什么是搜索引擎优化(SEO)
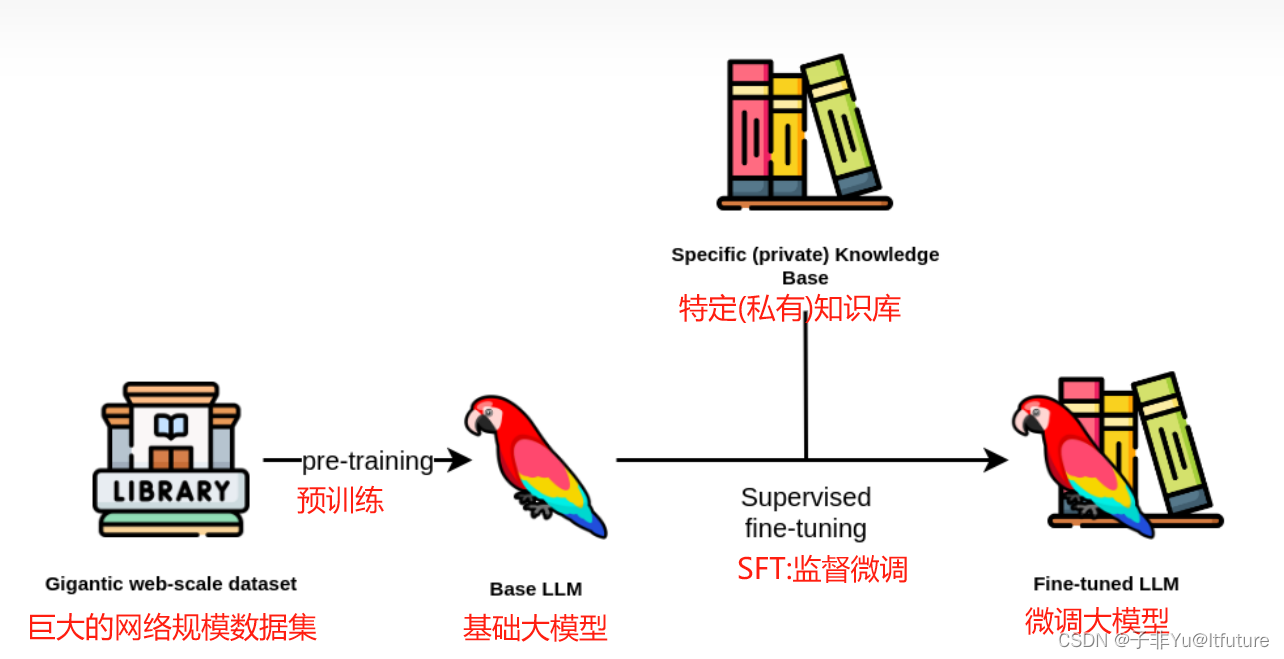
搜索引擎优化(SEO)是通过优化网站内容和结构,提高网站在搜索引擎中的排名,从而增加网站流量和曝光度的技术和方法。SEO的目标是使网站在搜索引擎结果页面中获得更高这个过程包括吸引更多访问者的关键词优化、内容优化、技术优化和用户体验优化等方面。SEO是网站推广和营销的重要手段,能够帮助企业提升品牌形象、吸引潜在客户,并增加销售机会。 SEO已成为数字营销中心的一部分,对于网站所有者和在线业务来说具有重要意义。
本文将百度为案例,介绍如何利用Python爬虫获取关键词数据、提取网页内容,并进行数据处理和网页内容优化的过程。
利用Python爬虫获取关键词数据
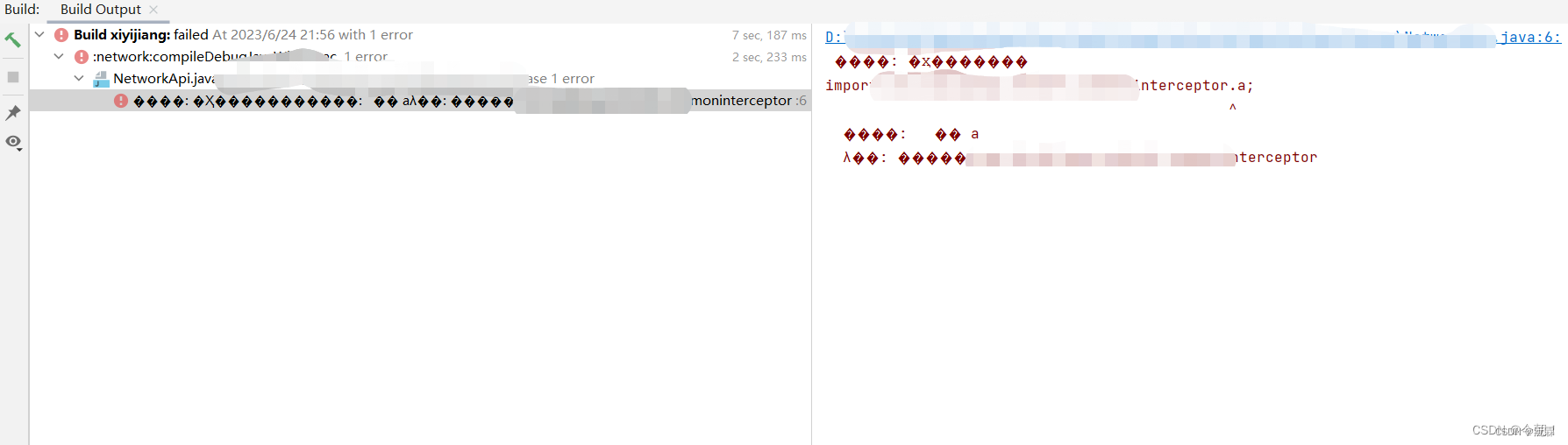
首先,我们可以利用Python爬虫获取搜索引擎中与我们网站相关的关键词数据,包括搜索量、竞争程度等信息。这些数据可以帮助我们在下面选择合适的关键词进行优化。这是一个简单的Python爬虫示例,用于获取百度搜索引擎与特定关键词相关的搜索结果:
import requests
from bs4 import BeautifulSoup
def baidu_search(keyword):
url = 'https://www.baidu.com/s'
params = {'wd': keyword}
response = requests.get(url, params=params)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
results = soup.find_all('h3', class_='t')
for result in results:
print(result.text)
else:
print('Failed to retrieve search results')
baidu_search('Python爬虫')
