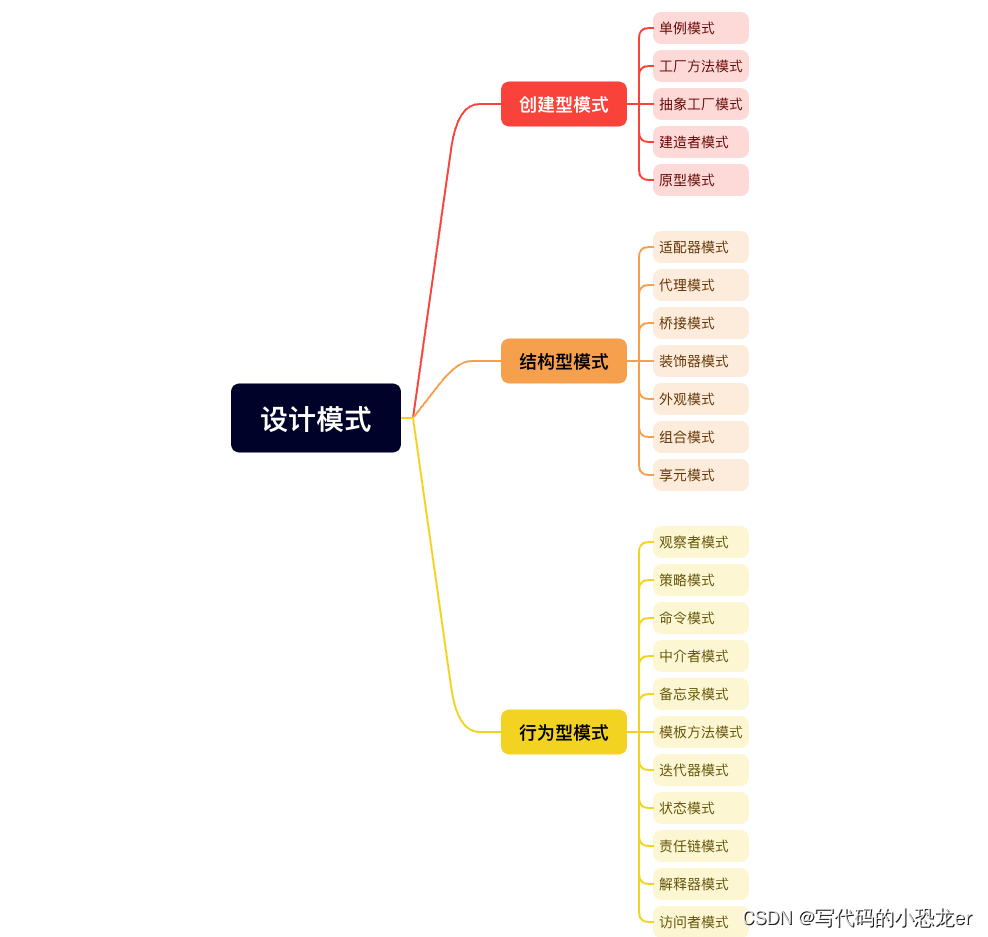
0.思维导图

Kafka是一个分布式的基于发布/订阅模式的消息队列,主要用于大数据实时处理邻域
消息队列分为点对点模式(消费者主动拉取数据,消息收到后清除消息)和发布订阅模式(消费者消费数据之后,不删除数据)
1. 为什么要使用kafka♥♥
- 缓存/消蜂:(解决生产消息和消费消息的处理速度不一致)当生产消息的速度过快时,kafka在中间可以起到一个缓冲的作用,把消息暂存在kafka中,消费者就可以按照自己的节奏来处理。
- 解耦:(接入不同的数据源,发往不同的目的地)消息队列可以作为一个接口层,允许你独立的扩展或修改两边的处理过程,只要确保他们遵守同样的接口约束。
- 异步通信:(允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理他们)很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理他们。
2. 简述kafka的架构♥♥♥

- 一个kafka集群由多个broker组成,一个broker可以有多个topic,一个topic可以分为多个partition,每个partition可以有若干个副本(一个leader,若干个follower)
3. 命令行操作(了解)
- 启动集群:bin/kafka-server-start.sh -daemon config/server.properties
- 关闭集群:bin/kafka-server-stop.sh stop
- 查看所有topic:bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
- 创建topic:bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 3 --partitions 1 --topic first
- 删除topic :bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --topic first
- 发送消息:bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
- 消费消息:bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
4. 生产者流程♥
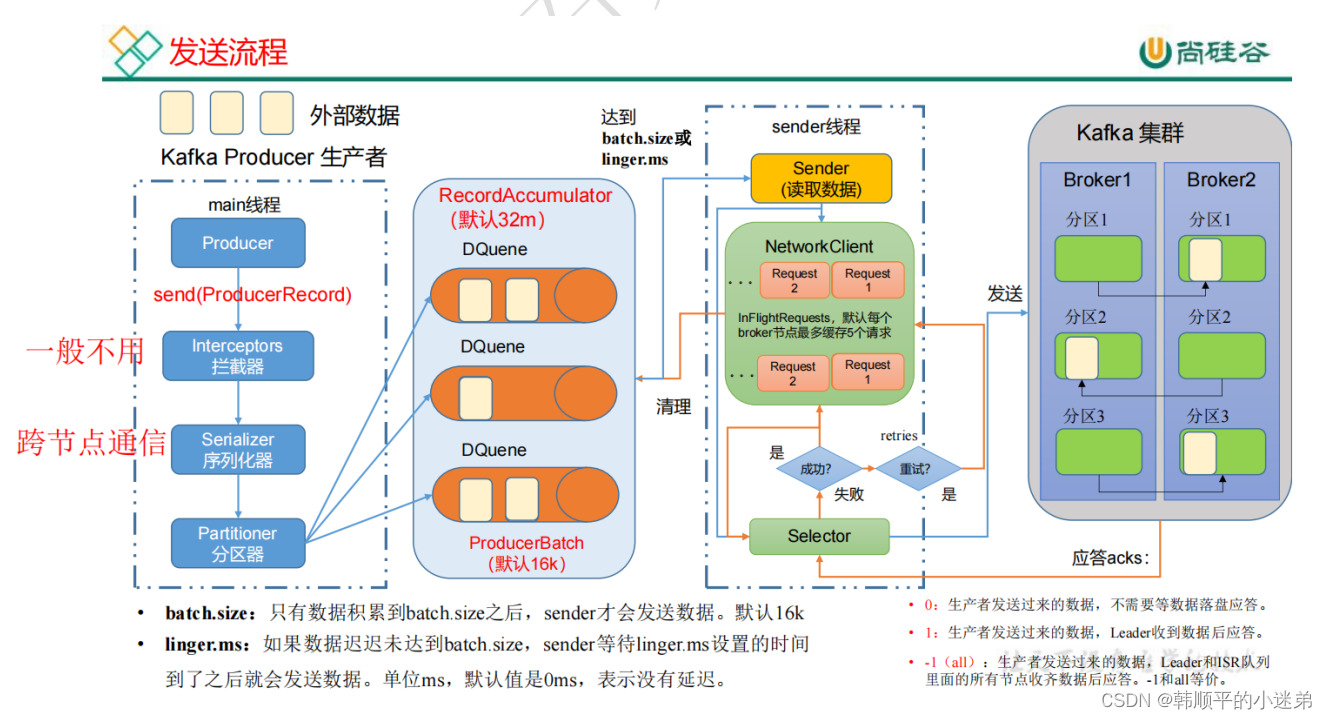
- 在消息发送的过程中,涉及到了两个线程-
main线程和Sender线程。在main线程中创建了一个双端队列RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka Broker。 调优--生产者如何提高吞吐量- batch.size:批次大小,默认16K
