今天,我们将深入研究一篇在语言图像预训练方面借鉴了CLIP巨大成功的论文,并将其扩展到目标检测任务的论文:GLIP —— Grounded Language-Image Pre-training(基于语言图像的预训练)。我们将涵盖论文的关键概念和发现,并通过提供更多上下文以及对图像和实验结果添加注释,使其易于理解。让我们开始吧!

论文:基于语言
图像的预训练
代码:https://github.com/microsoft/GLIP
首次发布日期:2021年12月7日
作者:Liunian Harold Li,Pengchuan Zhang,Haotian Zhang,Jianwei Yang,Chunyuan Li,Yiwu Zhong,Lijuan Wang,Lu Yuan,Lei Zhang,Jenq-Neng Hwang,Kai-Wei Chang,Jianfeng Gao
类别:表示学习,目标检测,短语定位,多模态深度学习,计算机视觉,自然语言处理,基础模型
大纲
背景与背景
宣称的贡献
方法
实验
进一步阅读和资源
背景与背景
GLIP(Grounded Language-Image Pre-training)是一种多模态语言图像模型。类似于CLIP(对比语言图像预训练),它执行对比性预训练以学习语义丰富的表示,并在其模态之间对齐它们。虽然CLIP在图像级别学习这些表示,这意味着一个句子描述整个图像,但GLIP旨在将此方法扩展到对象级别的表示,意味着一个句子可能对应于图像中的多个对象。