参考链接
https://xiaolincoding.com/network/3_tcp/tcp_down_and_crash.html
https://xiaolincoding.com/network/3_tcp/tcp_unplug_the_network_cable.html#%E6%8B%94%E6%8E%89%E7%BD%91%E7%BA%BF%E5%90%8E-%E6%9C%89%E6%95%B0%E6%8D%AE%E4%BC%A0%E8%BE%93
关键词:
- 没有开启 keepalive;
- 一直没有数据交互;
- 进程崩溃;
- 主机崩溃
1. 先了解 TCP keepalive

在Linux中查询TCP保活时间的命令
sysctl -A | grep keep
- 如果对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 如果对端主机崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
所以,TCP 保活机制可以在双方没有数据交互的情况,通过探测报文,来确定对方的 TCP 连接是否存活。(应用程序若想使用 TCP 保活机制需要通过 socket 接口设置 SO_KEEPALIVE 选项才能够生效,如果没有设置,那么就无法使用 TCP 保活机制。)
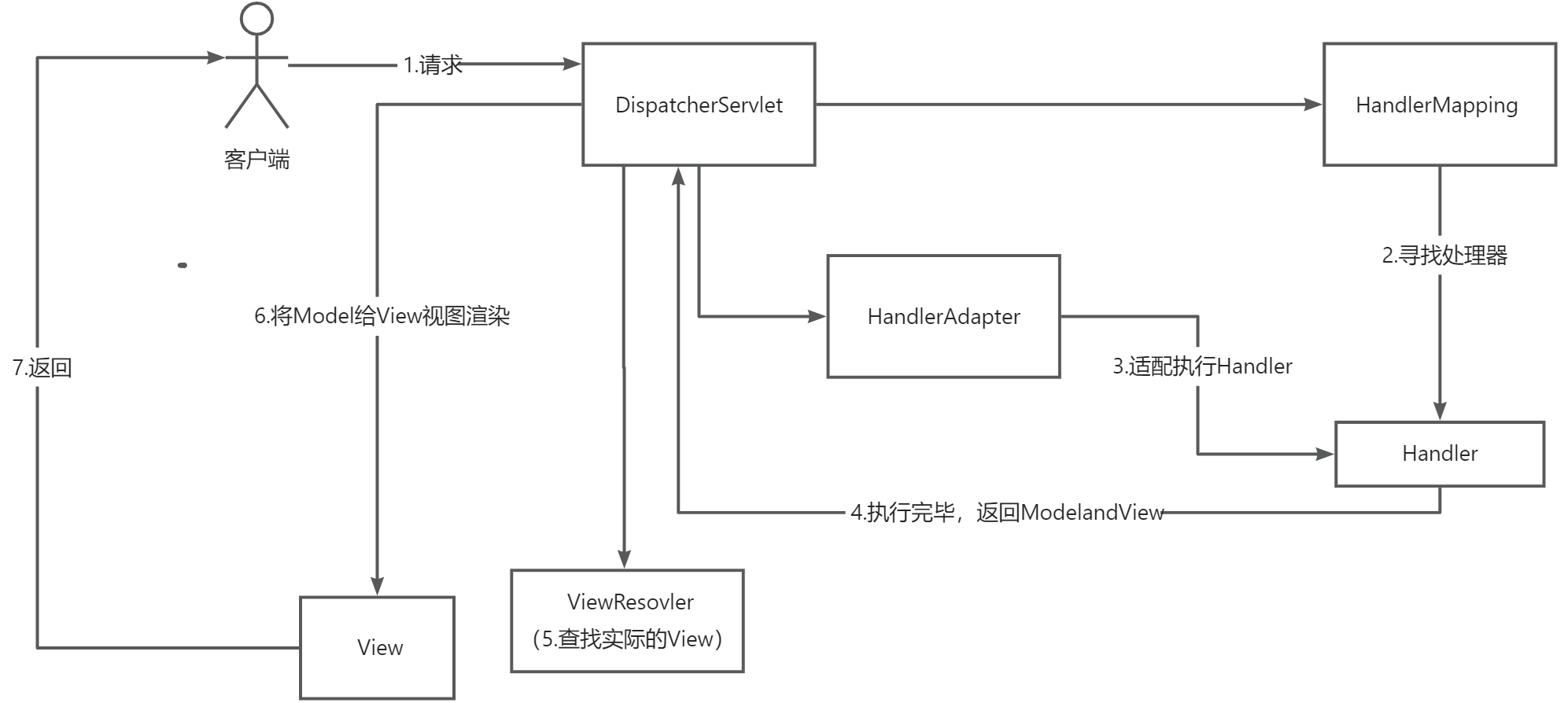
2. TCP 连接,客户端/服务端进程崩溃会发生什么?
结论:如果「客户端/服务端进程崩溃」,客户端/服务端的进程在发生崩溃的时候,操作系统是可以感知的到的,内核会发送 FIN 报文,与对方进行四次挥手。
- TCP 的连接信息是由内核维护的,所以当服务端或者客户端的进程崩溃后,内核需要回收该进程的所有 TCP 连接资源,于是内核会发送第一次挥手 FIN 报文,后续的挥手过程也都是在内核完成,并不需要进程的参与,所以即使客户端/服务端的进程退出了,还是能与对端完成 TCP四次挥手的过程。
- 所以,即使没有开启 TCP keepalive,且双方也没有数据交互的情况下,如果其中一方的进程发生了崩溃,这个过程操作系统是可以感知到的,于是就会发送 FIN 报文给对方,然后与对方进行 TCP 四次挥手。
3. TCP 连接,客户端主机崩溃会发生什么?
「主机宕机」,那么是不会发生四次挥手的,具体后续会发生什么?还要看服务端会不会发送数据?
1. 不管有没有开启TCP keepalive,只要有数据传输:
- 如果服务端会发送数据,由于客户端已经不存在,收不到数据报文的响应报文,服务端的数据报文会超时重传,当重传总间隔时长达到一定阈值(内核会根据 tcp_retries2 设置的值计算出一个阈值)后,会断开 TCP 连接。
至于重传问题,参考链接