- linger.ms:等待事件,修改为5-100ms
- compression.type:压缩snappy
- RecordAccumulator:缓冲区大小,修改为64M
5. 简述kafka的分区策略♥
分区好处:便于合理使用存储资源;提高并行度
生产者策略
- 直接指明partition的值
- 没有指明partition的值但有key,那么分区值=key的hash值与topic的分区数取余
- 没有指明partition也没有key,kafka采用sticky partition(粘性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区达到了batchsize大小或者达到了默认发送时间,kafka就会再次选择一个分区使用,只要与上一次分区不同就可以。
- 自定义分区器:实现Partitioner接口,重写partition方法。
消费者分区策略【一个消费者组有多个消费者,一个topic有多个分区,所以就会出现到底由哪个consumer来消费哪个partition的数据】,由partition.assignment.strategy参数来设置
Range(默认):【针对一个topic】首先对同一个topic里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序,然后用分区数除以消费者数,得到每个消费者消费几个partition,然后按分区顺序连续分配若干个partition,除不尽的话前面几个消费者就会多分配一个分区的数据。
- 问题:如果只是针对1个topic,消费者0多消费一个分区影响不大;但是如果有N个topic,那么消费者0就会多消费N个分区,那么就容易发生数据倾斜。
- 再平衡:挂掉一个消费者之后,45秒以内重新发送消息,此时剩余的消费者暂时不能消费到挂掉的消费者应该消费的分区,等到了45秒以后,消费者就真正挂掉了,此时会把它应该消费的分区数都分配给消费者1或者消费者2。
RoundRobin:【针对所有分区】首先将所有partition和consumer按照一定顺序排列,然后按照consumer依次分配排好序的partition,若该consumer没有订阅即将要分配的主题,那么直接跳过,继续向下分配。
- 再平衡:也会进行轮询
sticky:尽量均匀的分配分区给消费者(随机),粘性体现在在执行新的分配之前,考虑上一次的分配结果,尽量少的变动,这样就可以节省大量的开销。
- 再分配:均匀分配
6. kafka是如何保证数据不丢失和数据不重复♥♥♥
保证数据不丢失:
生产端:
- producer发送数据到kafka的时候,当kafka接收到数据之后,需要向producer发送ack确认收到,如果producer接收到ack,才会进行下一轮的发送,否则重新发送数据
- 这里面有一个问题:什么时候发送ack呢?