在文本提示中识别单个标记与图像中的对象或区域之间的对应关系的任务称为短语定位。因此,在GLIP中有“Grounded”一词。
因此,GLIP的目标是:
统一大规模预训练的短语定位和目标检测。
为零样本目标检测提供灵活的框架,其中灵活意味着不受限于固定的类别集。
构建一个预训练模型,以零样本或少样本的方式无缝转移到各种任务和领域。
有了这样的模型,您可以使用文本提示在给定的输入图像中找到感兴趣的对象或区域。而且最好的部分是:您不受预定义类别的限制。
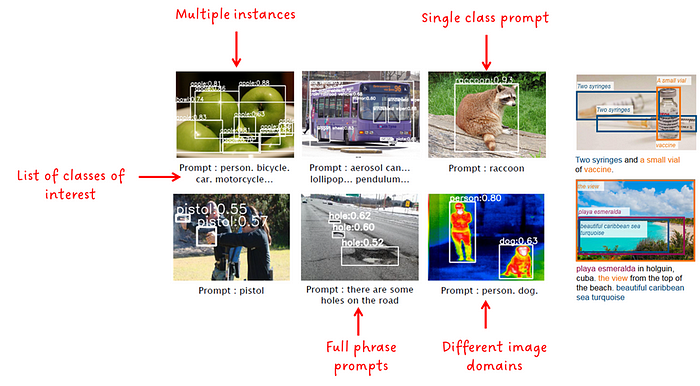
GLIP对不同图像和提示格式的输出
您可以进一步处理这些检测(例如将其输入到跟踪系统中),或创建一个包含感兴趣的特定类别的自定义数据集,并使用这些数据集来训练您自己的监督检测系统。您不仅可以覆盖罕见或非常特定的类别,而且还可以为手动标签的创建节省大量时间和金钱。正如我们将在后面看到的,GLIP的作者通过引入教师-学生框架,提出了类似的想法,以进一步提高性能。
GLIP已经被深度学习中的许多其他项目和领域采用。例如,GLIGEN(基于语言图像生成)使用GLIP作为潜在扩散模型的图像生成的条件,以增加可控性。此外,GLIP已与其他模型结合使用,例如DINO(具有改进的去噪锚定框的DETR)和SAM(Segment Anything Model),分别形成GroundingDINO和Grounded-Segment-Anything。GLIPv2将初始的GLIP模型扩展到视觉语言理解,以不仅改善短语定位,还启用视觉问答任务。
