目录
前言
在当今信息爆炸的时代,知识图谱成为理解和组织海量信息的有效工具之一。而在知识图谱的实际应用中,关系型数据库的使用变得愈发重要。本文将探讨基于关系型数据库的知识图谱存储,着重于图结构数据的关系存储、物理结构、性能问题和图的查询问题。
1 图结构数据的关系存储
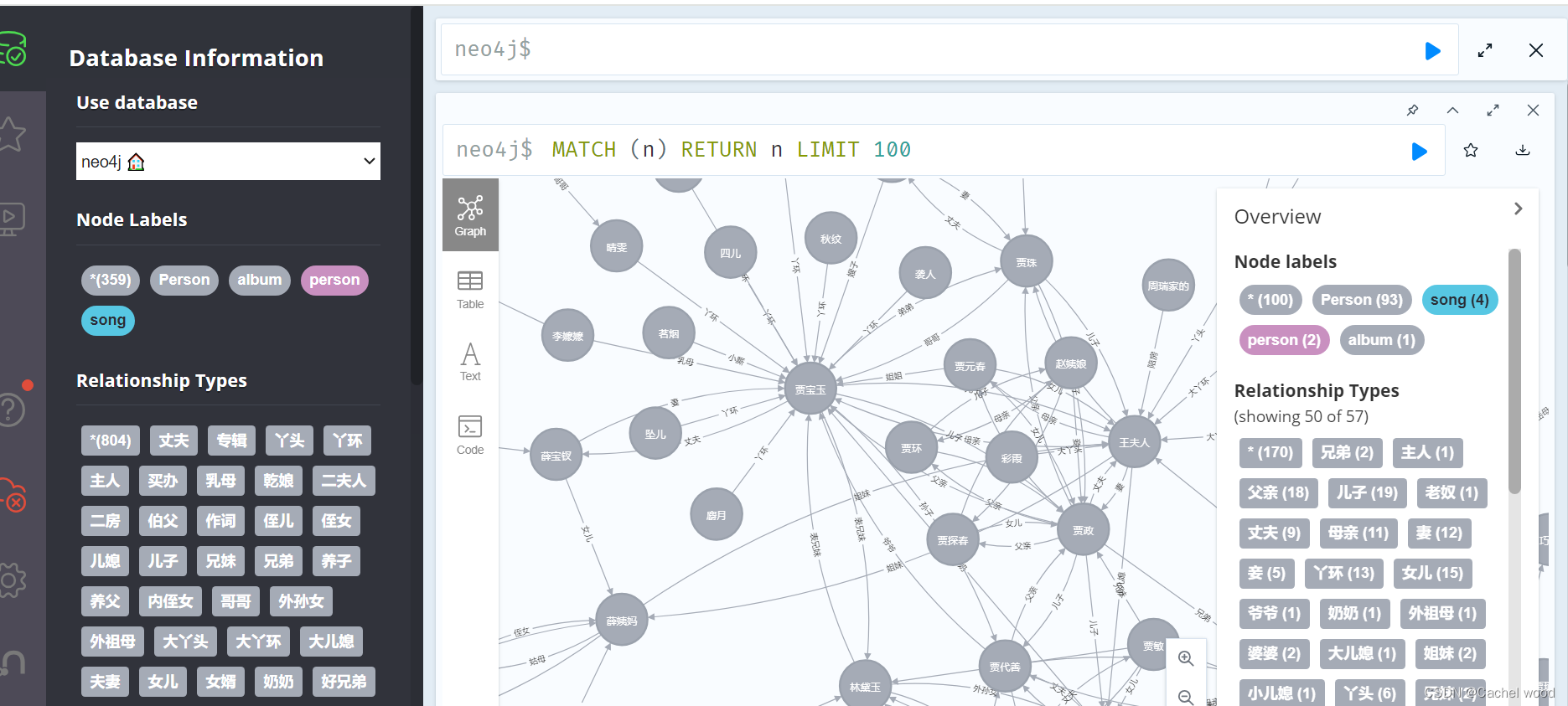
知识图谱的本质是图结构数据,其构建和存储方式涉及到多种图模型,其中包括属性图、RDF图模型等。引人注目的是Wikidata,一个广泛应用的知识图谱实现,其选择将MySQL作为底层存储引擎。这引发了一个有趣而实际的问题:关系型数据库如何有效地存储和管理图结构数据。
1.1 Wikidata与MySQL的结合