- kafka提供了3中ack应答级别:ack=0,生产者发送过来的数据,不需要等数据落盘就会应答,一般不会使用;ack=1,生产者发送过来的数据,Leader收到数据后就会应答,因为这个级别也会丢失数据,所以一般用于传输普通日志;ack=-1(默认级别),生产者发送过来的数据,Leader和ISR队列里面的所有节点收到数据后才会应答,不会丢失数据,一般用于传输和钱相关的数据,那么为什么提出了这个ISR呢?因为如果我们等待所有的follower都同步完成,才发送ack,假设有一个follower迟迟不能同步,那怎么办呢?难道要一直等吗?因此就出现了ISR队列,这里面会存放和leader保持同步的follower集合,如果长时间(30s)未和leader通信或者同步数据,就会被踢出去。
消费端:
- 消费者消费数据的时候会不断提交offset,就是消费数据的偏移量,以免挂了,下次可以从上次消费结束的位置继续消费,这个offset在0.9版本之前,保存在Zookeeper中,从0.9版本开始,consumer将offset保存在Kafka一个内置的topic中(consume_offsets)。
broker端:每个partition都会有多个副本
- 每个broker中的partition我们一般会设置有replication(副本)的个数,生产者写入的时候首先根据分区分区策略(有partition按照partition,有key按key,都没有轮询)写入到leader中,follower(副本)再跟leader同步数据,这样有了备份,也可以保证消息数据不丢失。
保证数据不重复:如何保证exactly once语义?
- 问题:当我们把ack级别设置为-1之后,假设leader收到数据并且同步ISR队列之后,在返回ack之前leader挂掉了,那么producer端就会认为数据发送失败,再次重新发送,那么此时集群就会收到重复的数据,这样在生产环境中显然是有问题的。
- 0.11版本之后,kafka提出了一个非常重要的特性,幂等性(默认是开启的),也就是说无论producer发送多少次重复的数据,kafka只会持久化一条数据,把这个特性和至少一次语义(ack设置为-1 + 副本数 >= 2 + ISR最小副本数 >= 2)结合在一起,就可以实现精确一次性(既不丢失又不重复)。大致介绍一下它的底层原理:在producer刚启动的时候会分配一个PID(单调自增的),broker会对<PID, partition ,SeqNum> 做缓存,也就是把它当作主键,如果有相同主键的消息提交时,broker只会持久化一条数据。但是这个机制只能保证单会话的精准一次性,如果想要保证跨会话的精准一次性,那么就需要事务的机制来进行保证(producer在使用事务之前,必须先自定义一个唯一的事务id,这样,即使客户端重启,也能继续处理未完成的事务;并且这个事务的信息会持久化到一个特性的主题中)
如何保证精确一次性的消费?
