目录
49.什么是JWT?使用JWT的流程?对比传统的会话有啥区别?
46.什么是Session Replication?
Session Replication的方案则不对负载均衡器做更改,而是在Web服务器之间增加了会话数据同步的功能,各个服务器之间通过同步保证不同Web服务器之间的Session数据的一致性,如下图所示。
Session Replication方案对负载均衡器不再有要求,但是同样会带来以下问题:
同步Session数据会造成额外的网络带宽的开销,只要Session数据有变化,就需要将新产生的Session数据同步到其他服务器上,服务器数量越多,同步带来的网络带宽开销也就越大。
每台Web服务器都需要保存全部的Session数据,如果整个集群的Session数量太多的话,则对于每台机器用于保存Session数据的占用会很严重。
47.什么是Session数据集中存储?
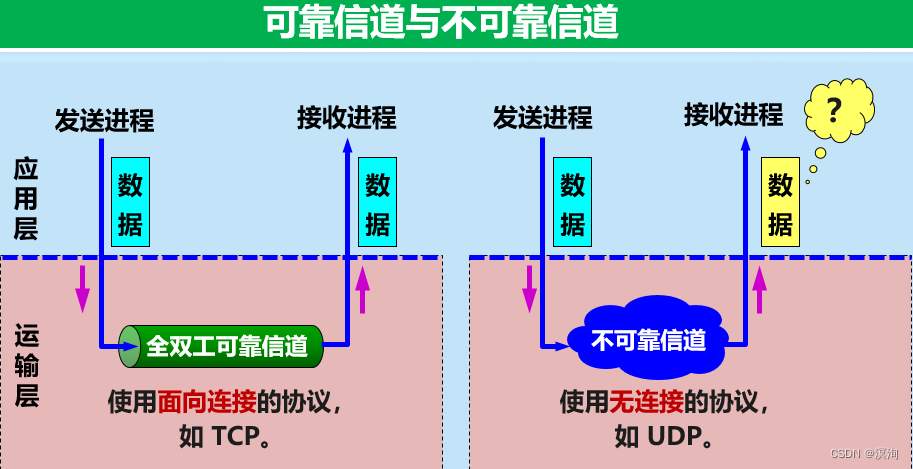
Session数据集中存储方案则是将集群中所有Session集中存储起来,Web服务器本身则并不存储Session数据,不同的Web服务器从同样的地方来获取Session,如下图所示。
相对于Session Replication方案,此方案的Session数据将不保存在本机,并且Web服务器之间也没有了Session数据的复制,但是该方案存在的问题在于:
读写Session数据引入网络操作,这相对于本机的数据读取来说,问题就在于存在时延和不稳定性,但是通信发生在内网,则问题不大。
