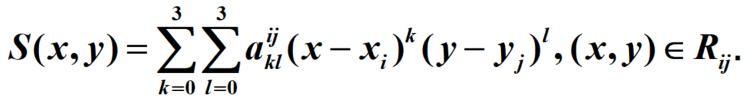今天在处理数据的时候发现有很多的缺失值,这时候的插值算法就登场了,但是我使用了一下spss的插值器发现真的是插值的一些数据就是一坨,根本不能看,所以我就打算使用Python来实现一下插值算法。
目录
代码解释
这段代码使用了 pandas 和 scipy.interpolate 库来进行线性插值,用于填补数据框中的缺失值。
pd.read_excel('D:\\文件.xlsx'):使用pandas的read_excel函数读取 Excel 文件,得到一个数据框df。df_new = df.copy():创建一个新的数据框df_new,该数据框将用于存储插值后的结果。通过使用copy()方法,确保对原始数据框的修改不会影响到新的数据框。遍历每一列:
for column in df.columns:通过这个循环,代码将遍历数据框中的每一列。
检查列是否有缺失值:
if df[column].isnull().any():使用
isnull()方法检查当前列是否包含缺失值,如果有,则进入下面的处理步骤。创建插值函数:
interp = interp1d(df.index[df[column].notnull()],df[column].dropna(),fill_value="extrapolate")使用
scipy.interpolate中的interp1d函数创建一个插值函数。该函数利用非空值的索引和对应的值来进行线性插值。fill_value="extrapolate"意味着对于超出原始范围的值,使用线性外推。使用插值函数填充缺失值:
df_new[column] = interp(df.index)通过调用插值函数,将当前列的缺失值填充为线性插值的结果。