https://xiaolincoding.com/network/3_tcp/tcp_feature.html#%E9%87%8D%E4%BC%A0%E6%9C%BA%E5%88%B6
https://xiaolincoding.com/network/3_tcp/tcp_down_and_crash.html#%E5%AE%A2%E6%88%B7%E7%AB%AF%E4%B8%BB%E6%9C%BA%E5%AE%95%E6%9C%BA-%E4%B8%80%E7%9B%B4%E6%B2%A1%E6%9C%89%E9%87%8D%E5%90%AF
- 在「有数据传输」的场景下的一些异常情况:
1.第一种,客户端主机宕机,又迅速重启,会发生什么?
在客户端主机宕机后,服务端向客户端发送的报文会得不到任何的响应,在一定时长后,服务端就会触发超时重传机制,重传未得到响应的报文。
服务端重传报文的过程中,客户端主机重启完成后,客户端的内核就会接收重传的报文,然后根据报文的信息传递给对应的进程:
如果客户端主机上没有进程绑定该 TCP 报文的目标端口号,那么客户端内核就会回复 RST 报文,重置该 TCP 连接;
如果客户端主机上有进程绑定该 TCP 报文的目标端口号,由于客户端主机重启后,之前的 TCP 连接的数据结构已经丢失了,客户端内核里协议栈会发现找不到该 TCP 连接的 socket 结构体,于是就会回复 RST 报文,重置该 TCP
连接。 所以,只要有一方重启完成后,收到之前 TCP 连接的报文,都会回复 RST 报文,以断开连接。
2.客户端主机宕机,一直没有重启,会发生什么?
服务端超时重传报文的次数达到一定阈值后,内核就会判定出该 TCP 有问题,然后通过 Socket 接口告诉应用程序该 TCP 连接出问题了,于是 服务端的 TCP 连接就会断开。
2. 没有开启 TCP keepalive,且双方一直没有数据交互的情况下:
- 客户端主机崩溃了,服务端是无法感知到的,在加上服务端没有开启 TCP keepalive,又没有数据交互的情况下,服务端的 TCP 连接将会一直处于 ESTABLISHED 连接状态,直到服务端重启进程。
- 所以,我们可以得知一个点,在没有使用 TCP 保活机制且双方不传输数据的情况下,一方的 TCP 连接处在 ESTABLISHED 状态,并不代表另一方的连接还一定正常。
3. 有开启TCP keepalive,服务端在一段时间没有进行数据交互时
- 会触发 TCP keepalive 机制,探测对方是否存在,如果探测到对方已经消亡,则会断开自身的 TCP 连接
对于宕机,大概就是
有数据传输----->考虑到----->重传
有keepalive,无数据传输----->考虑到----->触发 TCP keepalive 机制
都没有----->考虑到----->一直处于 ESTABLISHED 连接状态
4. 拔掉网线后, 原本的 TCP 连接还存在吗?
