首先,需要导入必要的库,包括torch、torchtext、numpy等:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torchtext.datasets import AG_NEWS
from torchtext.data.utils import get_tokenizer
from collections import Counter
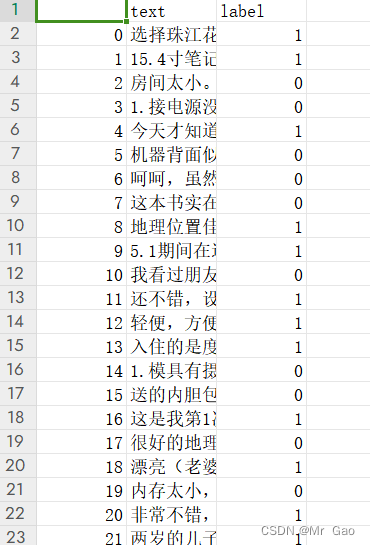
然后,我们需要加载数据集并进行数据预处理。在这里,我们使用AG News数据集,其中包含120,000个新闻文本,分为四个不同的类别:World、Sports、Business和Sci/Tech。我们首先定义一个函数来预处理数据:
# 加载数据集
train_dataset, test_dataset = AG_NEWS()
# 定义tokenizer,用于将文本转换为单词列表
tokenizer = get_tokenizer('basic_english')
# 定义函数preprocess,用于将文本转换为数值向量
def preprocess(dataset):
# 定义空列表,用于存放文本
data = []
# 遍历数据集中的每个样本
for (label, text) in dataset:
# 将文本转换为单词列表
tokens = tokenizer(text)
# 将单词列表转换为数值向量
vector = [vocab.stoi[token] for token in tokens]
# 将标签和数值向量打包成元组,并添加到data列表中
data.append((label, torch.tensor(vector)))
return data
# 统计数据集中所有单词的出现频率,并将出现频率最高的50000个单词作为词汇表
counter = Counter()
for (label, text) in train_dataset:
tokens = tokenizer(text)
counter.update(tokens)
vocab = torchtext.vocab.Vocab(counter, max_size=50000)
# 使用preprocess函数将数据集转换为数值向量形式
train_data = preprocess(train_dataset)
test_data = preprocess(test_dataset)
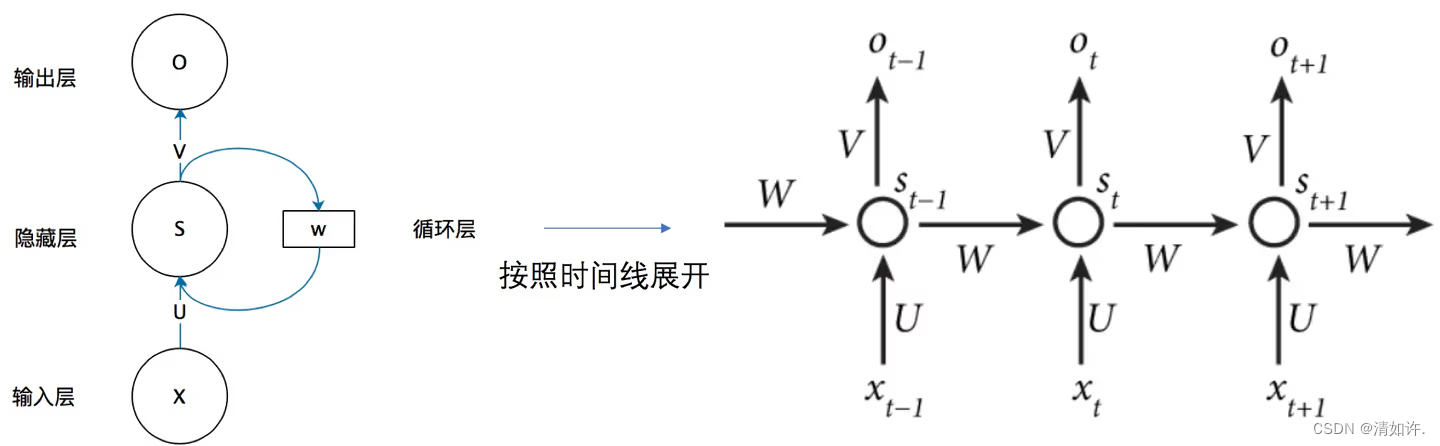
接下来,我们定义一个RNN模型,用于对文本进行分类。这里我们使用LSTM作为我们的RNN模型,并将其应用于文本分类任务。LSTM是一种特殊的RNN模型,它能够在处理长序列时更好地保留先前的信息。下面是代码:
class LSTMModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(LSTMModel, self).__init__()
self.embedding = nn.Embedding(input_dim, hidden_dim)
self.lstm = nn.LSTM(hidden_dim, hidden_dim)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# 将输入x的每个元素(即每个数值向量)通过embedding层转换为向量
embedded = self.embedding(x)
# 将embedding后的向量输入到LSTM中
output, (hidden, cell) = self.lstm(embedded)
# 取LSTM的最后一个输出作为模型的输出
prediction = self.fc(hidden[-1])
return prediction
在上面的代码中,我们首先定义了一个名为LSTMModel的类,它继承自nn.Module类。在__init__中,我们定义了三个层:embedding层、LSTM层和全连接层(也称为线性层)。embedding层用于将输入的数值向量转换为向量表示,LSTM层用于在处理序列数据时保留先前的信息,全连接层用于将LSTM输出转换为预测标签。
在forward函数中,我们首先通过embedding层将输入x转换为向量表示,然后将其输入到LSTM中。由于LSTM是一种可以处理序列数据的RNN模型,因此它能够保留先前的信息,并生成一个输出向量。在这里,我们选择使用LSTM的最后一个输出作为模型的输出向量。最后,我们将输出向量输入到全连接层中,以生成最终的预测标签。