如果集中存储Session的机器或集群出现问题,则会影响应用。
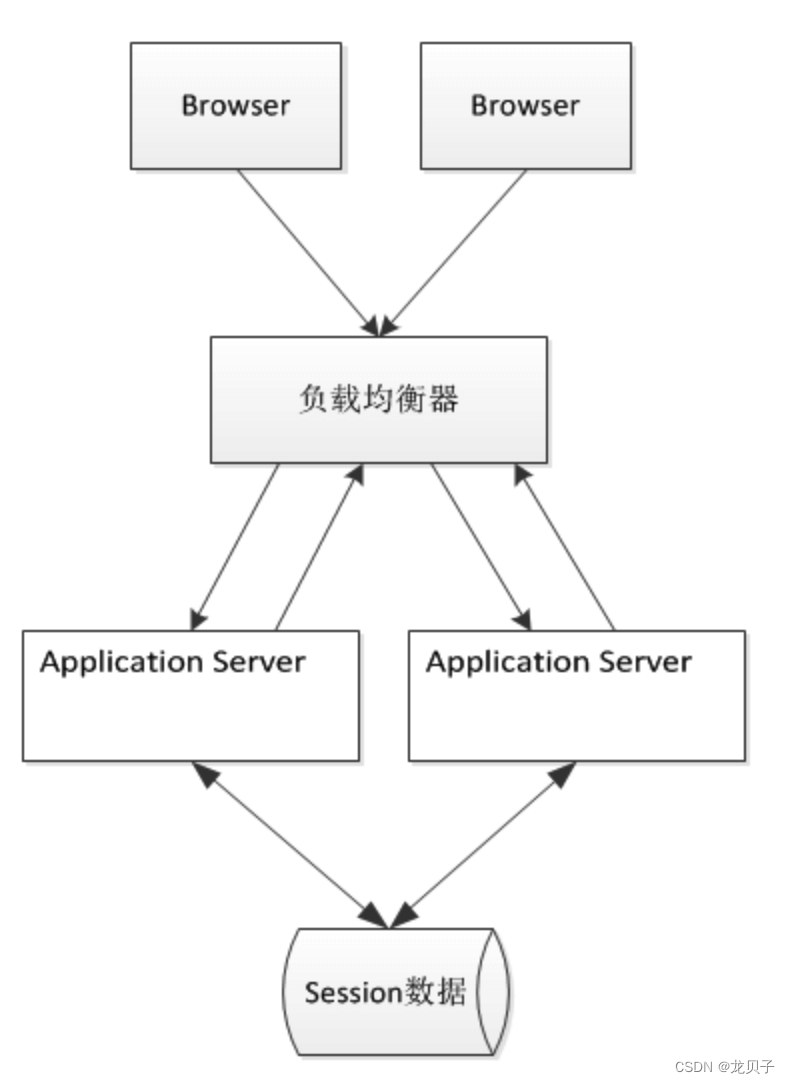
48.什么是Cookie Based Session?
Cookie Based方案是将Session数据放在Cookie里,访问Web服务器的时候,再由Web服务器生成对应的Session数据,如下图所示。

但是Cookie Based方案依然存在不足:
Cookie长度的限制。这会导致Session长度的限制。
安全性。Session数据本来是服务端数据,却被保存在了客户端,即使可以加密,但是依然存在不安全性。
带宽消耗。这里不是指内部Web服务器之间的带宽消耗,而是数据中心的整体外部带宽的消耗。
性能影响。每次HTTP请求和响应都带有Session数据,对Web服务器来说,在同样的处理情况下,响应的结果输出越少,支持的并发就会越高。
49.什么是JWT?使用JWT的流程?对比传统的会话有啥区别?
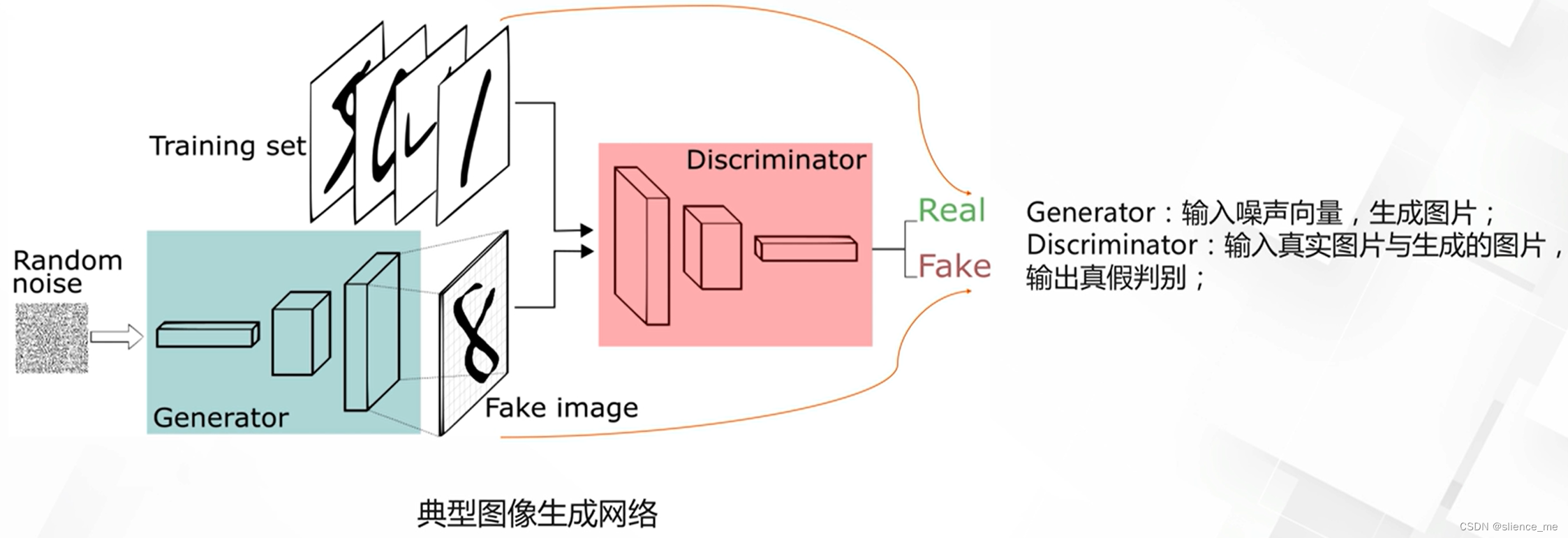
JSON Web Token,一般用它来替换掉Session实现数据共享。
使用基于Token的身份验证方法,在服务端不需要存储用户的登录记录。大概的流程是这样的:
1.客户端通过用户名和密码登录服务器;
2.服务端对客户端身份进行验证;
3.服务端对该用户生成Token,返回给客户端;
4.客户端将Token保存到本地浏览器,一般保存到cookie中
5.客户端发起请求,需要携带该Token;
6.服务端收到请求后买寿险验证Token,之后返回数据。