实际上,TCP 连接在 Linux 内核中是一个名为 struct socket 的结构体,该结构体的内容包含 TCP 连接的状态等信息。当拔掉网线的时候,操作系统并不会变更该结构体的任何内容,所以 TCP 连接的状态也不会发生改变。
小林实验: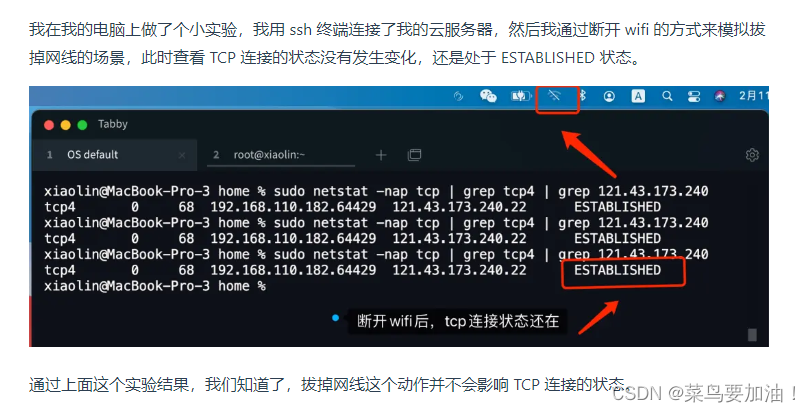
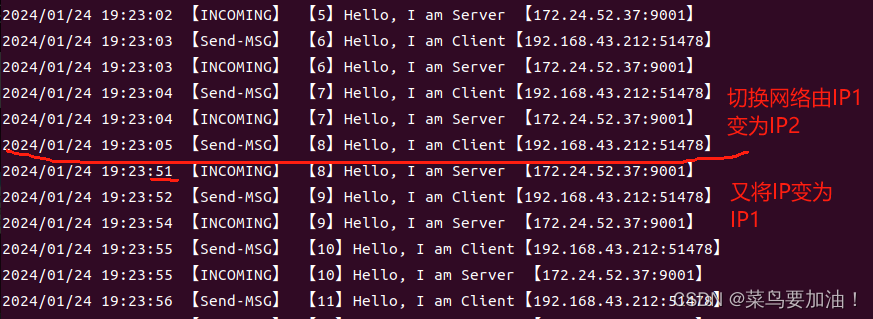
自己之前在实践QUIC的连接迁移的时候,想将TCP作为对比,因此也做了类似的测试:将客户端的IP地址由IP1变为IP2,过一会又将地址变回 IP1,双方又可以发送数据。
客户端:
服务端tcpdump:
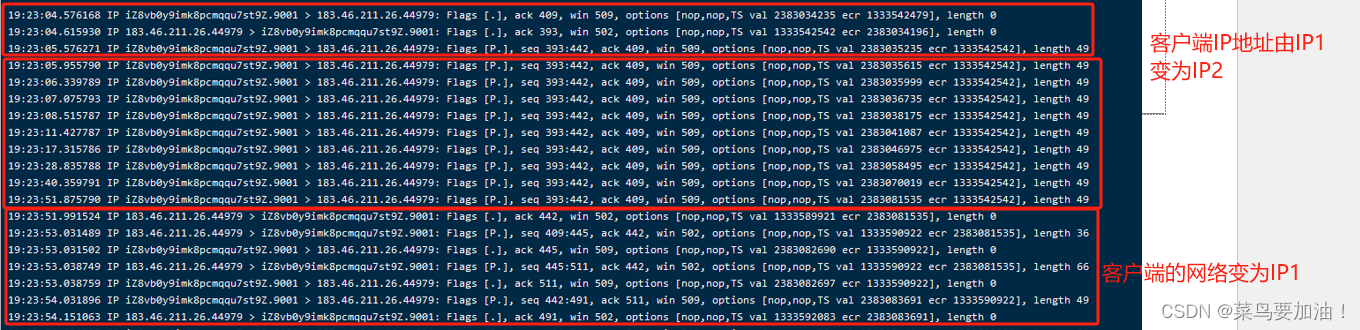
如果在服务端重传报文的过程中,客户端一直没有将IP地址变换为原来的IP1,则服务端超时重传报文的次数达到一定阈值后,内核会根据 tcp_retries2 设置的值,计算出一个 timeout(如果 tcp_retries2 =15,那么计算得到的 timeout = 924600 ms),如果重传间隔超过这个 timeout,则认为超过了阈值,就会停止重传,然后就会断开 TCP 连接。
1. 拔掉网线后,有数据传输
在客户端拔掉网线后,服务端向客户端发送的数据报文会得不到任何的响应,在等待一定时长后,服务端就会触发超时重传机制,重传未得到响应的数据报文。
如果在服务端重传报文的过程中,客户端刚好把网线插回去了,由于拔掉网线并不会改变客户端的 TCP 连接状态,并且还是处于 ESTABLISHED 状态,所以这时客户端是可以正常接收服务端发来的数据报文的,然后客户端就会回 ACK 响应报文。