利用Python爬虫进行网页内容抓取
其次,我们可以利用Python爬虫技术截取缩小网站的内容,分析其关键词使用情况、页面结构等信息,获取优化的灵感。下面是一个简单的Python爬虫示例,用于截取缩小网站的内容:
import requests
from bs4 import BeautifulSoup
def fetch_similar_site_content(url):
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
content = soup.find('div', class_='content')
print(content.text)
else:
print('Failed to fetch site content')
fetch_similar_site_content('http://www.similarsite.com')
数据处理和分析
获得了关键词和网页内容数据之后,我们需要对这些数据进行处理和分析,找出关键词的优化空间,以及竞争对手网站的优势和劣势。这一步通常需要结合数据分析工具和Python的数据处理库进行深入分析,以便制定有效的优化策略。
优化网页内容
最后,根据分析数据的结果,我们可以对网站内容进行优化,包括关键词的合理使用、页面结构的优化等,从而提升网站在搜索引擎中的排名。这一步需要结合网站开发技术和Python爬虫技术,对网站内容进行了方便的优化。
总结
通过以上步骤,我们可以利用Python爬虫技术实现搜索引擎优化,从而提升网站在搜索引擎中的排名。当然,搜索引擎优化是一个复杂的过程,需要不断的数据分析和优化实践。希望表格修改您的在利用Python爬虫进行搜索引擎优化方面提供了一些帮助。























![oracle 安装时报[INS-13001]环境不满足最低要求](https://img-blog.csdnimg.cn/direct/5671b7981b1746bc8fdf564569408e5e.png)