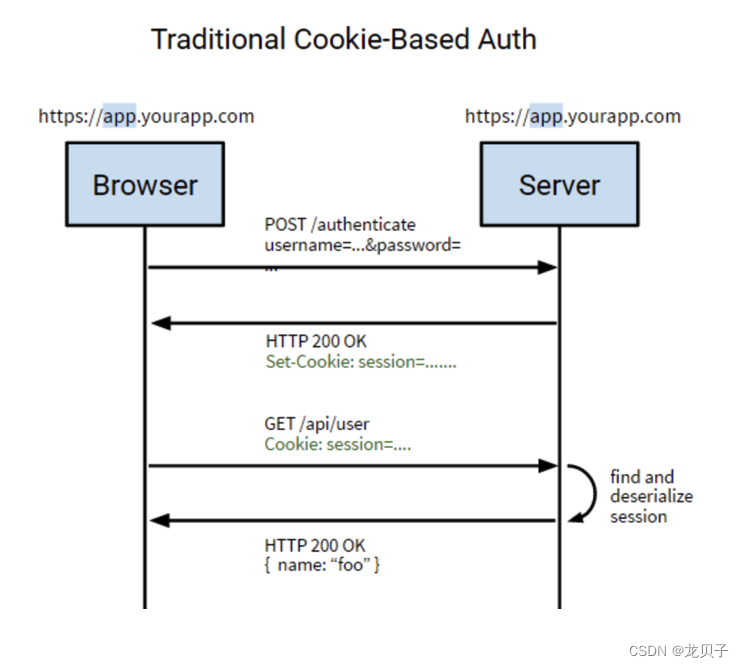
如上图为Token实现方式,浏览器第一次访问服务器,根据传过来的唯一标识userId,服务端会通过一些算法,如常用的HMAC SHA256算法,然后加一个密钥,生成一个token,然后通过BASE64编码以下之后将这个token发送给客户端;客户端将token保存起来,下次请求时,带着token,服务器收到请求后,然后会用相同的算法和密钥去验证token,如果通过,执行业务操作,不通过,返回不通过信息。
可以对比下图session实现方式,流程大致一致。
优点:
无状态,可扩展:在客户端存储的Token是无状态的,并且能够被扩展。基于这种无状态和不存储Session信息,负载均衡器能够将用户信息从一个服务传到其他服务器上。
安全:请求中发送Token而不再是发送Cookie能够防止CSRF(跨站请求伪造)。
可提供接口给第三方服务:使用Token时,可以提供可选的权限给第三方应用程序。
多平台跨域
对应用程序和服务进行扩展的时候,需要介入各种的设备和应用程序。假如我们的后端api服务器a.com只提供数据,而静态资源则存放在cdn服务器b.com上。当我们从a.com请求b.com下面的资源时,由于触发浏览器的同源策略限制而被阻止。
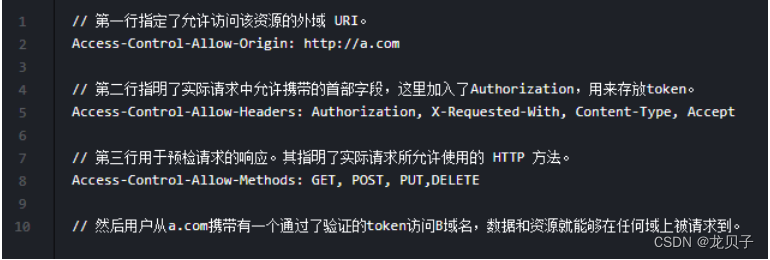
我们通过CORS(跨域资源共享)标准和token来解决资源共享和安全问题。
举个例子,我们可以设置b.com的响应首部字段为:
50.如何设计一个秒杀系统?
