标准化和归一化简介
1、数据预处理概述
在选择了合适模型的前提下,机器学习可谓是“训练台上3分钟,数据数量和质量台下10年功”。数据的收集与准备是机器学习中的重要一步,是构建一个好的预测模型大厦的基石。数据的数量与质量直接决定了预测模型的好坏
所以,在数据的收集与准备这一步中,必须做好数据预处理。Scikit-Learn提供了标准化和归一化等API方便我们进行数据预处理。标准化和归一化是常用的数据缩放方式
数据预处理的一般顺序(不一定全需要做)为:处理离群值、处理缺失值、标准化或归一化、纠偏、连续特征离散化、类别特征编码、特征增强和对不平衡数据集的处理(仅针对分类问题)
那么,为什么要进行标准化和归一化呢?
例如,我们的某个样本与其它样本数值相差较大,那么,该样本特征的方差就会比其他样本特征大几个数量级,那么,它就会在学习算法中占据主导位置,导致学习器并不能像我们说期望的那样,从其他特征中学习。也就是说,该样本会主导其它样本,最终导致预测结果的偏差
当某个或某些特征的单位或大小与其它样本相差较大,或者某特征的方差比其他的特征要大出几个数量级,那么,该特征就容易影响(支配)目标结果,使得一些算法无法学习到其他的特征,即无量纲化
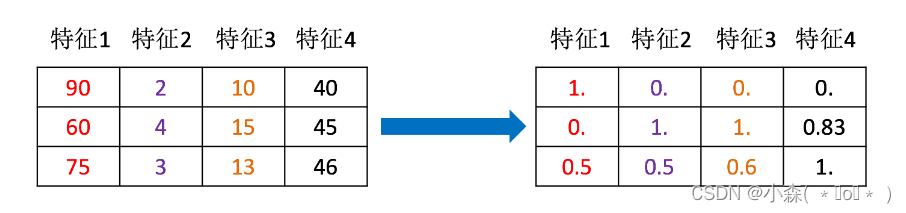
因此,我们需要做的是对样本数据进行数据标准化或归一化,将所有的数据映射到同一尺度
2、数据标准化
2.1、什么是数据标准化
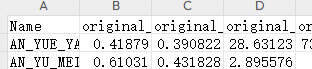
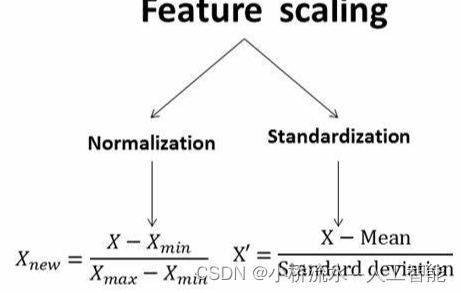
定义:数据标准化通过减去均值然后除以方差(或标准差),转化为均值为0,标准差为1的标准正态分布,转化公式为:
X ′ = X − μ σ X^{'}=\frac{X-\mu}{\sigma} X′=σX−μ
其中, μ \mu μ为均值, σ \sigma σ为标准差。标准化操作是将数据按其属性(按列)减去平均值,然后再除以标准差
当数据X按均值 μ \mu μ中心化后,再按标准差 σ \sigma