学习目标:
- 了解Kylin的工作原理和基本概念
- 理解Kylin在大数据分析中的作用和价值
- 学会使用Kylin进行数据建模、数据预处理和查询
学习内容:
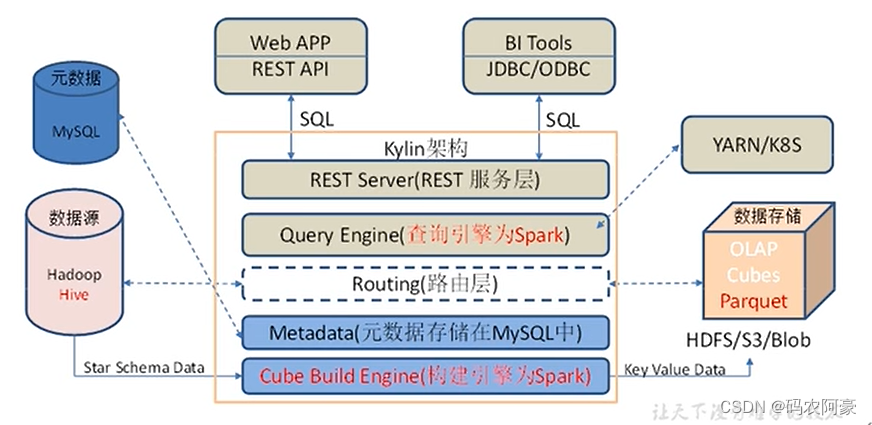
什么是Kylin?
- Kylin是一个开源的分布式分析引擎,专注于大数据的实时多维分析。它能够通过构建预计算的聚合数据集,提供快速的数据查询和分析功能。
Kylin的工作原理
- 构建Cube:Kylin通过构建多维数据Cube来实现快速查询。Cube是由多个维度和度量组成的数据集合,通过预计算的方式提供高性能的查询。
- 数据建模:使用Kylin的基本概念,如维度、度量、模式等,进行数据建模,定义Cube的结构。
- 数据预处理:将原始数据导入Kylin,并进行预处理、数据清洗和数据转换,以满足分析需求。
- 预计算和存储:Kylin使用高效的预计算算法和存储方式,将聚合数据集存储在高速存储介质中,以提供快速的查询性能。
Kylin的使用
- 安装和配置:了解Kylin的安装和配置过程,包括环境要求、依赖项安装和配置文件修改等。
- 数据建模:学会如何使用Kylin进行数据建模,包括定义维度、度量、模式和聚合函数等。
- 数据预处理:学习如何导入数据到Kylin,并进行数据清洗、转换和建立索引。
- 查询和分析:掌握Kylin的查询语法和查询优化技巧,以获取高性能的查询结果。
- 监控和调优:了解Kylin的监控和调优工具,以及如何通过参数调整和性能优化,提升Kylin的查询性能。
学习时间:
- 周一至周五晚上 7 点—晚上9点
- 周六上午 9 点-上午 11 点
- 周日下午 3 点-下午 6 点
学习产出:
什么是Kylin?