秒杀特点以及思路?
短时间内,大量用户涌入,集中读和写有限的库存。
1.尽量将请求拦截在系统上有(越上游越好);
2.读多写少的多使用缓存(缓存抗读压力);
从分层角度理解?
层层拦截,将请求尽量拦截在系统上游,避免将锁冲落到数据库上。
第一层:客户端优化
产品层面,用户点击“查询”后者“购票”后,按钮置灰,机制用户重复提交请求。
JS层面,限制用户在x秒之内只能提交一次请求,比如微信摇一摇抢红包。
基本可以拦截80%的请求。
第二层:站点层面的请求拦截(Nginx层,写流控模块)
怎么防止程序员写for循环调用,有去重依据么?IP?
Cookie ID?.....想复杂了,这类业务都需要登录,用uid即可。在站点层面,对uid进行请求计数和去重,甚至不需要统一存储计数,直接站点层内存储(这样计数会不准,但最简单,比如guava本地缓存)。一个uid,5秒只准通过1个请求,这样又能拦住99%的for循环请求。
对于5秒内的无效请求,统一返回错误提示或者错误页面。
这个方法拦住了写for循环发HTTP请求的程序员,有些高端程序员(黑客)控制了10万个肉鸡,手里面有10万个uid,同时发请求(先不考虑实名制的问题,小米抢手机不需要实名制),这下怎么办,站点层按照Uid限流拦不住了。
第三层:服务层拦截
方案一:
写请求放到队列中,每次只透有限的写请求到数据层,如果成功了再放下一批,直到库存不够,队列里写请求全部返回“已售完”。
方案二:或采用漏斗机制,只放一倍的流量进来,多余的返回”已售完“,把写压力转换成读压力。
读请求,用cache,redis单机可以抗10万 QPS,用异步线程定时更新缓存里的库存值。
还有提示”模糊化“,比如火车余票查询,票剩了58张,还是26张,你真的关注么,其实我们只关心有票和无票。
第四层:数据库层
浏览器拦截了80%,站点层拦截了99.9%并做了页面缓存,服务层又做了写请求队列与数据缓存,每次透到数据库层的请求都是可控的。db基本就没有什么压力了,通过自身机制来控制,避免出现超卖。
从架构角度理解?