问题:
- 重复消费:自动提交offset;consumer每5s自动提交offset,如果提交后2s,consumer挂掉了,再次重启consumer,则从上一次提交的offser处继续消费,导致重复消费
- 漏消费:手动提交offset;消费者消费的数据还在内存中,消费者挂掉了,导致漏消费。
解决: 手动提交offset + 采用消费者事务,比如mysql,也就是说下游的消费者必须支持事务(能够回滚)
7. kafka中的数据是有序的吗,如何保证有序的呢?♥
kafka只能保证partition内是有序的,但是partition间的有序是没办法保证的
解决办法:
- 设置topic有且只有一个partition
- 从业务上把需要有序的打到同一个partition【指定相同的分区号,或者使用相同的key】
partition 内有序性的保证:
- 1.x版本之前:将允许最多没有返回ack的次数参数设置为1
- 1.x版本之后:如果开启了幂等性,那么只要设置这个参数小于等于5就可以了
- 原因:启用幂等后,kafka服务端会缓存producer发来的最近5个request的元数据,因此无论如何,都可以保证最近5个request的数据都是有序的
kafka如何实现消息有序的?
- 生产者: 通过分区的leader副本负责数据以先进先出的顺序写入,来保证消息顺序性。
- 消费者:同一个分区内的消息只能被一个消费者组(group)里的一个消费者消费,保证分区内消费有序。
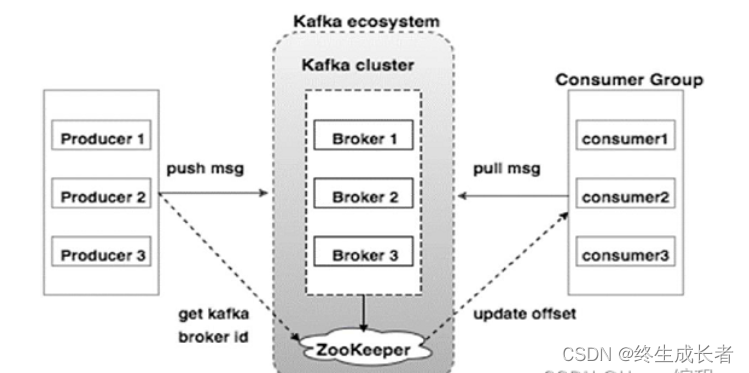
8. zookeeper在kafka中的作用有哪些
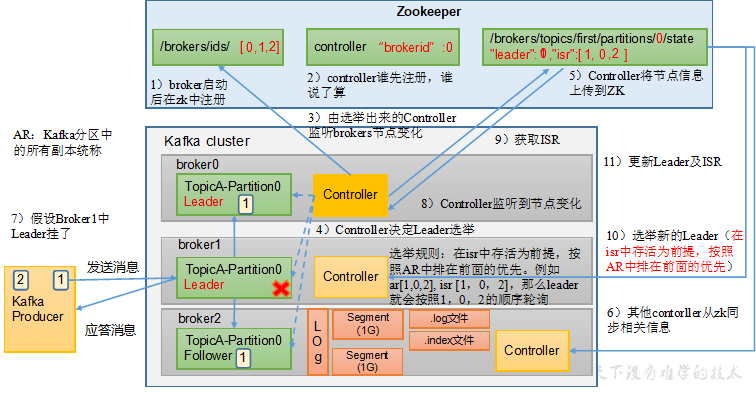