Kylin是一个开源的分布式分析引擎,专注于大数据的实时多维分析。它能够通过构建预计算的聚合数据集,提供快速的数据查询和分析功能。
Kylin是由阿里巴巴集团开发并开源的一个分布式分析引擎,专注于大数据的实时多维分析。它的目标是提供高性能的查询和数据分析能力,使用户能够快速获取数据洞察,并支持实时决策。
Kylin的核心理念是通过预计算和数据聚合的方式,为用户提供高效的查询性能。它将原始的大数据集合转化为多维数据集合,称为Cube,其中包含了多个维度和度量。Cube的构建过程是将原始数据进行预处理、聚合和存储,以提供快速的查询响应时间。
具体而言,Kylin可以实现以下功能和特性:
数据建模和查询语法:Kylin提供了灵活的数据建模能力,用户可以定义维度和度量,以及数据之间的关系。同时,它支持SQL查询语法,用户可以使用标准的SQL语句进行数据查询和分析。
数据预处理和存储:Kylin支持从多种数据源中导入数据,并进行数据清洗、转换和索引建立等预处理操作。处理后的数据会存储在高速存储介质中,如Hadoop HDFS或Apache Parquet格式文件。
高性能查询:Kylin利用预计算和聚合的优势,能够实现秒级甚至亚秒级的查询响应时间。它采用了多种查询优化技术,包括基于数据立方体的多维索引、查询剪枝和并行执行等,以提高查询性能。
扩展性和容错性:Kylin是一个分布式系统,可以在多个节点上进行部署,以实现横向扩展和高可用性。它支持数据的动态增量更新和增量构建,以及节点的容错和故障恢复。
总的来说,Kylin是一个功能强大的分布式分析引擎,通过构建预计算的聚合数据集,为用户提供快速的数据查询和分析能力。它已经在很多企业和组织中得到广泛应用,成为构建大数据分析之塔的重要工具之一。
Kylin的工作原理
- 构建Cube:Kylin通过构建多维数据Cube来实现快速查询。Cube是由多个维度和度量组成的数据集合,通过预计算的方式提供高性能的查询。
- 数据建模:使用Kylin的基本概念,如维度、度量、模式等,进行数据建模,定义Cube的结构。
- 数据预处理:将原始数据导入Kylin,并进行预处理、数据清洗和数据转换,以满足分析需求。
- 预计算和存储:Kylin使用高效的预计算算法和存储方式,将聚合数据集存储在高速存储介质中,以提供快速的查询性能。
构建Cube(构建多维数据集合): 在Kylin中,数据被组织成多维数据集合,即Cube。Cube由多个维度和度量组成,维度是表示数据汇总的属性,度量是用来度量和计算的指标。Cube可以通过以下代码进行构建:
CubeInstance cubeInstance = CubeManager.getInstance(config).createCube(cubeDesc);
上述代码中,CubeInstance表示已构建的Cube实例,CubeManager负责管理Cube的构建和操作,cubeDesc包含了Cube的描述信息。
数据建模(定义维度和度量): 数据建模是定义Cube的结构,包括维度和度量的定义。维度描述了数据的特征,如时间、地理位置等,度量描述了需要分析和计算的指标。以下是一个示例代码,定义了时间维度和销售量度量:
DimensionDesc timeDimension = new DimensionDesc("time", "timestamp");
MeasureDesc salesMeasure = new MeasureDesc("sales", "sum");
CubeDesc cubeDesc = new CubeDesc("sales_cube");
cubeDesc.addDimension(timeDimension);
cubeDesc.addMeasure(salesMeasure);
上述代码中,DimensionDesc表示维度的描述,MeasureDesc表示度量的描述,CubeDesc表示Cube的描述。
数据预处理(导入、清洗、转换): 在Kylin中,数据需要经过预处理步骤,包括数据导入、数据清洗和数据转换。以下是一个示例代码,用于将数据导入Kylin:
DataModelManager dataModelManager = DataModelManager.getInstance(config);
DataModelDesc dataModelDesc = dataModelManager.getDataModelDesc(dataModel);
IDataLoader dataLoader = new KylinDataLoader();
dataLoader.loadConfiguration(dataModelDesc, inputPath);
dataLoader.load();
上述代码中,DataModelManager负责管理数据模型,DataModelDesc描述了数据模型的属性,IDataLoader定义了数据加载的接口。
预计算和存储: Kylin使用高效的预计算算法和存储方式来提供快速的查询性能。以下是一个示例代码,用于构建Cube的预计算和存储:
CubeSegment cubeSegment = CubeManager.getInstance(config).buildNewSegment(cubeInstance, startTime, endTime);
KylinConfig kylinConfig = cubeInstance.getConfig();
CubeTaskExecutor cubeTaskExecutor = CubeTaskExecutor.create(kylinConfig);
