之前使用ChatGLM3的自定义工具实现了查询MySQL数据库,但感觉功能还是比较受限。
https://blog.csdn.net/weixin_44455388/article/details/135270879?spm=1001.2014.3001.5501
使用ChatGLM3实现Text2SQL
前言
将自然语言文本(Text)转换成结构化查询语言 SQL,帮助用户快速生成想要查询的 SQL 语句;或者是用户输入一段话,然后系统完成一系列自动化查询和报表展示的操作,过自然语言描述完成复杂数据库的查询工作,得到想要的结果。
Text2SQL的构建
我们在 Text2SQL 上面的应用主要包括两个阶段,第一阶段是利用 LLM 理解你的请求,通过请求去生成结构化的 SQL;下一个阶段是在生成的 SQL 上自动化的查询数据库,返回结果,然后利用 LLM 对结果生成总结,提供分析。
第一阶段:SQL脚本构建
利用 LLM大模型理解文本信息,生成 SQL。因为考虑到数据的安全性,我们考虑使用ChatGLM生成SQL语句,从测试结果看,ChatGLM和GPT 对比,还是有比较大的差距,所以无法直接使用。
(1)构建数据信息表的 schema,利用 LLM 生成 embedding
这里我们根据用户描述的 text,让预训练的 chatglm2-6b 生成 embedding,通过 embedding 检索的方式,选出 top1 数据表,这个过程属于先验过滤阶段。
数据表的 schema 设计非常重要,需要描述清楚这个表它的主体信息以及表中重要字段和字段含义。
以下是我们设计的schema:
–tableName表示表名
–info表示该表的描述信息
–fields表示表字段信息,包括英文字段名、中文字段名和字段类型
[
{
"tableName":"prompt_history",
"info":"问答历史会话记录表,包括会话编号id、会用编号id、会话历史记录、会话时间。",
"fields":{
"session_id":"会话编号,String",
"user_id":"用户编号,String",
"history":"会话历史,String",
"create_time":"会话时间,datetime"
}
},
{
"tableName":"common_prompt",
"info":"常用prompt提示词表,包括提示词id、提示词标题、提示词内容。",
"fields":{
"id":"提示词id,int",
"title":"提示词标题,String",
"content":"提示词内容,String"
}
}
]
开发代码,将以上表信息进行向量化,存储到向量数据库:
public void addTable2Milvus(MultipartFile file) {
List<String> sqls = new ArrayList<>();
StringBuilder sb=new StringBuilder();
try (InputStream inputStream = file.getInputStream()) {
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
sb.append(new String(buffer));
}
JSONArray jsonArray = JSONArray.parseArray(sb.toString());
for (int i = 0;i<jsonArray.size();i++){
String string = jsonArray.getString(i);
sqls.add(string);
}
List<Integer> contentWordCount = new ArrayList<>();
List<List<Float>> contentVector = new ArrayList<>();
for(String str : sqls){
contentWordCount.add(str.length());
}
contentVector = embeddingModel.doEmbedding(sqls);
List<InsertParam.Field> fields = new ArrayList<>();
fields.add(new InsertParam.Field("content", sqls));
fields.add(new InsertParam.Field("content_word_count", contentWordCount));
fields.add(new InsertParam.Field("content_vector", contentVector));
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName("sqls")
.withFields(fields)
.build();
//插入数据
milvusClient.insert(insertParam);