此时,客户端和服务端的 TCP 连接依然存在的,就感觉什么事情都没有发生。但是,如果在服务端重传报文的过程中,客户端一直没有将网线插回去,服务端超时重传报文的次数达到一定阈值后,内核就会判定出该 TCP 有问题,然后通过 Socket 接口告诉应用程序该 TCP 连接出问题了,于是服务端的 TCP 连接就会断开。
而等客户端插回网线后,如果客户端向服务端发送了数据,由于服务端已经没有与客户端相同四元祖的 TCP 连接了,因此服务端内核就会回复 RST 报文,客户端收到后就会释放该 TCP 连接。
此时,客户端和服务端的 TCP 连接都已经断开了。
2. 拔掉网线后,没有数据传输
针对拔掉网线后,没有数据传输的场景,还得看是否开启了 TCP keepalive 机制 (TCP 保活机制)。
如果没有开启 TCP keepalive 机制,在客户端拔掉网线后,并且双方都没有进行数据传输,那么客户端和服务端的 TCP 连接将会一直保持存在。
而如果开启了 TCP keepalive 机制,在客户端拔掉网线后,即使双方都没有进行数据传输,在持续一段时间后,TCP 就会发送探测报文:
如果对端是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
如果对端主机宕机(注意不是进程崩溃,进程崩溃后操作系统在回收进程资源的时候,会发送 FIN 报文,而主机宕机则是无法感知的,所以需要 TCP 保活机制来探测对方是不是发生了主机宕机),或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
所以,TCP 保活机制可以在双方没有数据交互的情况,通过探测报文,来确定对方的 TCP 连接是否存活。
5. 网络中间节点异常(另一个因素)