宣称的贡献:
大规模预训练,结合短语定位和目标检测
提供对目标检测和短语定位的统一视图
深度跨模态融合,学习高质量的语言感知视觉表示,并实现卓越的迁移学习性能。
表明在深度视觉语言融合(例如GLIP)中,与浅融合网络(例如CLIP)相比,对提示进行微调更为有效。
方法
对GLIP能够做什么有了一个大致的了解,让我们更详细地研究论文的细节。
架构概述
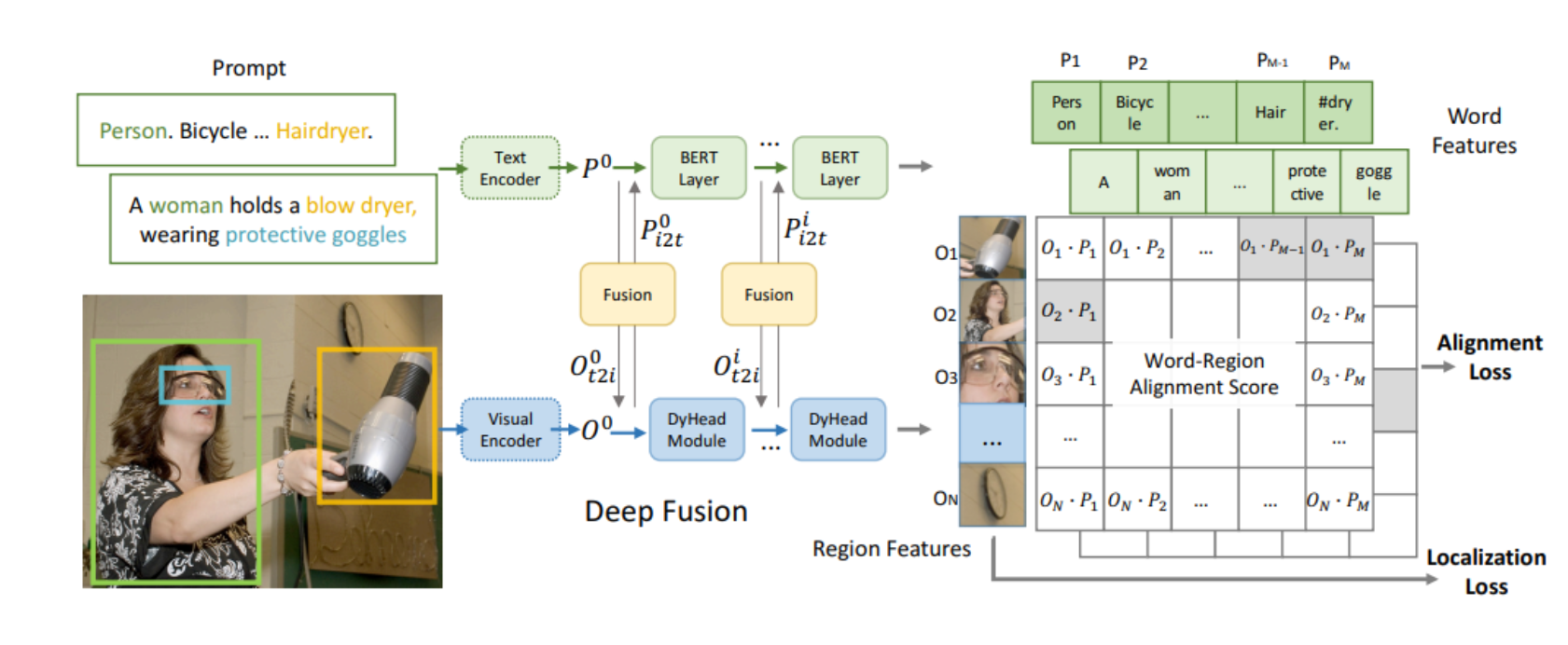
从高层次上看,GLIP的架构在某种程度上与CLIP的架构非常相似,它也包括一个文本编码器、一个图像编码器和某种在文本和图像特征的相似性上进行对比学习的模块。GLIP的架构如图2所示。
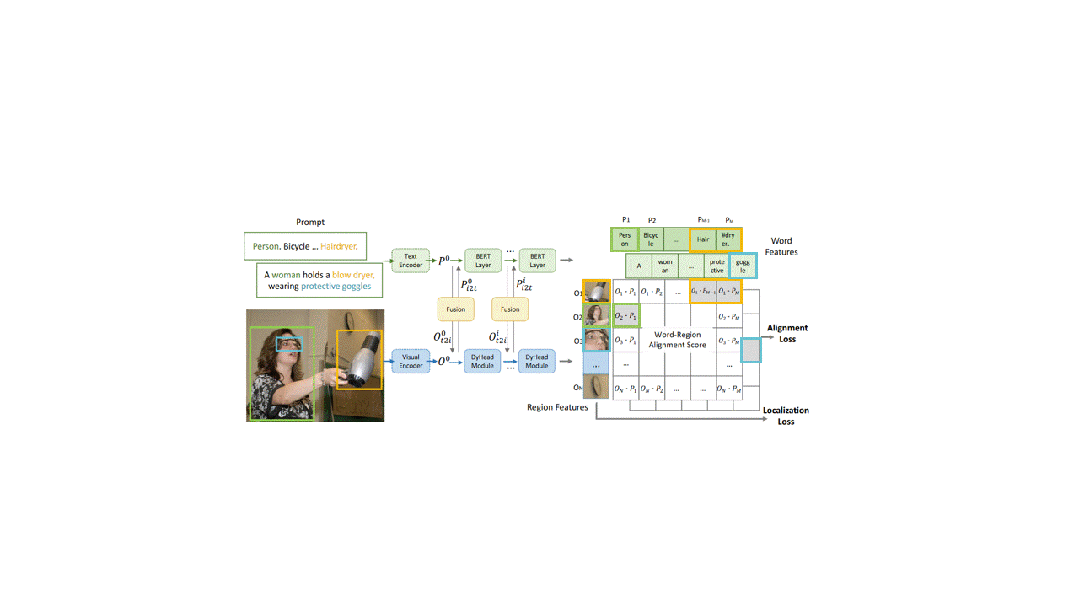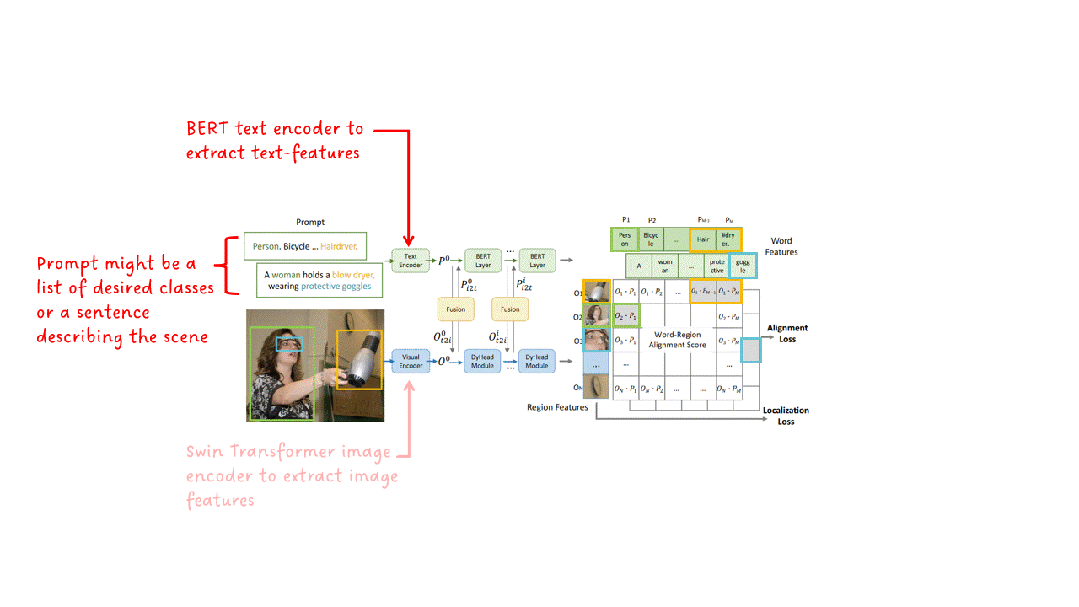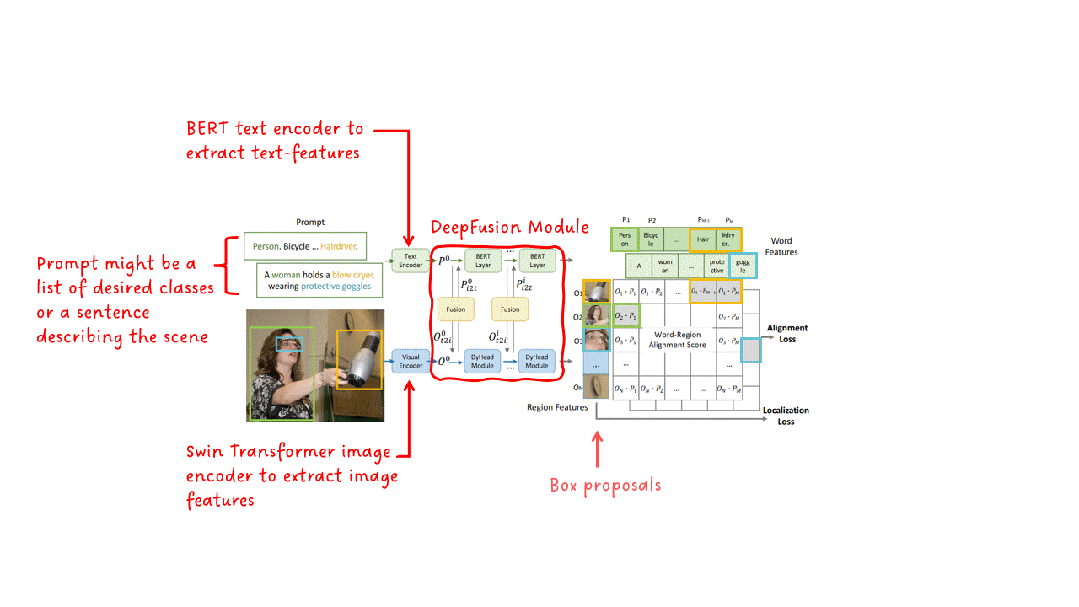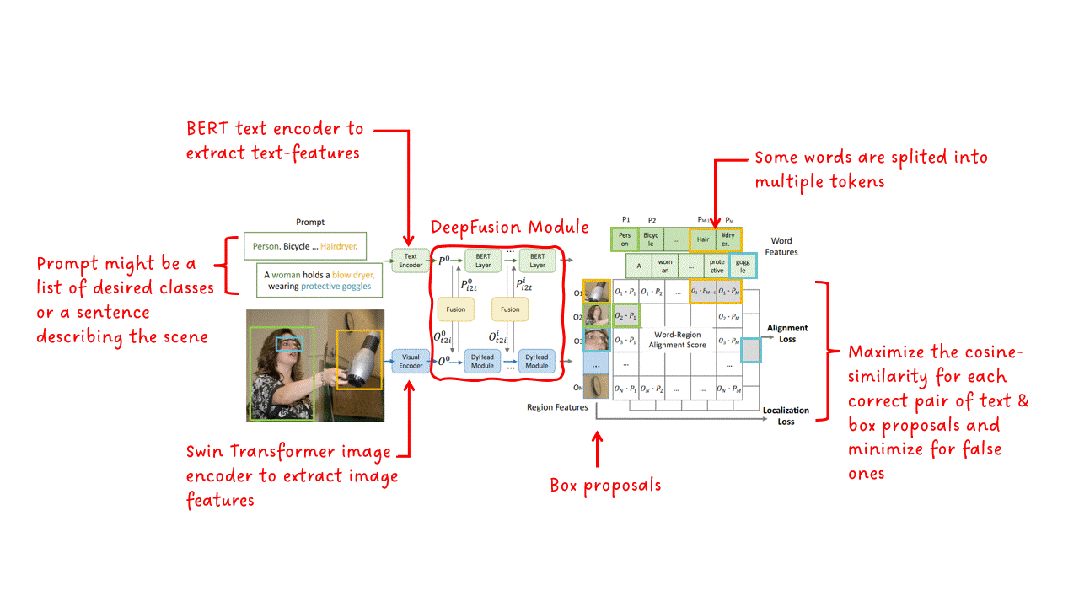
框架架构