log.info(file.getOriginalFilename()+" -> 向量化结束...");
} catch (IOException e) {
e.printStackTrace();
}
}
(2)prompt 提示词构建
我们需要将解析数据表中的信息,加入到 prompt 中,以此来构建完成的 prompt,让 LLM 去理解你的真实意图,生成标准的 SQL。
①开头prompt定义:
你是一个文本转SQL的生成器,你的主要目标是尽可能的协助用户,将输入的文本转化为正确的SQL语句。
上下文开始
表名和表字段来自以下表:
②查询向量数据库
public String buildQuerySql(String prompt) {
String finalPrompt = null;
//调用自定义的python服务
List<Float> vector = embeddingModel.doEmbedding(prompt);
List<PDFData> searchResult = search(Arrays.asList(vector));
StringBuilder builder = new StringBuilder();
for(PDFData data:searchResult){
builder.append(data.getContent()).append("\n");
}
//处理需要请求的信息
String msg = prefix_prompt+"%s。%s";
finalPrompt = String.format(msg,builder, prompt);
return finalPrompt;
}
/**
* 查询向量数据库
* @param search_vectors
* @return
*/
private List<PDFData> search(List<List<Float>> search_vectors){
milvusClient.loadCollection(
LoadCollectionParam.newBuilder()
.withCollectionName("sqls")
.build()
);
final Integer SEARCH_K = 4;
final String SEARCH_PARAM = "{
\"nprobe\":10}";
List<String> ids = Arrays.asList("id");
List<String> contents = Arrays.asList("content");
List<String> contentWordCounts = Arrays.asList("content_word_count");
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName("sqls")
.withConsistencyLevel(ConsistencyLevelEnum.STRONG)
.withOutFields(ids)
.withOutFields(contents)
.withOutFields(contentWordCounts)
.withTopK(SEARCH_K)
.withVectors(search_vectors)
.withVectorFieldName("content_vector")
.withParams(SEARCH_PARAM)
.build();
R<SearchResults> respSearch = milvusClient.search(searchParam);
List<PDFData> pdfDataList = new ArrayList<>();
if(respSearch.getStatus() == R.Status.Success.getCode()){
//respSearch.getData().getStatus() == R.Status.Success
SearchResults resp = respSearch.getData();
//判断是否查到结果
if(!resp.hasResults()){
return new ArrayList<>();
}
for (int i = 0; i < search_vectors.size(); ++i) {
SearchResultsWrapper wrapperSearch = new SearchResultsWrapper(resp.getResults());
List<Long> id = (List<Long>) wrapperSearch.getFieldData("id", 0);
List<String> content = (List<String>) wrapperSearch.getFieldData("content", 0);
List<Integer> contentWordCount = (List<Integer>) wrapperSearch.getFieldData("content_word_count", 0);