- 记录有哪些服务器 /brokers/ids
- 记录谁是leader,有哪些服务器可用{“leader”:0,“isr”:[0,1,2]}
- 选举controller,kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
- 记录消费者数据的offset,在消费者消费数据的时候,需要定时的将分区消息的消费进度offset记录到zookeeper中(0.9版本之前)【之所以后面将offset提交到系统主题中,是因为存放在zookeeper中需要进行频繁的通信】
9. broker工作流程
kafka分区中的所有副本统称为AR,AR=ISR + OSR
ISR:表示和leader保持同步的Follower集合。如果Follow长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR,默认30s。
OSR:从ISR踢出的follower。
Kafka集群中有一个broker的Controller会被选举为Controller Leader,负责管理集群broker的上下线、所有topic的分区副本分配和leader选举等工作;Controller的信息同步工作依赖于zookeeper。
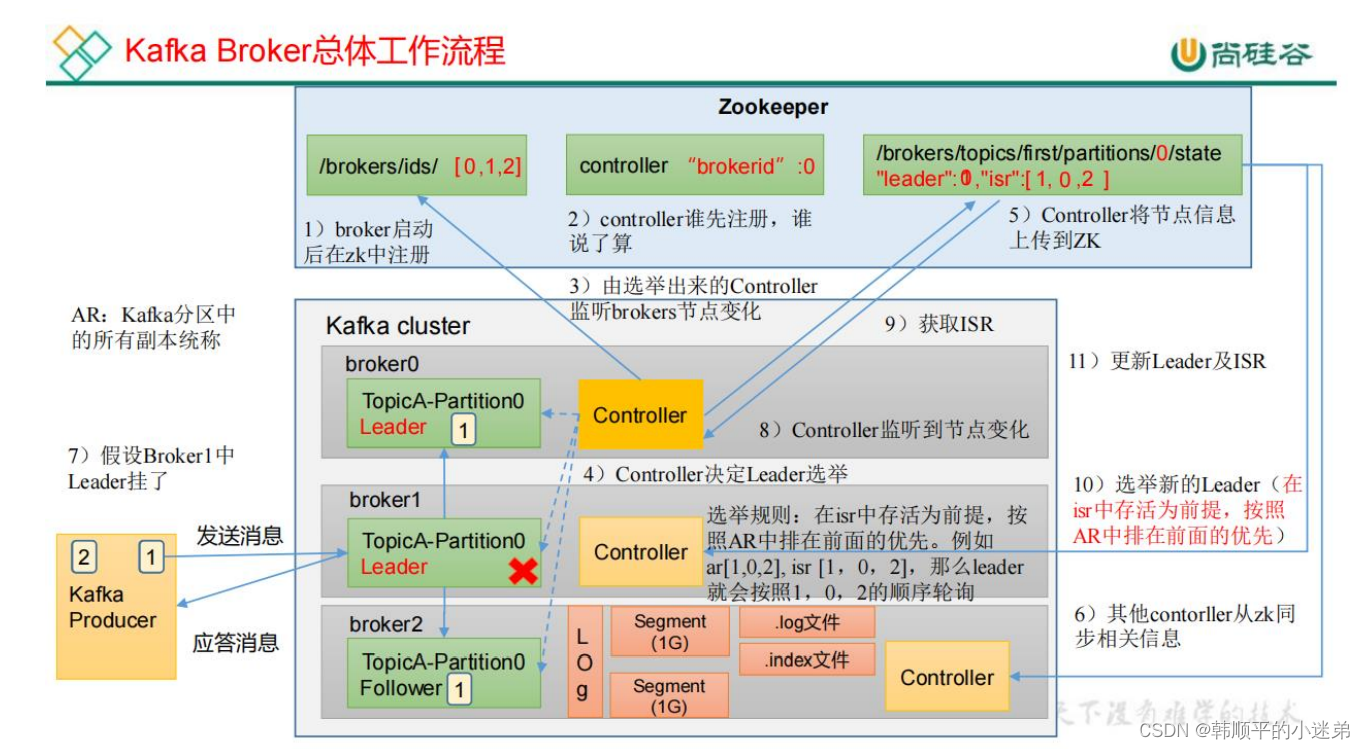
- 熟悉一下leader选举的流程
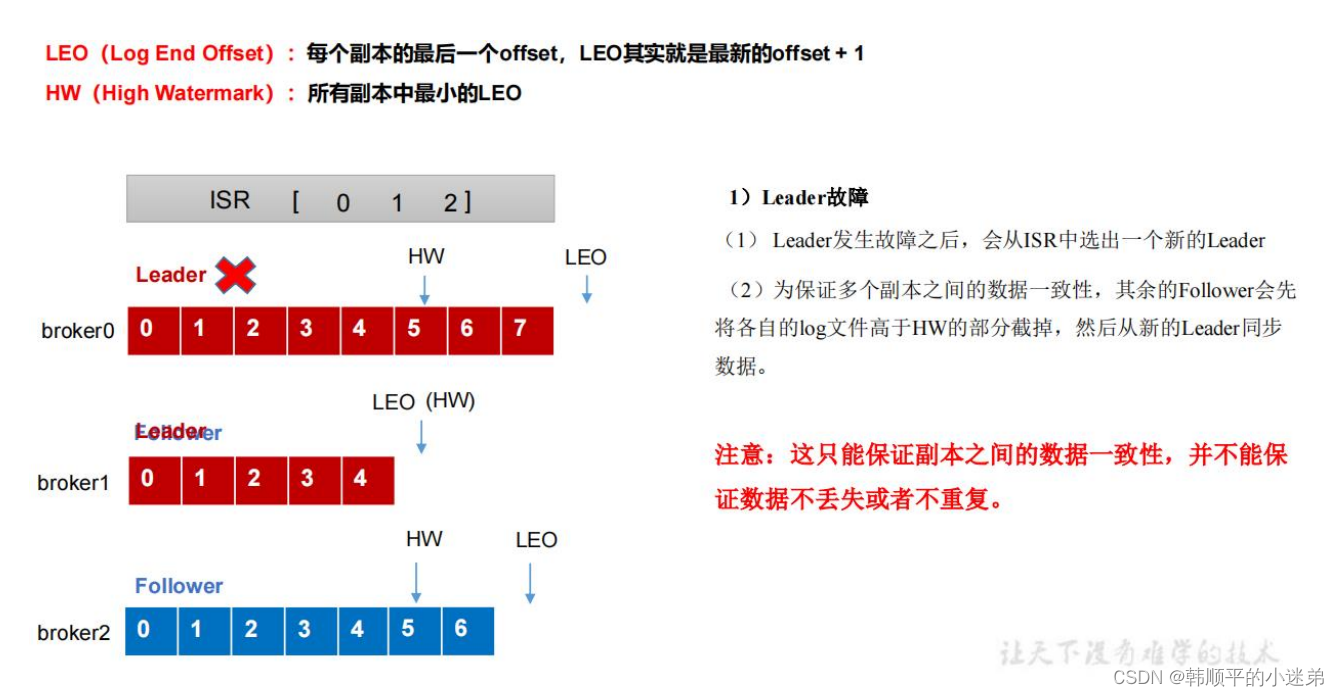
- leader挂了或者follower挂了怎么办?

10. 简述kafka消息的存储机制♥♥♥