在文本和图像编码器之后,GLIP添加了一个语言图像感知的深度融合模块。该模块执行跨模态注意力并提取进一步的特征。在结果区域特征和单词特征上计算余弦相似性。在训练期间,最大化匹配对的相似性,同时对不正确的对进行最小化。与CLIP不同,其中匹配对位于相似性矩阵的对角线上,GLIP中的匹配不是在句子级别上执行的,而是在(子)词级别上执行,通常位于对角线之外的位置。
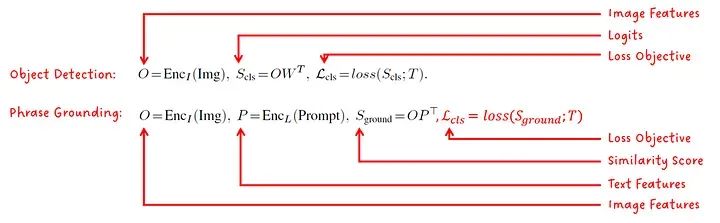
将短语定位定义为目标检测问题
作者指出,短语定位(将单词与图像中的对象/区域相关联)的问题可以被制定为目标检测目标,其中标准损失目标为:
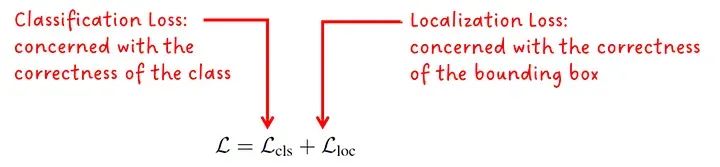
定位损失与预测边界框的质量有关,具体取决于格式,可能是框的大小和位置。分类损失是统一性的关键部分。通过在文本-图像特征的相似性分数上计算对数几率,而不是在图像分类器的对数几率上计算,可以使用相同的损失目标进行训练。
不同的模型变体
为了展示作者的设计选择和模型规模的效果,训练了五种不同的模型变体:
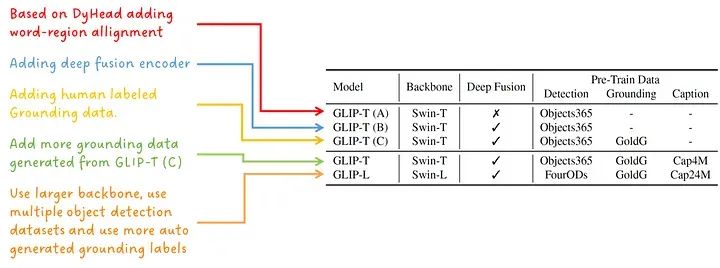
模型变体
教师-学生预训练
为了提高GLIP的性能,作者在人工注释的数据GoldG上训练了GLIP-T(C)模型(见图3),从而生成来自互联网上的文本-图像对的定位数据。他们将此模型称为教师模型,并随后训练一个学生模型,将训练教师的数据和教师生成的数据一并输入。
