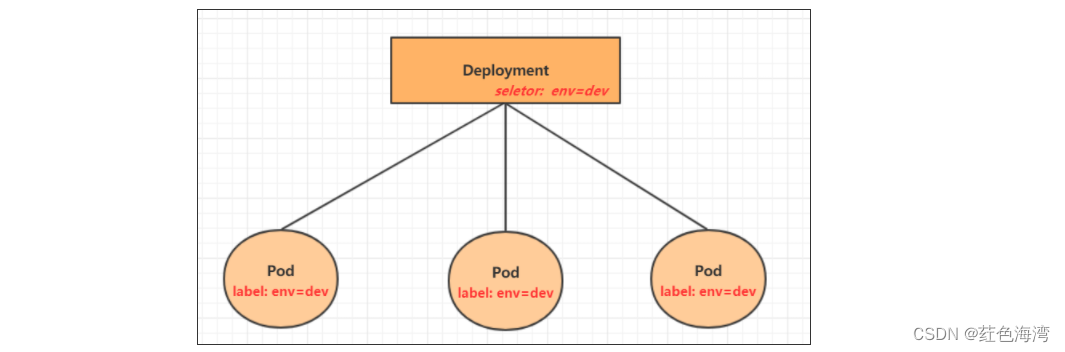
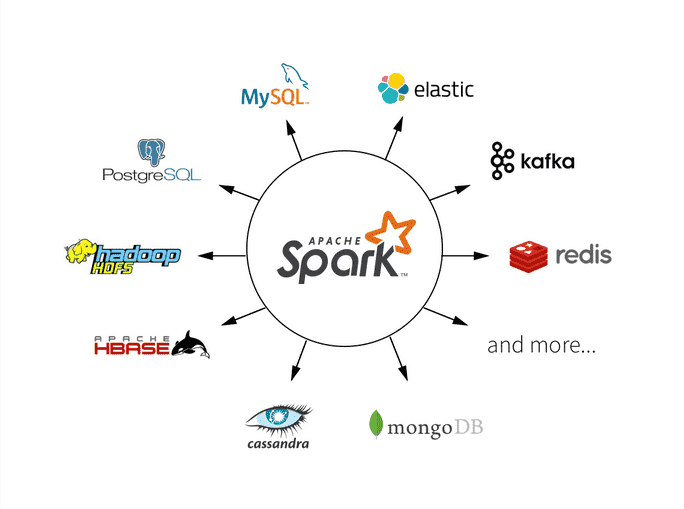
Spark的基本概念包括:
弹性分布式数据集(Resilient Distributed Dataset,简称RDD):它是Spark的核心数据结构,代表分布在集群中的可并行处理的数据集,可以在内存中存储。RDD具有容错能力,即使在节点失败时也可以自动恢复。
转换操作(Transformations):Spark提供了一系列转换操作来对RDD进行处理,例如map、filter、reduce等。这些转换操作是惰性的,即不会立即执行,而是在遇到一个动作操作时才会触发执行。
动作操作(Actions):Spark提供了一系列动作操作来触发计算并返回结果。例如,collect、count、reduce等。动作操作会触发Spark计算并返回结果。
Spark SQL:Spark SQL是Spark的模块,用于处理结构化数据。它可以将结构化数据加载到Spark中,并提供了类似于SQL的查询和操作接口。
Spark Streaming:Spark Streaming是Spark的模块,用于处理实时数据流。它可以将流式数据分成小批次,并以微批次的方式进行处理和分析。
MLlib:MLlib是Spark的机器学习库,提供了一系列机器学习算法和工具,用于处理大规模数据集的机器学习任务。
在大数据分析中,Spark广泛应用于以下场景:
批处理:Spark可以高效处理大规模数据集的批处理任务,例如数据清洗、ETL(提取、转换和加载)等。
实时分析:Spark Streaming可以实时处理和分析数据流。它可以用于实时监控、实时预测和实时反馈等场景。
交互式查询:通过Spark SQL,可以使用类似于SQL的语法对结构化数据进行查询和分析,实现交互式的数据探索和探索性分析。
机器学习:MLlib提供了丰富的机器学习算法和工具,可以在大规模数据集上进行机器学习任务,例如分类、聚类、回归等。
总之,Apache Spark通过其高效的数据处理和分析能力,成为处理大规模数据和实时数据的重要工具,在大数据分析中扮演着重要角色。






























![[蓝桥杯知识学习] 树链](https://img-blog.csdnimg.cn/direct/e6f3d15ce37c4114922c3a9b77d63308.png)