kafka中的消息就是topic,topic只是逻辑上的概念,而partition才是物理上的概念,每个partition会对应一个log文件,它存储的就是producer生产的数据。生产者生产的数据会不断追加到log文件中,日过log文件很大了,就会导致定位数据变慢,因此卡夫卡会将大的log文件分为多个segment,每个segment会对应.log文件和.index文件和.timeindex文件,.log存储数据,.index存储偏移量和索引信息,.timeindex存储时间戳索引信息。它的存储结构大概就是这样的【log.segment.bytes=1g;指log日志划分成块的大小】
- 注意:
- .index 为稀疏索引,大约每往log文件写入4kb数据,会往index文件写入一条索引。
- log.index.interval.bytes=4kb
- Index文件中保存的offset为相对offset,这样能确保offset的值所占空间不会过大
- Kafka中默认的日志保存时间为7天log.retention.hours。
11. kafka的数据是放在磁盘上还是内存上,为什么速度会块♥♥
- 10说到了放在本地log文件中,所以是放在磁盘上
- 速度块有四个原因:(Kafka每秒可以处理一百万条以上的消息,吞吐量达到每秒百万级。那么Kafka为什么那么高的吞吐量呢?)
- Kafka本身是分布式集群,并且采用分区技术,并行度高
- 读数据采用稀疏索引,可以快速定位到要消费的数据
- 写log文件的时候,一直是在追加到文件末端,是顺序写的方式,官网中说了,同样的磁盘,顺序写能达到600M/s,而随机写只要100kb/s
- 实现了零拷贝技术,只用就磁盘文件的数据复制到页面缓冲区一次,然后将数据从页面缓冲区直接发送到网络中,这样就避免了在内核空间和用户空间之间的拷贝。
- 补充:传统的读取数据发送到网络中的步骤?