Wikidata作为维基媒体项目的一部分,是一个多语言知识图谱,包含着丰富的实体关系和属性信息。其背后的技术选择MySQL作为存储引擎,这使得我们可以从实际应用中学习关系型数据库在知识图谱中的实践。
1.2 关系型数据库的优势与挑战
关系型数据库在处理复杂结构化数据上具有强大的能力,提供了标准SQL查询语言,适用于复杂的数据关联操作。
知识图谱的本质是图形结构,而关系型数据库的表格结构与图形结构并不完全吻合,这导致了一些性能和模型匹配的挑战。
Wikidata的选择为我们提供了一个启示,即关系型数据库可以通过合适的映射和存储策略来胜任知识图谱的存储需求。这也提示了我们在实际应用中需要权衡关系型数据库的优势与图结构数据的特点,选择合适的存储方式以满足性能和灵活性的需求。
2 选择数据库需要考虑的三个问题
2.1 存储的物理结构
在知识图谱的存储中,不同的物理结构影响着数据的存储效率和查询性能。
Triple Store这是一种简单的存储方式,直接将三元组存储,但可能会面临空值问题。这种模型适用于简单的图结构,但在处理大规模、稀疏的数据时效率可能较低。
属性表存储以实体类型为基础,通过关联减少JOIN操作,类似于关系数据库的存储方式。这种方式在处理属性较多的场景中可能更为灵活,但仍需要注意关联操作的性能开销。
二元表将三元组按属性分组存储,避免了空值问题,同时提高了INSERT操作的效率。这种方式尤其适用于大规模图结构的存储,减少了数据冗余。
2.2 存储的性能问题
不同的存储方式对性能产生着直接的影响,需要根据具体需求权衡各自的优劣。
Triple Store虽然简单,但其查询性能可能相对较低,特别是在复杂查询和大规模数据的情况下。对于需要频繁查询的应用,这可能成为一个瓶颈。
二元表通过按属性分组存储,可以提高查询性能,特别是对于特定属性的查询。这种方式在读取性能上有优势,但对于涉及多属性的查询可能存在一定挑战。
2.3 图的查询问题
图的查询通常使用SPARQL查询语言,不同的存储方式会对查询性能产生影响。

SPARQL查询针对RDF数据的查询语言,支持复杂的图查询。在选择存储方式时,需要考虑其对SPARQL查询的适配性和性能影响。全索引结构可能更适用于提高SPARQL查询的效率。
通过合理选择存储方式、建立索引、优化查询语句等手段,可以提高图查询的性能。对于大规模知识图谱,性能优化显得尤为重要,以确保系统的实时响应性。
综合考虑存储的物理结构、性能问题和图的查询问题,选择适合具体应用场景的存储方式至关重要。在实践中,不同的知识图谱项目可能需要根据数据量、查询需求等因素做出不同的选择,以达到最优的性能和效率。
3. 不同的存储方式
3.1 Triple Store

Triple Store是一种简单而直接的存储方式,将图结构的数据以三元组的形式直接存储。尽管这种方式操作简便,但也带来了一些潜在的问题。
最显著的问题之一是可能面临空值和性能问题。对于复杂的查询和大规模数据,直接存储三元组的方式可能导致查询效率不尽如人意,而且空值的处理可能需要额外的机制。
3.2 属性表存储
属性表存储以实体类型为基础,减少JOIN操作,类似于关系数据库的存储方式。这种模型在处理具有多个属性的实体时具有一定的灵活性。
JOIN操作减少。通过将实体的属性存储在同一表中,减少了与关系型数据库中的JOIN操作相关的性能开销。这种方式在复杂关联关系较多的情况下可以提高查询效率。
3.3 二元表
二元表的存储方式将三元组按属性分组,避免了空值问题,并且相对于Triple Store具有更高的INSERT操作效率。
通过按属性分组存储,可以有效地避免空值的问题,提高数据的完整性。这对于具有稀疏属性的图结构尤为重要。
高效的INSERT操作。二元表的设计使得插入新数据时更为高效,尤其适用于动态更新频繁的知识图谱。
3.4 全索引结构
全索引结构采用RDF-3X和Hexastore等技术,建立六种索引(SPO, SOP, PSO, POS, OPS, OSP),优化不同查询模式,提高查询性能。

全索引结构通过建立多种索引,能够更好地适应不同的查询模式,提高查询效率。这种方式特别适用于需要支持多样化查询的应用场景。
选择适合知识图谱应用的存储方式需要综合考虑不同的因素,包括数据结构、查询需求和性能要求。在实际应用中,可能需要根据具体情况选择Triple Store、属性表存储、二元表或全索引结构,以达到最佳的性能和灵活性。
结语
基于关系型数据库的知识图谱存储涉及多个方面的考虑,包括物理结构、性能问题和查询问题。选择合适的存储方式需根据具体应用场景和性能需求来权衡。本文深入研究了Triple Store、属性表存储、二元表和全索引结构等存储方式,为实际应用提供了一些建议。未来,随着技术的不断发展,基于关系型数据库的知识图谱存储将面临新的挑战和机遇。