在实际网络应用中,两个主机之间的通信往往需要穿越多个中间节点,例如路由器、网关、防火墙等。因此,两个主机之间 TCP 连接的保持同样会受到中间节点的影响,尤其是会受到防火墙(软件或硬件防火墙)的限制。防火墙是一种装置,有多种不同的实现方式(软件实现、硬件设备实现或是软硬件相结合实现),它需要依据一系列规则对进出的信息流进行扫描,并允许安全(符合规则)的信息交互、阻止不安全(违反规则)的信息交互。 防火墙的工作特性决定了要维护一个网络连接就需要耗费较多的资源,并且企业防火墙常常位于企业网络的出入口,长时间维护非活跃的 TCP 连接必将导致网络性能的下降。因此,大部分防火墙默认会关闭长时间处于非活跃状态的连接而导致 TCP 连接断连 。类似的,如果中间节点异常导致来自客户端关闭连接的请求无法传递到服务器端,也将导致服务器端的相应连接发生断连。

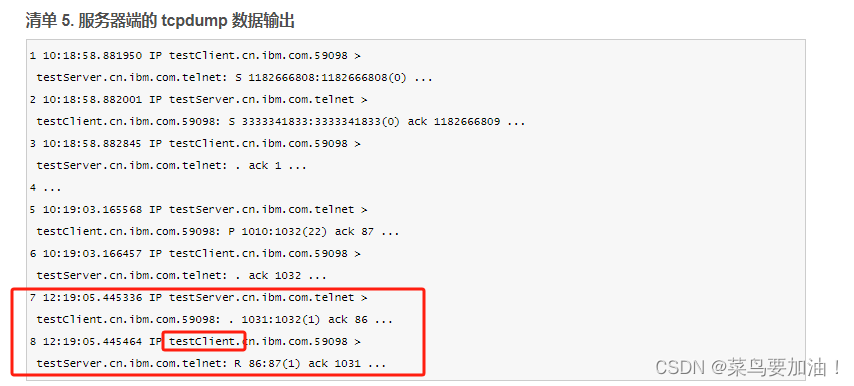
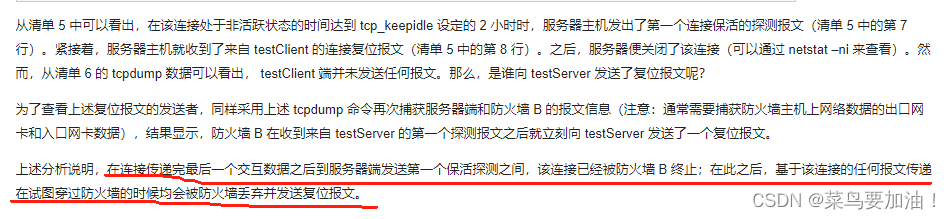
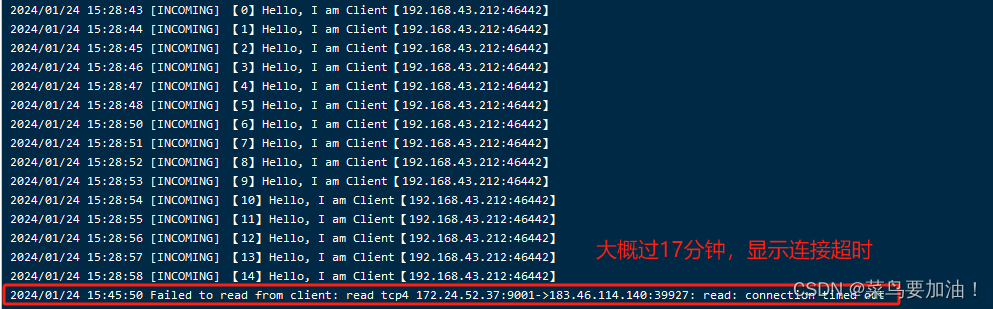
6. TCP keepalive 机制探测的时间太长(附加)
TCP keepalive 是 TCP 层(内核态) 实现的,它是给所有基于 TCP 传输协议的程序一个兜底的方案。
实际上,我们应用层可以自己实现一套探测机制,可以在较短的时间内,探测到对方是否存活。
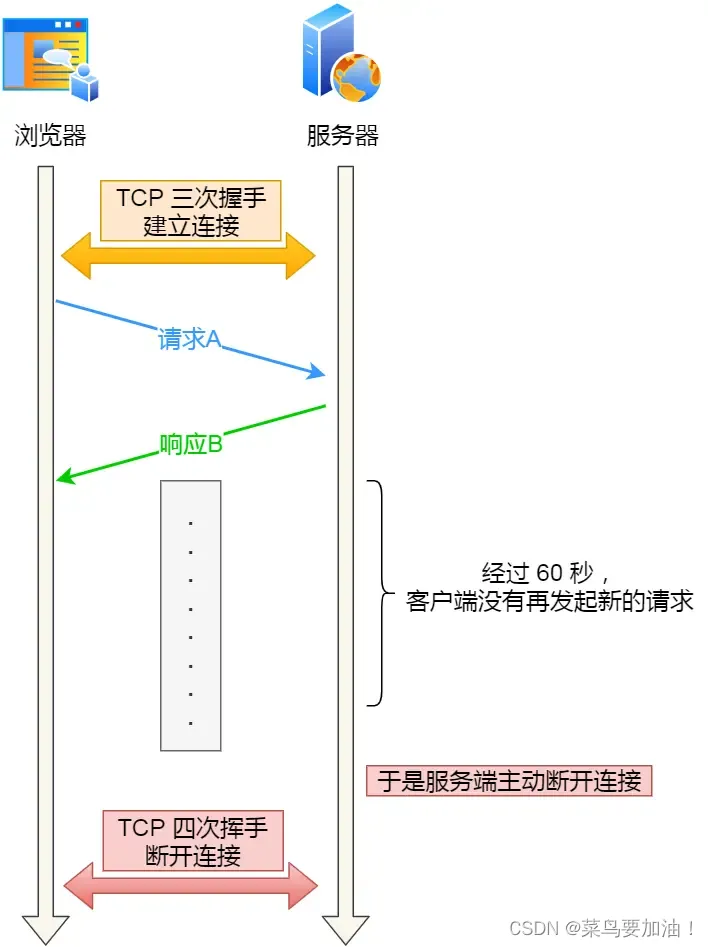
比如,web 服务软件一般都会提供 keepalive_timeout 参数,用来指定 HTTP 长连接的超时时间。如果设置了 HTTP 长连接的超时时间是 60 秒,web 服务软件就会启动一个定时器,如果客户端在完后一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。