cubeTaskExecutor.execute(cubeSegment, "/path/to/storage");
上述代码中,CubeSegment表示Cube的分段,kylinConfig存储Kylin的配置信息,CubeTaskExecutor负责执行任务。
通过构建Cube、定义维度和度量、数据预处理和预计算存储,Kylin实现了快速的查询性能和多维分析能力。这些工作原理的代码示例可以帮助理解Kylin的工作过程。
Kylin的使用
- 安装和配置:了解Kylin的安装和配置过程,包括环境要求、依赖项安装和配置文件修改等。
- 数据建模:学会如何使用Kylin进行数据建模,包括定义维度、度量、模式和聚合函数等。
- 数据预处理:学习如何导入数据到Kylin,并进行数据清洗、转换和建立索引。
- 查询和分析:掌握Kylin的查询语法和查询优化技巧,以获取高性能的查询结果。
- 监控和调优:了解Kylin的监控和调优工具,以及如何通过参数调整和性能优化,提升Kylin的查询性能。
安装和配置:
- 下载和安装Kylin:
wget http://mirror.bit.edu.cn/apache/kylin/apache-kylin-${version}/apache-kylin-${version}-bin-hbase1x.tar.gz
tar -zxvf apache-kylin-${version}-bin-hbase1x.tar.gz
cd apache-kylin-${version}-bin-hbase1x
- 配置Kylin: 在
conf/kylin.properties文件中,修改以下配置:
# 指定Hadoop集群信息
kylin.hadoop.conf.dir=/etc/hadoop/conf
# 指定HBase集群信息
kylin.hbase.cluster-filesystem=fhdfs://hadoop-cluster
数据建模:
- 定义维度: 在
cubeDesc文件中,添加以下代码定义一个时间维度:
{
"name": "time",
"column": "time",
"datatype": "timestamp",
"hierarchy": "true"
}
- 定义度量: 在
cubeDesc文件中,添加以下代码定义一个销售量度量:
{
"name": "sales",
"column": "sales",
"datatype": "bigint"
}
数据预处理:
- 导入数据: 使用以下代码将数据导入Kylin:
./bin/kylin.sh org.apache.kylin.tool.data.Tool \
import --project ${projectName} --input ${inputPath} \
--hive-database ${hiveDatabase} --hive-table ${hiveTable}
- 数据清洗和转换: 使用以下代码进行数据清洗和转换操作:
./bin/kylin.sh org.apache.kylin.tool.data.Tool \
--project ${projectName} \
--hive-database ${hiveDatabase} --hive-table ${hiveTable} \
--hive-table-fmt ${hiveTableFmt} --bad-records-logger ${badRecordsLogger} \
--bad-records-redirect ${badRecordsRedirect} --delete-old-hive-table ${deleteOldHiveTable}
查询和分析:
- 使用SQL查询: 使用以下代码进行SQL查询:
./bin/kylin.sh org.apache.kylin.tool.query.QueryTool \
--project ${projectName} \
--sql "${sqlStatement}"
- 使用Kylin Query API: 使用以下代码进行Kylin Query API查询:
QueryRequest queryRequest = new QueryRequest();
queryRequest.setSql("${sqlStatement}");
queryRequest.setProject(${projectName});
QueryResponse response = KylinRestAPI.query(queryRequest);
监控和调优:
- 查看任务执行情况: 使用以下代码查看任务执行情况:
./bin/kylin.sh org.apache.kylin.tool.job.JobManager \
--project ${projectName} \
--monitor ${monitorTime}
- 调优Cube: 使用以下代码调优Cube:
./bin/kylin.sh org.apache.kylin.tool.statscli.StatsManagerCLI \
--update-cube ${cubeName}
通过以上的代码示例,你可以学习Kylin的使用方式,包括安装和配置、数据建模、数据预处理、查询和分析以及监控和调优等方面的知识。





























![基于博弈树的开源五子棋AI教程[1 位棋盘]](https://img-blog.csdnimg.cn/direct/992576eab01542c7b35c2247c778761a.png)