高性能
动静分离 秒杀过程中你是不需要刷新整个页面的,只有时间在不停跳动。这是因为一般都会对大流量的秒杀系统做系统的静态化改造,即数据意义上的动静分离。动静分离三步走:
1.数据拆分
2.静态缓存
3.数据整合
热点优化:
数据的热点优化与动静分离是不一样的,热点优化是基于二八原则对数据进行了纵向拆分,以便进行针对性的处理。热点识别和隔离不仅对”秒杀“这个场景有意义,对其他的高性能分布式系统也非常有参考价值。
系统优化
减少序列化:
减少Java中的序列化操作可以很好的提升系统性能。序列化大部分是在RPC阶段发生,因此应该尽量减少RPC调用,一种可行方案是将多个关联性较强的应用进行“合并部署”,从而减少不同应用之间的RPC调用(微服务设计规范)
直接输出流数据:只要涉及字符串的I/O操作,无论是磁盘I/O还是网络I/O,都比较耗费CPU资源,因为字符需要转换成字节,而这个转换又必须查表编码。所以对于常用数据,比如静态字符串,推荐提前编码成字节并缓存,具体到代码层面就是通过OutputStream()类函数从而减少数据的编码转换;另外,热点方法toString()不要直接调用ReflectionToString实现,推荐直接硬编码,并且只打印DO的基础要素和核心要素。
裁剪日志异常堆栈:无论是外部系统异常还是应用本身异常,都会有堆栈打出,超大流量下,频繁的输出完整堆栈,只会家具系统当前负载。可以通过日志配置文件控制异常堆栈输出的深度。
去组件矿建:极致优化要求下,可以去调一些组件框架,比如去掉传统的MVC框架,直接使用Servlet处理请求。这样可以绕过一大堆复杂且用处不大的处理逻辑,节省毫秒级的时间,当然,需要合理评估你对框架的依赖程度
高可用
流量削峰
1.答题:答题目前已经使用的非常普遍了,本质是通过在入口层削减流量,从而让系统更好的支撑瞬时峰值。
2MQ:最为常见的削峰方式是使用消息队列,通过把同步的直接调用转换成异步的间接推送缓冲时流量。
3.过滤
Plan B:为了保证系统的高可用,必须设计一个Plan B方案来进行兜底。
51.接口设计要考虑哪些哪些方面?
接口版本化
命名规范
请求参数的规范性以及处理的统一性
返回数据类型,返回码以及信息提示的规范性
接口安全验证以及权限的控制
请求接口日志的记录
良好的接口说明文档和测试程序
52.什么是接口幂等?如何保证接口的幂等性?
接口的幂等性实际上就是接口可重复调用,在调用方多次调用的情况下,接口最终得到的结果是一致的。有些接口可以天然的实现幂等性,比如查询接口,对于查询来说,你查询一次和两次,对于系统来说,没有任何影响,查出的结果也是一样。
除了查询功能具有天然的幂等性之外,增加,更新,删除都要保证幂等性。那么如何来保证幂等性呢?
全局唯一ID
如果使用全局唯一ID,就是根据业务的操作和内容生成一个全局ID,在执行操作之前现根据这个全局唯一ID是否存在,来判断这个操作是否已经执行。如果不存在则把全局ID,存储到存储系统中,比如数据库,Redis等。如果存在则表示 该方法已经执行。
从工程的角度来说,使用全局ID做幂等可以作为一个业务的基础的微服务存在,在很多的微服务中都会用到这样的服务,在每个微服务中都完成这样的功能,会存在工作量重复。另外打造一个高可靠的幂等服务还需要考虑很多问题,比如一台机器虽然把全局ID先写入了存储,但是在写入之后挂了,这就需要引入全局ID的超时机制。
使用全局唯一ID是一个通用方案,可以支持插入,更新,删除业务操作。但是这个方案看起来很美但是实现起来比较麻烦,下面的方案适用于特定的场景,但是实现起来比较简单。
去重表
这种方法适用于在业务中有唯一标识的插入场景,比如在以上的支付场景中,如果一个订单只会支付一次,所以订单ID可以作为唯一标识。这时,我们就可以建一张去重表,并且把唯一标识作为唯一索引,放在一个事务中,如果重复创建,数据库会抛出唯一约束异常,操作就会回滚。
插入或更新
这种方法插入并且有唯一索引的情况,比如我们要关联商品品类,其中商品的ID和品类的ID可以构成唯一索引,并且在数据表中也增加了唯一索引。这时就可以使用InsertOrUpdate操作。在mysql数据库中如下:

多版本控制
这种方法适合在更新的场景中,比如我们要更新商品的名字,这时我们就可以在更新的接口中增加一个版本号,来做幂等。

在实现时可以如下:

状态机控制
这种方法适合在有状态机流转的情况下,比如就会订单的创建和付款,订单的付款肯定是在之前,这时我们可以通过在设计状态字段时,使用int类型,并且通过值类型的大小来做幂等等,比如订单的创建为0,付款成功为100。付款失败99.
在做状态机更新时,我们就可以这样控制