接下来,我们需要训练我们的模型。我们首先定义一个函数,用于计算模型在测试集上的准确率:
def evaluate(model, data):
correct = 0
total = 0
with torch.no_grad():
for (label, text) in data:
output = model(text.unsqueeze(0)) # 将输入张量增加一维,以便输入模型
predicted = torch.argmax(output.squeeze()) # 取最大值作为预测结果
if predicted == label:
correct += 1
total += 1
return correct / total
在上面的代码中,我们定义了一个名为evaluate的函数,该函数接受一个模型和数据作为输入,并返回模型在数据上的准确率。在函数中,我们首先将输入张量的维度增加一维,以便输入到模型中。然后,我们使用torch.argmax函数找到输出向量中的最大值,并将其作为预测结果。最后,我们计算模型在测试集上的准确率。
现在我们可以开始训练我们的模型了。我们首先定义一些超参数:
input_dim = len(vocab)
hidden_dim = 128
output_dim = 4
batch_size = 64
learning_rate = 0.001
num_epochs = 5
这里,我们定义了词汇表的大小、隐藏层的维度、输出维度、批次大小、学习率和训练轮数等超参数。
接下来,我们实例化我们的模型,并定义损失函数和优化器:
model = LSTMModel(input_dim, hidden_dim, output_dim)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
在上面的代码中,我们实例化了我们的模型LSTMModel,并定义了损失函数CrossEntropyLoss和优化器Adam。
现在,我们可以开始训练我们的模型了。对于每个epoch,我们将训练集分成若干个小批次,并对每个小批次进行训练。在每个小批次训练结束后,我们将测试集输入到我们的模型中,并计算模型的准确率。最后,我们输出每个epoch的损失和准确率:
for epoch in range(num_epochs):
np.random.shuffle(train_data)
train_loss = 0
train_correct = 0
train_total = 0
for i in range(0, len(train_data), batch_size):
batch = train_data[i:i+batch_size]
labels, texts = zip(*batch)
labels = torch.tensor(labels)
texts = nn.utils.rnn.pad_sequence(texts, batch_first=True)
optimizer.zero_grad()
output = model(texts)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * len(batch)
train_correct += torch.sum(torch.argmax(output, dim=1) == labels).item()
train_total += len(batch)
train_accuracy = train_correct / train_total
test_accuracy = evaluate(model, test_data)
print('Epoch [%d/%d], Loss: %.4f, Train Acc: %.4f, Test Acc: %.4f'
% (epoch+1, num_epochs, train_loss / len(train_data),
train_accuracy, test_accuracy))
在上面的代码中,我们使用np.random.shuffle函数对训练数据进行随机化处理,并按照batch_size的大小将其分成若干个小批次。在每个小批次训练结束后,我们将记录损失值、训练集准确率和测试集准确率。最后,我们输出每个epoch的损失和准确率。
到此,我们就完成了基于PyTorch的RNN实现文本分类的代码和解释。