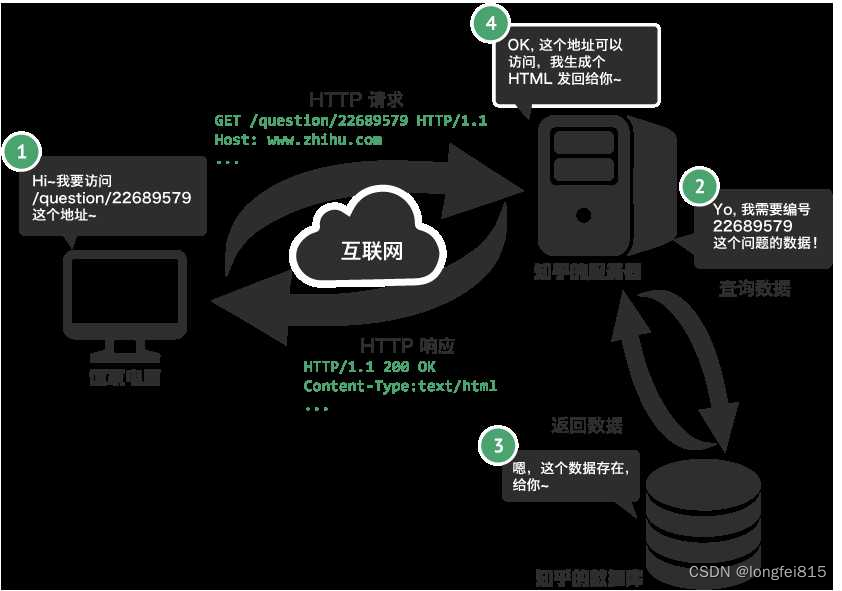
爬虫蜘蛛通常用于从网站上抓取数据。Python中有很多库可以用来编写爬虫,其中最常用的是requests和BeautifulSoup。下面是一个简单的爬虫蜘蛛示例,用于抓取网页上的标题和链接:
python复制代码
import requests |
|
from bs4 import BeautifulSoup |
|
def get_page(url): |
|
try: |
|
response = requests.get(url) |
|
response.raise_for_status() |
|
return response.text |
|
except requests.RequestException as e: |
|
print(e) |
|
def parse_page(html): |
|
soup = BeautifulSoup(html, 'html.parser') |
|
# 获取所有标题和链接 |
|
titles = soup.find_all('h1') |
|
links = soup.find_all('a') |
|
# 打印标题和链接 |
|
for title in titles: |
|
print(title.get_text()) |
|
for link in links: |
|
print(link.get('href')) |
|
if __name__ == '__main__': |
|
url = 'http://example.com' # 要抓取的网页地址 |
|
html = get_page(url) |
|
if html: |
|
parse_page(html) |
在这个示例中,我们首先使用requests库向指定的URL发送GET请求,并获取返回的HTML内容。然后,我们使用BeautifulSoup库解析HTML,并使用选择器找到所有的标题和链接。最后,我们将标题和链接打印到控制台上。

























![[蓝桥杯2020国赛]答疑](https://img-blog.csdnimg.cn/direct/0ba53a20a5ef4cebb65802205af25599.png)