注意:尽管使用了教师和学生这些术语,但这与知识蒸馏中使用的过程并不相同,知识蒸馏中会训练一个较小的学生模型以匹配较大的教师模型的输出。
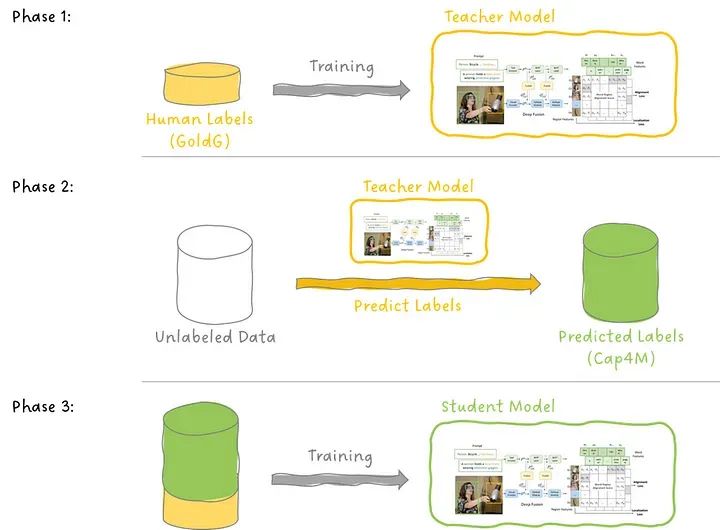
教师-学生预训练
有趣的是,正如我们将在实验中看到的那样,对于零样本和少样本检测,学生在许多(但不是全部)数据集上超过了教师。为什么呢?论文假设,即使教师以低置信度提供预测(他们称之为“学问猜测”),它在学生使用的生成数据集中变为真实标签(他们称之为“监督信号”)。
实验
GLIP论文提出了各种实验和消融研究,主要涉及:
零样本领域转移
数据效率
提示工程
零样本领域转移
首先,我们将查看零样本领域转移的结果。在此任务中,目标是分析预训练的GLIP模型在不同数据集上的表现(即COCO和LVIS),并将其与以监督方式训练的模型的基线进行比较。然后,对预训练的GLIP进行进一步微调,并在测试数据集上进行评估。
在图5中,我们看到了在COCO上进行零样本领域转移的结果。我们看到所有GLIP模型在零样本性能方面均优于监督的Faster RCNN。我们还看到GLIP-L的性能优于先前的SOTA(在论文发布时)。我们看到较大的学生模型GLIP-L优于教师模型GLIP-T(C)。
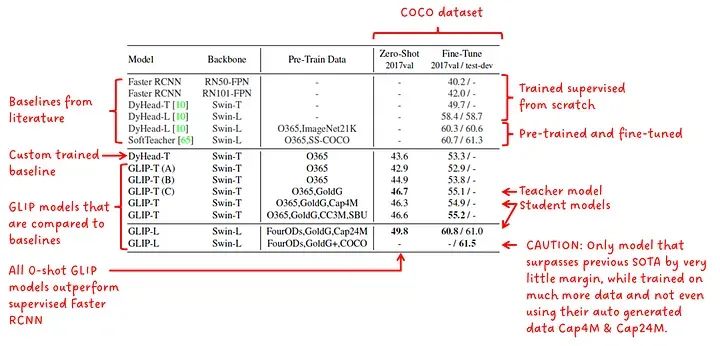
零样本领域转移和在COCO上微调
接下来,我列举在阅读这些结果和论文中所提出的声明时产生的疑虑,在论文中称GLIP-L超过了最佳监督模型SoftTeacher。