将结果写入新的 Excel 文件:
df_new.to_excel('D:\\res.xlsx', index=False)将插值后的数据框保存为新的 Excel 文件。
总体而言,这段代码通过遍历每一列,检查缺失值,然后使用线性插值填充缺失值,最后将结果保存到新的 Excel 文件。插值方法采用了线性插值。
总体代码
import pandas as pd
from scipy.interpolate import interp1d
# 读取Excel文件
df = pd.read_excel('D:\\文件.xlsx')
# 创建一个新的DataFrame来存储结果
df_new = df.copy()
# 遍历每一列
for column in df.columns:
# 如果该列有缺失值
if df[column].isnull().any():
# 创建一个插值函数
interp = interp1d(df.index[df[column].notnull()], df[column].dropna(), fill_value="extrapolate")
# 使用插值函数填补缺失值
df_new[column] = interp(df.index)
# 将结果写入新的Excel文件
df_new.to_excel('D:\\res.xlsx', index=False)
示例
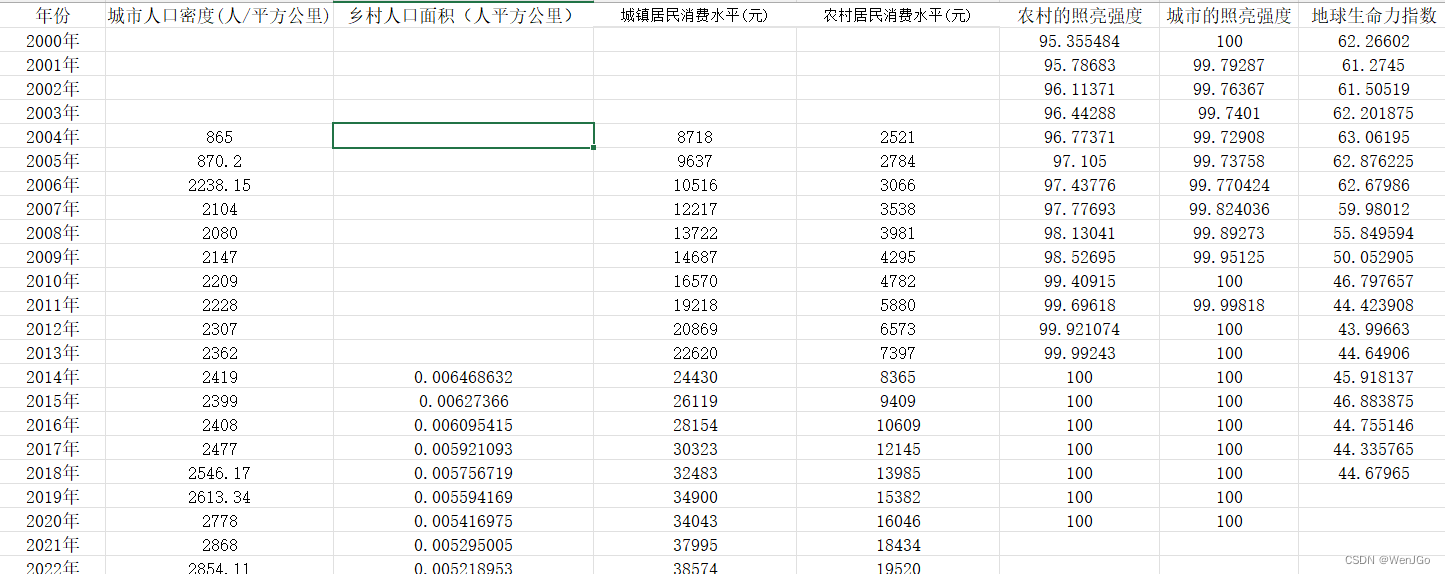
插值前
插值后
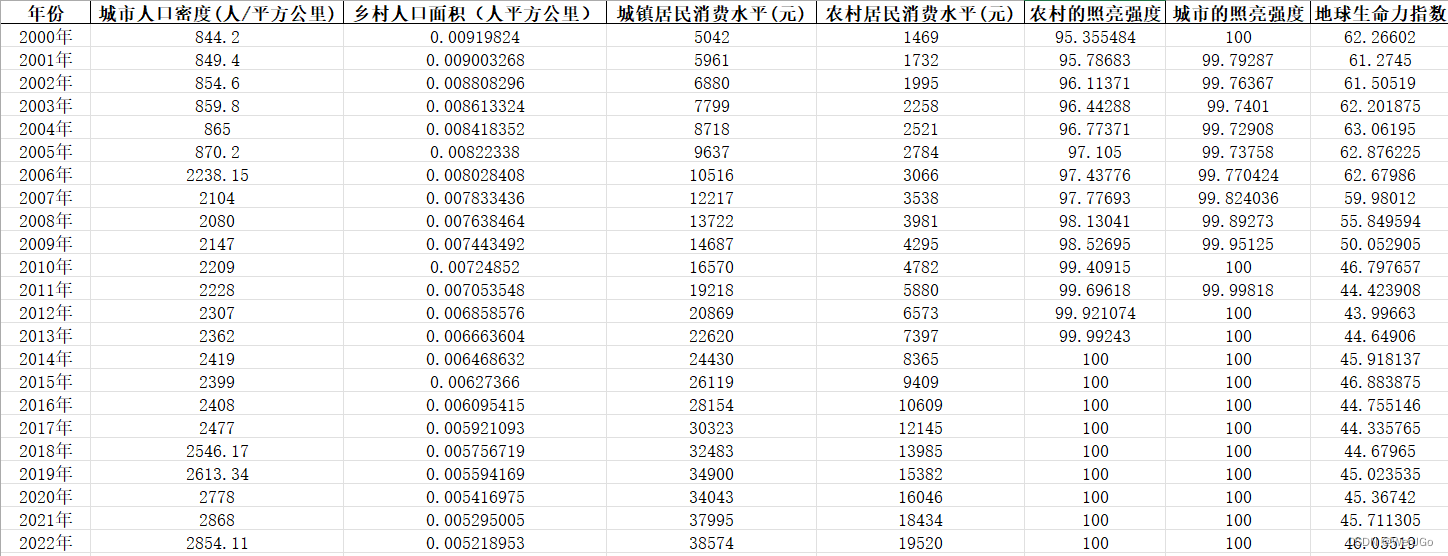
根据前后文来看,插值效果还是很不错的(*^▽^*)
总结
Python果然是万能的~!!
ヾ( ̄▽ ̄)Bye~Bye~