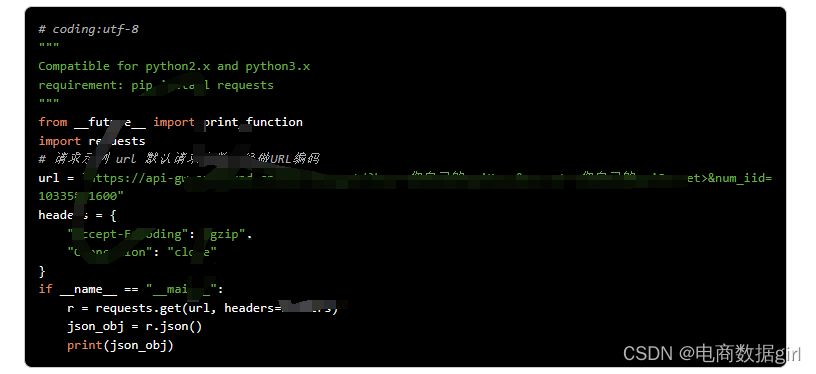
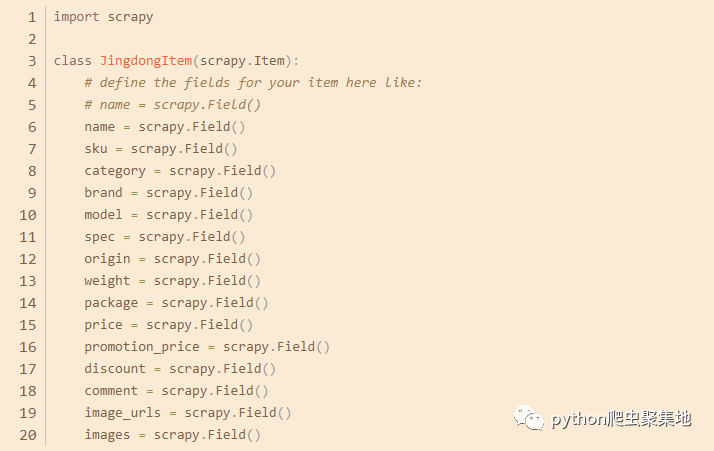
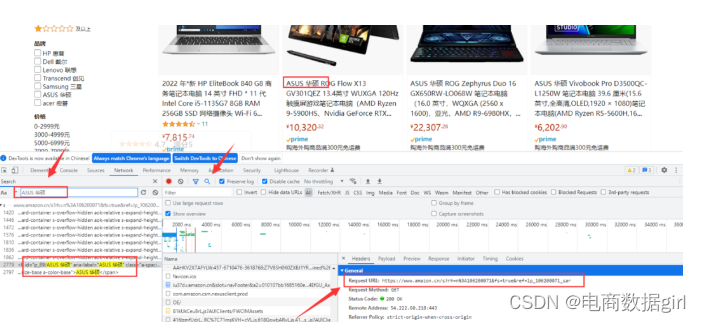
首先,我们来说说什么是爬虫。就是通过自动化技术去访问网站上的数据,把需要的信息提取出来,进行数据分析和处理的过程。这种技术可以大规模地获取数据,极大地提高了信息的获取效率。
接下来,我为大家分门别类地列出了100个爬虫实
战案例。无论你是喜欢编程、还是想要爬取某些特定的信息,这些都会是你的福音!
1.抓取电商平台上的商品详情价格数据

taobao.item_get
公共参数
请求地址: 电商数据API接口测试
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
请求参数
请求参数:num_iid=652874751412&is_promotion=1
参数说明:num_iid:淘宝商品ID
is_promotion:是否获取取促销价
响应参数
Version: Date:2022-04-04
| 名称 | 类型 | 必须 | 示例值 | 描述 |
|---|---|---|---|---|
item |
item[] | 1 | 宝贝详情数据 |
2.爬取某个博客网站上的文章
3.获取某个特定网站的用户评价
4.爬取某个论文网站的所有论文摘要
5.抓取某个社交媒体平台上的用户信息
6.爬取某个视频平台上的视频列表
7.抓取某个音频网站上的音乐列表
8.获取某个在线商城上某个特定商品的价格
9.爬取某个天气网站上的天气数据
还有更多实际应用案例等你来探索哦~
最后,提醒大家一点:在进行爬虫操作时,一定要注意爬虫的合规性,不要涉及到侵犯他人隐私或违法行为