说明:仅供学习使用,请勿用于非法用途,若有侵权,请联系博主删除
作者:zhu6201976
一、什么是请求指纹检测?
TLS/JA3、HTTP/2 指纹检测是一种网络流量分析技术,用于识别和分析网络通信中使用的加密协议和通信特征。这些技术通常用于网络安全领域,以便检测恶意活动或进行流量分析。以下是对每个概念的详细描述:
1.TLS(Transport Layer Security)
- 定义: TLS是一种安全通信协议,用于在两个通信应用程序之间提供保密性和数据完整性。
- 功能: TLS通常用于在Web浏览器和服务器之间加密数据传输,确保通信的机密性,防止数据被窃听或篡改。
- TLS指纹检测: TLS指纹检测是通过分析TLS握手过程中的参数,如客户端和服务器支持的加密套件,生成唯一的标识符(指纹)。这有助于识别特定应用程序或设备的TLS实现。
2.JA3(TLS Fingerprinting)
- 定义: JA3是一种用于识别TLS客户端的指纹生成技术。
- 功能: JA3通过分析TLS握手中客户端发送的信息,如支持的加密算法、TLS版本等,生成一个唯一的字符串,代表客户端的TLS行为。
- JA3指纹检测: JA3指纹检测用于追踪和识别TLS客户端的特征,有助于发现不同设备或应用程序使用的TLS配置。
3.HTTP/2
- 定义: HTTP/2是HTTP协议的一种新版本,用于提高Web性能和效率。
- 功能: HTTP/2引入了多路复用、头部压缩等功能,以减少延迟和提高网络性能。
- HTTP/2指纹检测: HTTP/2指纹检测通过分析网络通信中的HTTP/2协议头部,识别使用HTTP/2的通信流量。这有助于了解网站或应用程序是否采用了HTTP/2协议。
二、如何绕过请求指纹检测?
1.通过原生JS实现请求
原理:网页运行在浏览器中,浏览器所支持的官方语言是JS,因此,通过原生JS构造并发送请求,其TLS/JA3指纹是正常的,理论上不会被拦截。
2.实现了指纹篡改的第三方请求库
某些第三方请求库,底层修改了TLS/JA3的生成方式,因此可以绕过这些检测。
如:
Python的curl_cffi库GitHub - yifeikong/curl_cffi: Python binding for curl-impersonate via cffi. A http client that can impersonate browser tls/ja3/http2 fingerprints.
Go语言版的requests
GitHub - asmcos/requests: A golang HTTP client library. Salute to python requests.
3.wget等Linux命令
在所有的请求工具中,wget请求指纹暂未被列如黑名单,实测可以成功拿到正确响应
三、实战案例
1.url
aHR0cHM6Ly9kb29kcy5wcm8vZS9jMHh2NGplYjdtbmE=
2.说明
该网站使用了简单的CloudFlare风控,而简单版的CloudFlare风控底层检测了常见语言的请求库TLS/JA3指纹,收集并列入了黑名单。因此,非浏览器的请求指纹理论上都会被拒绝响应,比如返回如下信息:
<!DOCTYPE html>
<html lang="en-US">
<head>
<title>Just a moment...</title>
</head>
</html>一旦检测到非浏览器指纹请求,则返回类似 Just a moment... 错误信息。
3.绕过
此处采用最简单的Python第三方请求库curl_cffi实现绕过,代码如下:
from base64 import b64decode
import requests
from curl_cffi import requests as req
url = b64decode('aHR0cHM6Ly9kb29kcy5wcm8vZS9jMHh2NGplYjdtbmE=').decode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
}
resp1 = requests.get(url, headers=headers)
print('resp1', resp1.text)
resp2 = req.get(url, headers=headers, impersonate='chrome110')
print('resp2', resp2.text)
运行结果:
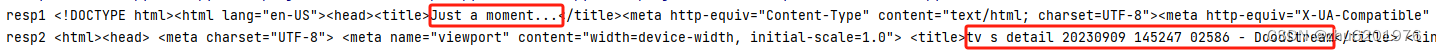
显然,同一个url,curl_cffi成功拿到了正确响应。