1. 为什么做归一化和标准化¶
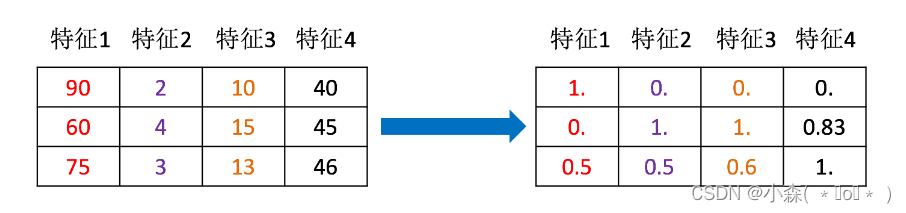
样本中有多个特征,每一个特征都有自己的定义域和取值范围,他们对距离计算也是不同的,如取值较大的影响力会盖过取值较小的参数。因此,为了公平,样本参数必须做一些归一化处理,将不同的特征都缩放到相同的区间或者分布内。
2. 归一化¶
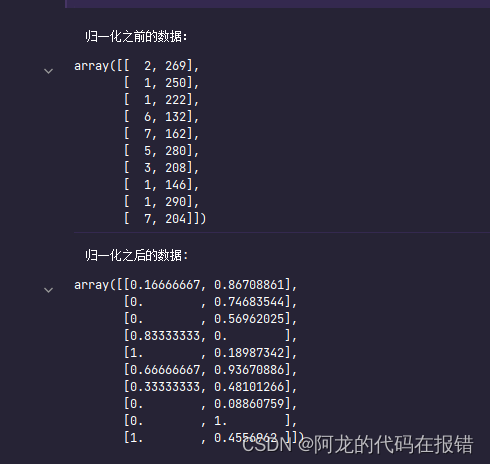
通过对原始数据进行变换,把数据映射到(默认为[0,1])之间。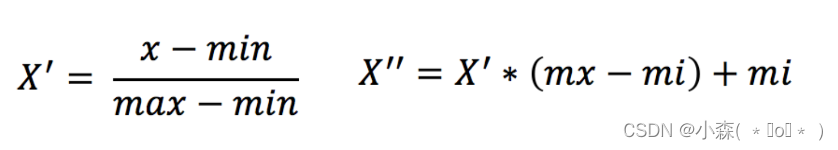 scikit-learn 中实现归一化的 API:
scikit-learn 中实现归一化的 API:
from sklearn.preprocessing import MinMaxScaler
def test():
# 1. 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化归一化对象
transformer = MinMaxScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)归一化受到最大值与最小值的影响,这种方法容易受到异常数据的影响, 鲁棒性较差,适合传统精确小数据场景
3. 标准化
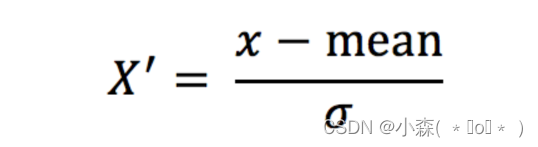
- mean 为特征的平均值
- σ 为特征的标准差
scikit-learn 中实现标准化的 API:
from sklearn.preprocessing import StandardScaler
def test():
# 1. 准备数据
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
# 2. 初始化标准化对象
transformer = StandardScaler()
# 3. 对原始特征进行变换
data = transformer.fit_transform(data)
# 4. 打印归一化后的结果
print(data)对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大
小结
- 归一化和标准化都能够将量纲不同的数据集缩放到相同范围内
- 归一化受到最大值与最小值的影响,这种方法容易受到异常数据的影响, 鲁棒性较差,适合传统精确小数据场景
- 对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,鲁棒性更好