具有更好指标的模型是GLIP-L,其优势为0.2点。这种小幅度的差距可能不是GLIP新方法的结果,而可能是由于训练超参数的一些差异。
GLIP-L甚至没有使用从教师模型生成的数据(Cap4M或Cap24M),而他们将其提出为一种不错的解决方案。
GLIP-L在训练时使用了比SoftTeacher更大的训练数据语料库。
在比较不同方法和模型在不明确或不同约束下进行比较时,我认为对于比较不同GLIP模型和他们自己训练的DyHead-T的结果,这是完全可以接受的,只是我总体上有一些疑虑。
在图6中,我们看到了在LVIS数据集上进行的零样本领域转移性能。我们可以看到最大的GLIP模型GLIP-L优于所有其他呈现的监督模型。
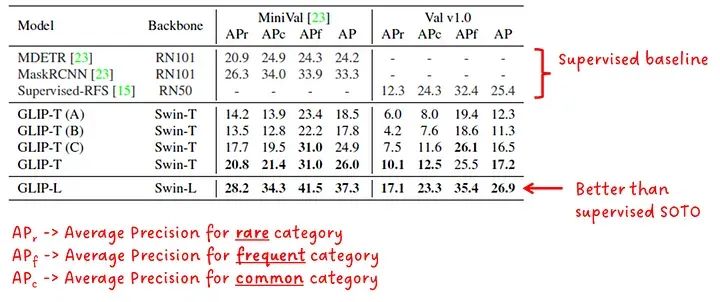
零样本领域转移至LVIS
最后,GLIP在Flickr30K实体上的短语定位性能与MDETR进行了比较(见图7)。GLIP-T和GLIP-L这两个学生模型均超过了MDETR的基线。
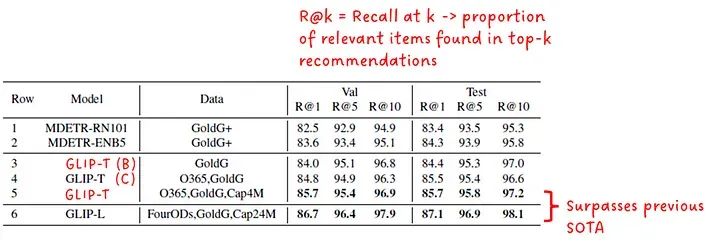
Flickr30K实体上的短语定位性能
数据效率
另一个实验涉及数据效率。该实验旨在展示在特定数量的任务特定数据上微调预训练模型时性能(以平均精度为指标)的变化。在图8中,对13个不同的数据集评估了这些模型,并将其性能报告为在13个数据集上平均的平均精度。结果报告了0样本,1样本,3样本,5样本,10样本和“all”样本(我怀疑这是完全微调的官方术语,但我想你懂的 😅)。