PDFData pdfData = new PDFData(id.get(0),content.get(0),contentWordCount.get(0));
pdfDataList.add(pdfData);
}
}
milvusClient.releaseCollection(
ReleaseCollectionParam.newBuilder()
.withCollectionName("sqls")
.build());
return pdfDataList;
}
③得到完成的prompt
你是一个文本转SQL的生成器,你的主要目标是尽可能的协助用户,将输入的文本转化为正确的SQL语句。
上下文开始
表名和表字段来自以下表:{
"fields":{
"create_time":"会话时间,datetime","user_id":"用户编号,String","session_id":"会话编号,String","history":"会话历史,String"},"tableName":"prompt_history","info":"问答历史会话记录表,包括会话编号id、会用编号id、会话历史记录、会话时间。"}
。查询一下23年12月20日以来的问答历史记录
(3)利用LLM大模型生成SQL语句
JSONObject params = new JSONObject();
params.put("model", "chatglm3-6b");
params.put("max_tokens", maxTokens);
params.put("stream", true);
params.put("temperature", temperature);
params.put("top_p", topP);
params.put("user", user);
JSONObject message = new JSONObject();
message.put("role", "user");
message.put("content", finalPrompt);
params.put("messages", Collections.singleton(message));
log.info("ChatGLM请求参数:"+message.toJSONString());
return webClient.post()
.uri(chatGlmUrl)
.header(HttpHeaders.AUTHORIZATION, "Bearer none")
.bodyValue(params.toJSONString())
.retrieve()
.bodyToFlux(String.class)
.onErrorResume(WebClientResponseException.class, ex -> {
HttpStatus status = ex.getStatusCode();
String res = ex.getResponseBodyAsString();
log.error("ChatGLM error: {} {}", status, res);
return Mono.error(new RuntimeException(res));
});
得到最终的SQL语句:
SELECT * FROM prompt_history WHERE create_time > '2023-12-20'
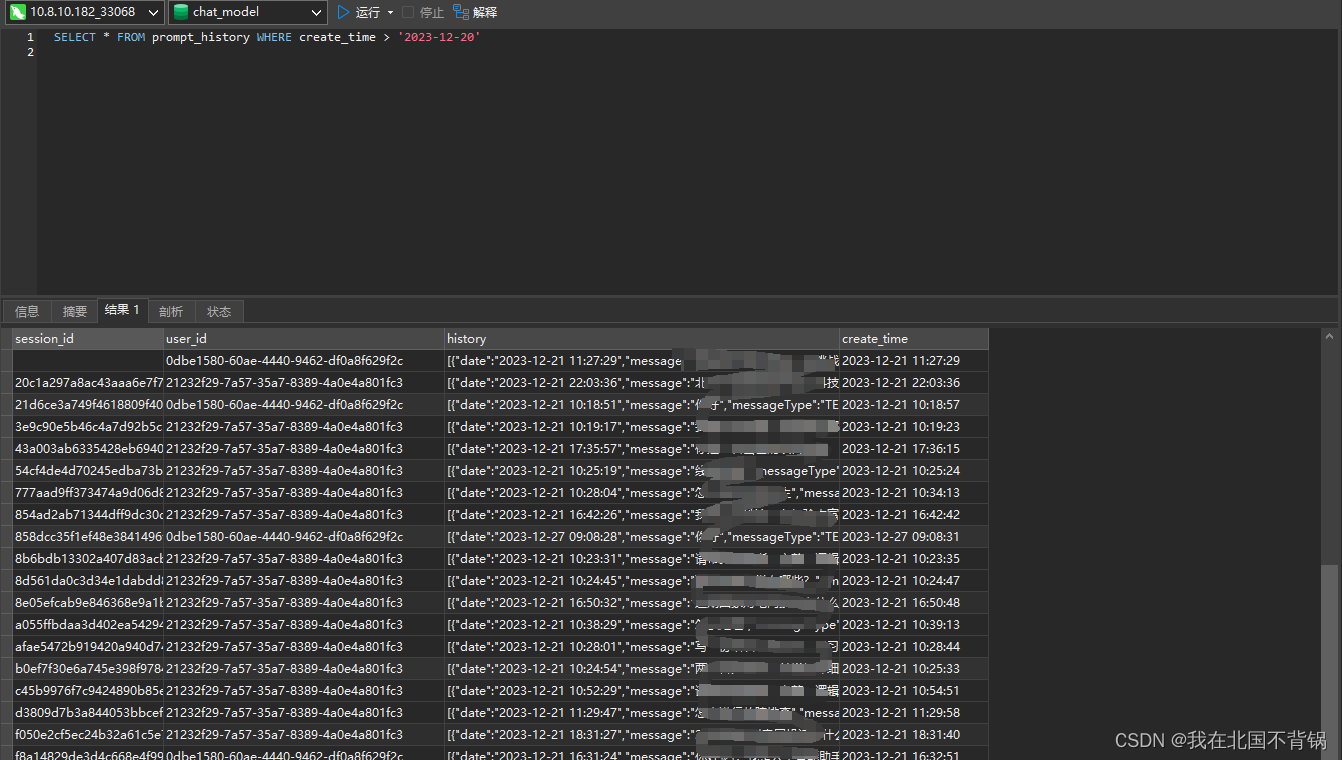
第二阶段:查询数据库,提供数据分析
可以在代码中连接数据库,运行SQL语句并返回结果。
优化
如果觉得ChatGLM的Text2SQL能力还是比较弱,可以采用微调的方式,强化ChatGLM的Text2SQL能力。
推荐项目:DB-GPT-Hub
参考
https://baijiahao.baidu.com/s?id=1780693355413218644&wfr=spider&for=pc





![NL<span style='color:red;'>2</span><span style='color:red;'>SQL</span>进阶系列(<span style='color:red;'>3</span>):Data-Copilot、Chat<span style='color:red;'>2</span>DB、Vanna <span style='color:red;'>Text</span><span style='color:red;'>2</span><span style='color:red;'>SQL</span>优化框架开源应用<span style='color:red;'>实践</span>详解[<span style='color:red;'>Text</span><span style='color:red;'>2</span><span style='color:red;'>SQL</span>]](https://img-blog.csdnimg.cn/img_convert/fe9ea57cc08b74aa976f64d4c6b0a68f.jpeg)