Python 网络爬虫基础:Cookie、XPath 和 BeautifulSoup
网络爬虫是自动化从互联网上抓取数据的技术。在 Python 中,有几个强大的库可以帮助我们完成这项任务,其中 requests 用于处理 HTTP 请求和 Cookies,lxml 提供了 XPath 解析功能,而 BeautifulSoup 则是用于解析 HTML 和 XML 文档的利器。本文将为你介绍这三个工具的基本概念和使用方法。
Cookie 的使用
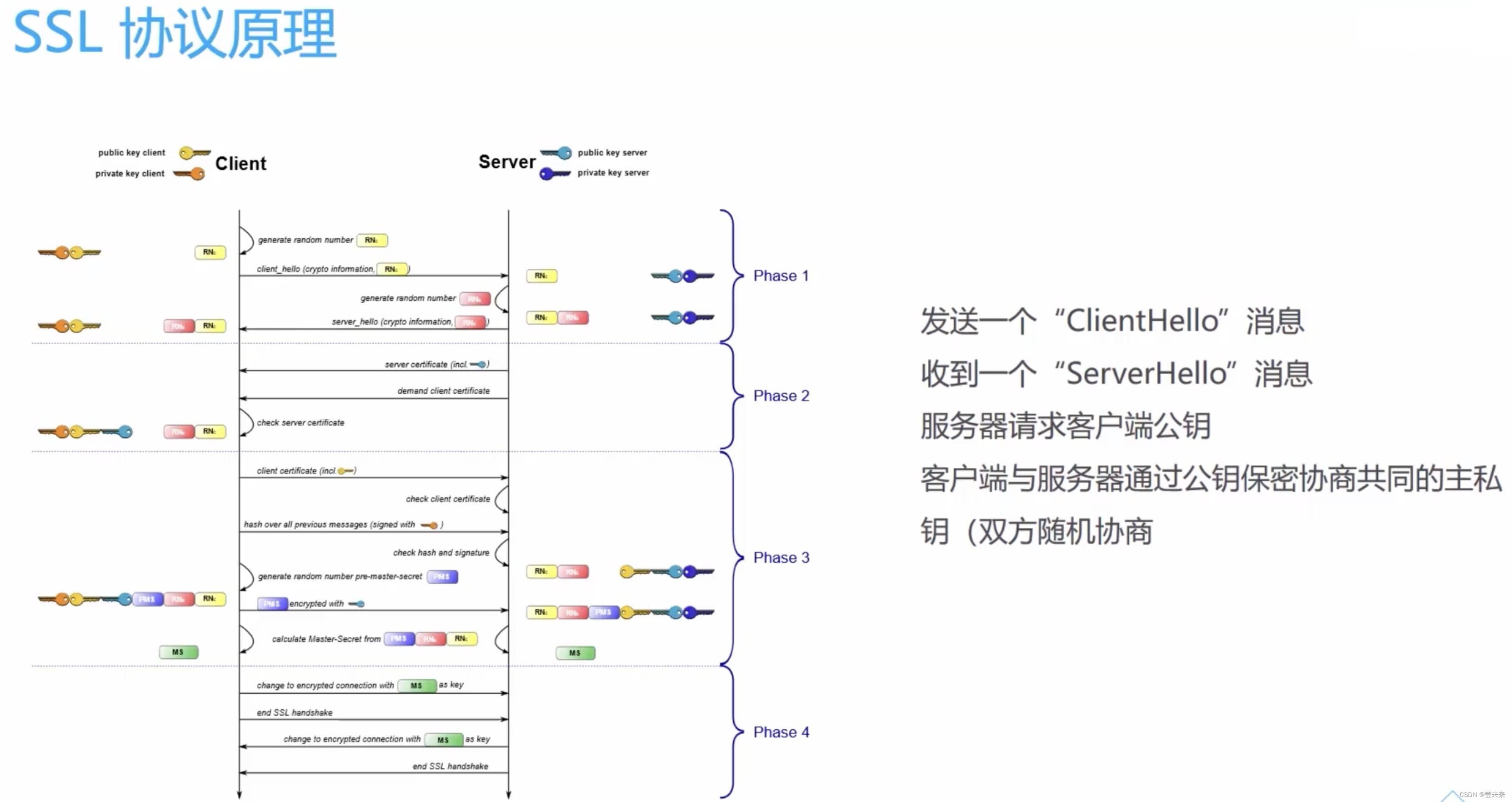
Cookie 是网站为了识别用户身份而存储在用户本地终端上的数据。在进行网络爬虫时,有时需要处理登录后的会话,这时候就需要用到 Cookie。
使用 requests 库处理 Cookie
首先,你需要安装 requests 库(如果尚未安装):
pip install requests
然后,你可以在发送 HTTP 请求时保存和使用 Cookie:
import requests
# 发送登录请求,保存 Cookie
login_url = 'http://example.com/login'
login_data = {'username': 'user', 'password': 'pass'}
response = requests.post(login_url, data=login_data)
cookies = response.cookies
# 使用 Cookie 发送其他请求
url = 'http://example.com/protected_page'
response = requests.get(url, cookies=cookies)
print(response.text)
XPath 选择器
XPath 是一种在 XML 和 HTML 文档中查找信息的语言。在 Python 中,我们通常使用 lxml 库来执行 XPath 查询。
安装 lxml
首先,安装 lxml 库:
pip install lxml
使用 XPath
from lxml import html
# 获取 HTML 文档
url = 'http://example.com'
response = requests.get(url)
html_tree = html.fromstring(response.content)
# 使用 XPath 查询
title = html_tree.xpath('//title/text()')
print(title[0]) # 输出页面标题
BeautifulSoup 解析器
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的库,它能够从网页中提取数据,并且易于使用。
安装 BeautifulSoup
首先,安装 beautifulsoup4 库:
pip install beautifulsoup4
使用 BeautifulSoup
from bs4 import BeautifulSoup
# 获取 HTML 文档
url = 'http://example.com'
response = requests.get(url)
# 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 使用 BeautifulSoup 提取数据
title = soup.title.string
print(title) # 输出页面标题
# 提取链接
links = soup.find_all('a')
for link in links:
print(link.get('href')) # 输出所有链接的 href 属性
结合使用
在实际的网络爬虫任务中,我们经常需要结合使用这些工具。例如,你可能需要先登录一个网站,保存登录后的 Cookie,然后用 XPath 或 BeautifulSoup 解析返回的 HTML 页面。
import requests
from bs4 import BeautifulSoup
from lxml import html
# 登录并保存 Cookie
login_url = 'http://example.com/login'
login_data = {'username': 'user', 'password': 'pass'}
session = requests.Session()
session.post(login_url, data=login_data)
# 使用保存的 Cookie 发送请求
url = 'http://example.com/protected_page'
response = session.get(url)
# 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 使用 XPath 或 BeautifulSoup 提取数据
# ...
通过本文的介绍,你应该对 Python 中处理 Cookie、使用 XPath 和 BeautifulSoup 解析器有了基本的了解。在实际应用中,你可能需要根据网站的具体情况调整代码,以应对各种反爬虫策略。记住,尊重网站的 robots.txt 文件和版权政策,合理合法地进行网络爬虫活动。