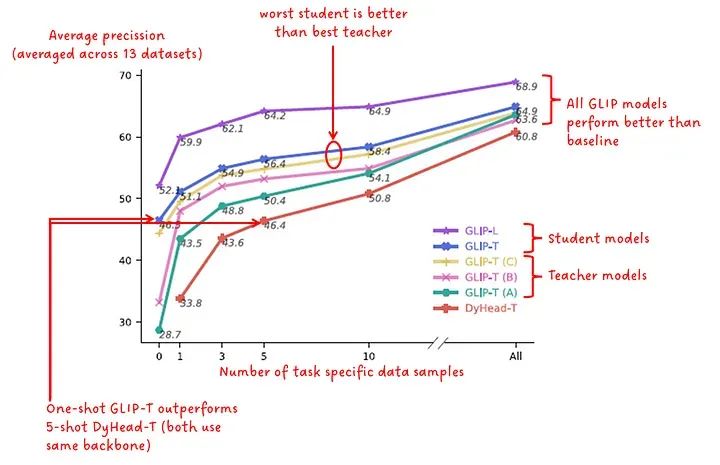
数据效率
提示工程
与CLIP类似,作者还报告了模型性能与输入文本提示的表述之间的相关性。他们提出了两种方法来提高预训练模型的性能,而无需重新训练模型的权重:
手动提示调整
提示调整
手动提示调整的思想是通过提供额外的描述性词语来提供进一步的上下文,见下图:

手动提示调整示例
手动提示调整始终可以用于提高性能,这意味着无论模型是否完全微调,还是在零样本或少样本场景中使用模型,都没有关系。
第二种方法,提示调整,需要访问下游任务的地面真实标签,特别适用于每个检测任务都有单一提示(例如“检测汽车”)的场景。在这种情况下,该提示首先将通过文本编码器将其转换为特征嵌入。然后,冻结图像编码器和深度融合模块,只优化输入嵌入,使用地面真实标签。优化后的嵌入然后作为输入提供给模型,文本编码器可以被移除。
下图显示了对各种GLIP模型进行的这种提示调整的结果。当应用于具有深度融合模块的模型时,提示调整几乎可以达到微调模型权重的性能。
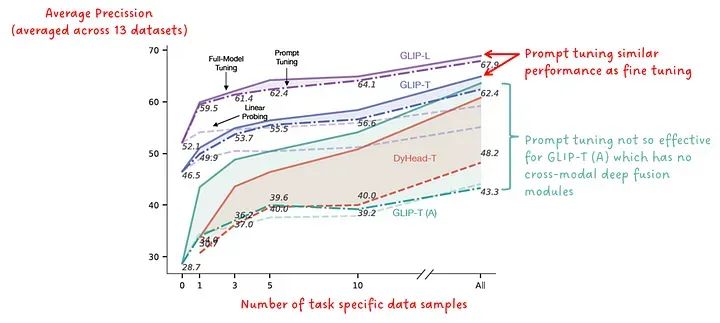
提示调整的有效性
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除