- 操作系统将数据磁盘文件读取到内存空核的页面进行缓存
- 应用程序将数据从内核空间读入到用户缓冲区【×】
- 应用程序将读取到的数据写回到内核空间并放入socket缓冲区【×】
- 操作系统将数据从socket缓冲区复制到网卡接口,此时数据才能通过网络进行发送。
12. kafka消费方式
- 分为两种消费方式:
- pull模式:主动从broker中拉取数据,可以根据消费者的消费能力以适当的速率消费消息
- push模式:Kafka没有采用这种方式,因为由broker决定消息发送速率,很难适应所有消费者的消费速率。
Kafka采用pull模式,但是仍然有一个不足:如果kafka中没有数据,消费者可能会陷入循环中,一直返回空数据。(于是又提出了timeout机制)
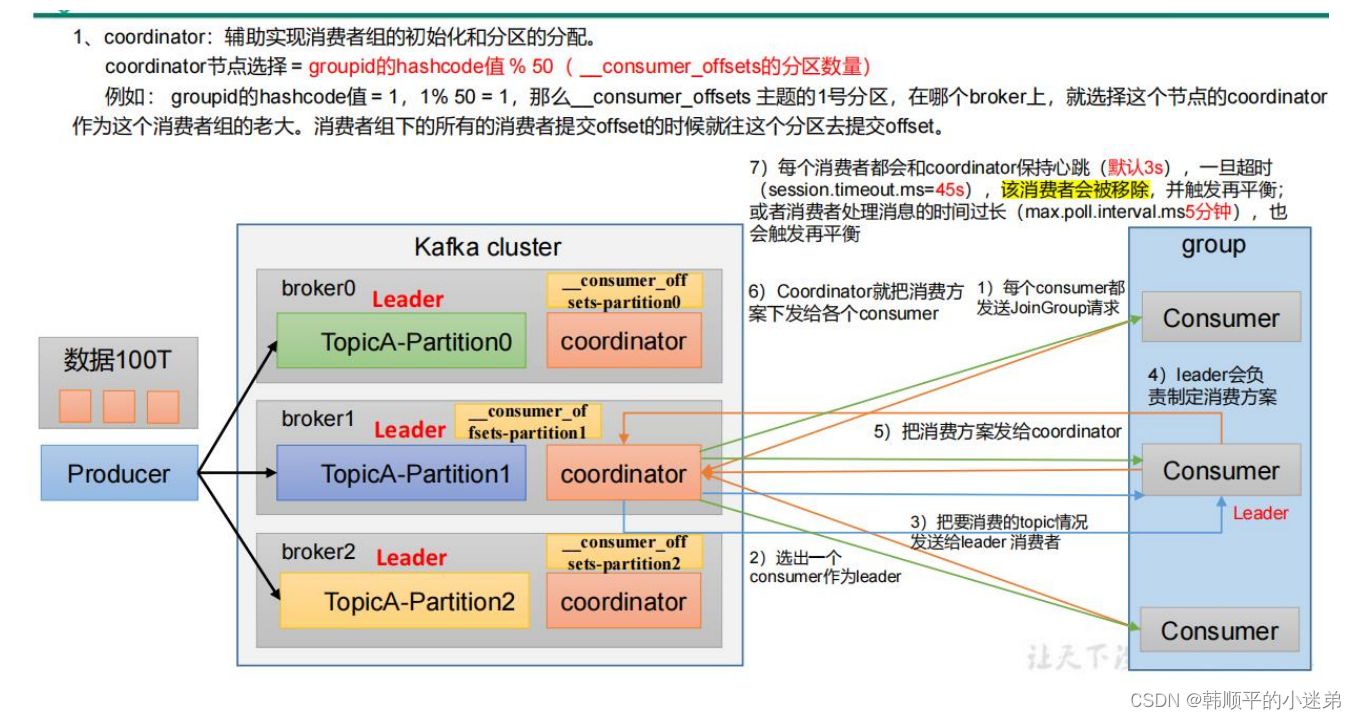
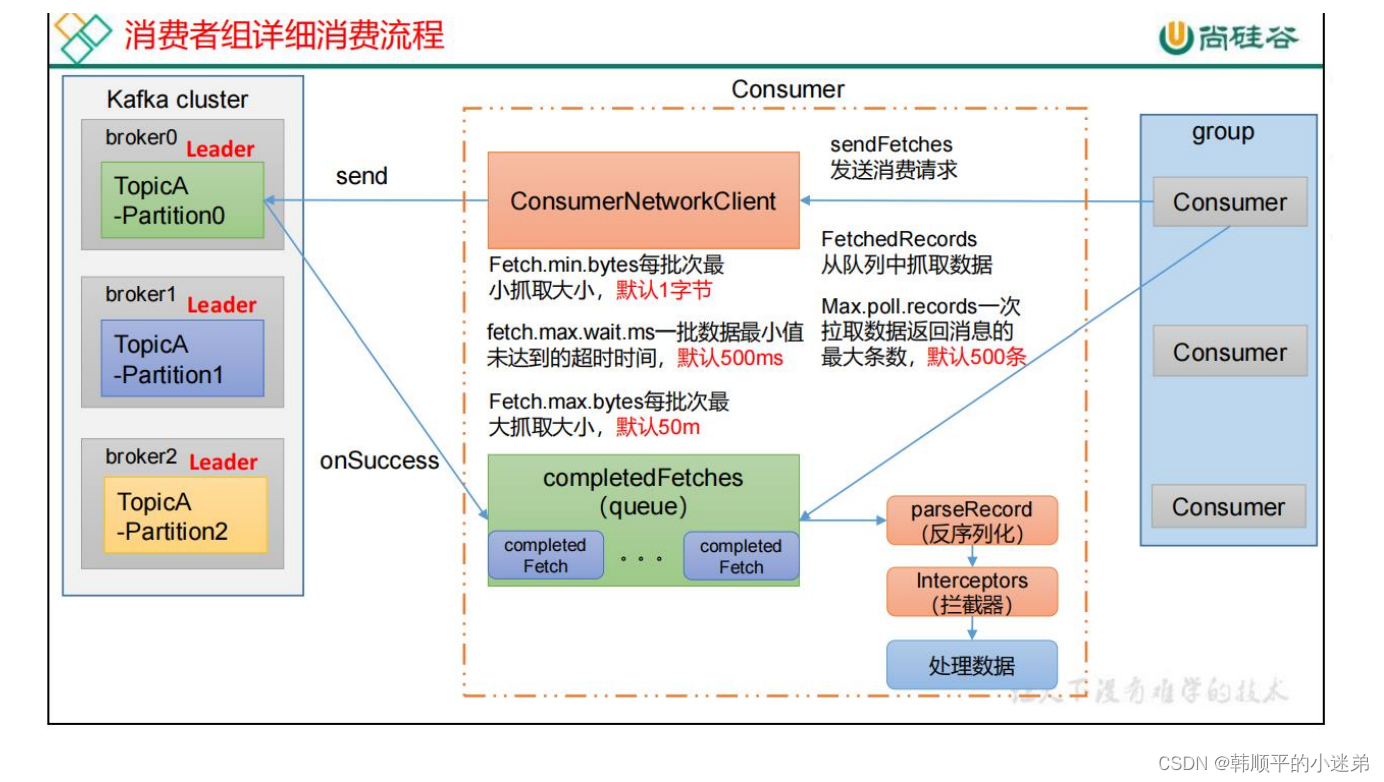
13. kafka消息数据积压,消费者如何提高吞吐量
- 如果是Kafka消费能力不足,则可以考虑增加topic的分区数,并且同时提升消费者组的消费者数量,消费者数=分区数。(两者缺一不可)
- 如果是下游的数据处理不及时,提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。
- fetch.max.bytes=50M
- max.poll.records=500条
14. 你知道kafka单条日志传输大小吗
默认为单条消息最大值是1M,但是在我们应用场景中,常常会出现一条消息大于1M的情况,如果不对Kafka进行配置,则会出现生产者无法将消息推送到Kafka中或消费者消费不到Kafka里面数据的情况。我们可以配置两个参数:一个是副本的最大值,一个是单条消息的最大值,来解决消息最大限制的entire
- broker端接收每个批次消息最大值:message.max.bytes=1M
- 生产者发往broker每个请求消息最大值(针对topic):max.request.size=1M
- 副本同步数据每个批次消息最大值:replica.fetch.max.bytes=1M
需要注意一点:副本的最大值一定要大于单个消息的最大值,否则就会导致数据同步失败。
15. kafka为什么同一个消费者组的消费者不能消费相同的分区♥
因为这样可能会消费到重复的消息,因为kafka的log文件对应的数据都会存储自己的偏移量,而它是按照消费者组、主题、分区来进行区分的,那么同一个消费者组中的消费者使用的就是同一份偏移量,这样就很容易消费到重复的消息。





















![【MIMO 从入门到精通】[P9]【What is beamforming in 5G NR】](https://img-blog.csdnimg.cn/direct/af8337e026394c3780d5e3bcceec1d00.gif)