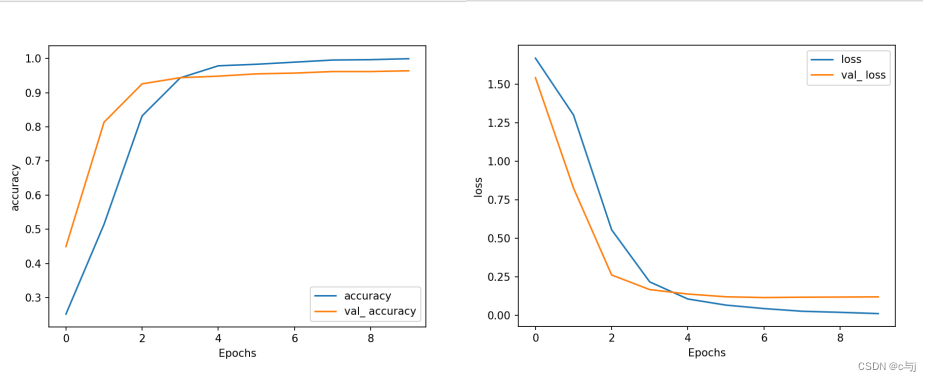
以imdb公开数据集为例,bert模型可以在huggingface上自行挑选
1.导入必要的库
import os
import torch
from torch.utils.data import DataLoader, TensorDataset, random_split
from transformers import BertTokenizer, BertModel, BertConfig
from torch import nn
from torch.optim import AdamW
import numpy as np
from sklearn.metrics import accuracy_score
import pandas as pd
from tqdm import tqdm
device = torch.device("cuda:0")
print(device)
2.加载和预处理数据:读取数据,将其转换为适合BERT的格式,并将评分映射到三个类别。
import random
def load_imdb_dataset_and_create_multiclass_labels(path_to_data, split="train"):
print(f"load start: {
split}")
reviews = []
labels = [] # 0 for low, 1 for medium, 2 for high
for label in ["pos", "neg"]:
labeled_path = os.path.join(path_to_data, split, label)
for file in os.listdir(labeled_path):
if file.endswith('.txt'):
with open(os.path.join(labeled_path, file), 'r', encoding='utf-8') as f:
reviews.append(f.read())
if label == "neg":
# Randomly assign negative reviews to low or medium
labels.append(random.choice([0, 1]))
else:
labels.append(2) # Assign positive reviews to high
return reviews[:1000], labels[:1000]
#加载数据集
train_texts, train_labels = load_imdb_dataset_and_create_multiclass_labels("./data/aclImdb", split="train")
test_texts, test_labels = load_imdb_dataset_and_create_multiclass_labels("./data/aclImdb", split="test")
print("load okk")
#样本数量
print("train_texts: ",len(train_texts))
print("test_texts: ",len(test_texts))
3.文本转换为BERT的输入格式
tokenizer = BertTokenizer.from_pretrained('./bert_pretrain')
def encode_texts(tokenizer, texts, max_len=512):
input_ids = []
attention_masks = []
for text in texts:
encoded = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=max_len,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
input_ids.append(encoded['input_ids'])
attention_masks.append(encoded['attention_mask'])
return torch.cat(input_ids, dim=0), torch.cat(attention_masks, dim=0)
train_inputs, train_masks = encode_texts(tokenizer, train_texts)
test_inputs, test_masks = encode_texts(tokenizer, test_texts)
print("input transfromer encode done")
4.创建TensorDataset和DataLoader
train_labels = torch.tensor(train_labels)
test_labels = torch.tensor(test_labels)
train_dataset = TensorDataset(train_inputs, train_masks, train_labels)
test_dataset = TensorDataset(test_inputs, test_masks, test_labels)
# Split the dataset into train and validation sets
train_size = int(0.9 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_dataset, val_dataset = random_split(train_dataset, [train_size, val_size])
train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=128, shuffle=False)
test_dataloader = DataLoader(test_dataset, batch_size=128, shuffle=False)
5.构建模型:使用BERT进行多分类任务
class BertForMultiLabelClassification(nn.Module):
def __init__(self):
super(BertForMultiLabelClassification, self).__init__()
self.bert = BertModel.from_pretrained('./bert_pretrain')
self.dropout = nn.Dropout(0.1)
self.classifier = nn.Linear(self.bert.config.hidden_size, 3) # 3类
def forward(self, input_ids, attention_mask):
_, pooled_output = self.bert(input_ids=input_ids, attention_mask=attention_mask, return_dict=False)
pooled_output = self.dropout(pooled_output)
return self.classifier(pooled_output)
6.训练和评估模型
# 初始化模型、优化器和损失函数
model = BertForMultiLabelClassification()
# 使用多GPU
# if MULTI_GPU:
# model = nn.DataParallel(model)
model.to(device)
optimizer = AdamW(model.parameters(), lr=2e-5)
loss_fn = nn.CrossEntropyLoss()
# 训练函数
def train(model, dataloader, optimizer, loss_fn, device):
model.train()
total_loss = 0
for batch in dataloader:
batch = tuple(b.to(device) for b in batch)
inputs, masks, labels = batch
optimizer.zero_grad()
outputs = model(input_ids=inputs, attention_mask=masks)
loss = loss_fn(outputs, labels)
total_loss += loss.item()
loss.backward()
optimizer.step()
average_loss = total_loss / len(dataloader)
return average_loss
# 评估函数
def evaluate(model, dataloader, loss_fn, device):
model.eval()
total_loss = 0
predictions, true_labels = [], []
with torch.no_grad():
for batch in dataloader:
batch = tuple(b.to(device) for b in batch)
inputs, masks, labels = batch
outputs = model(input_ids=inputs, attention_mask=masks)
loss = loss_fn(outputs, labels)
total_loss += loss.item()
logits = outputs.detach().cpu().numpy()
label_ids = labels.to('cpu').numpy()
predictions.append(logits)
true_labels.append(label_ids)
average_loss = total_loss / len(dataloader)
flat_predictions = np.concatenate(predictions, axis=0)
flat_predictions = np.argmax(flat_predictions, axis=1).flatten()
flat_true_labels = np.concatenate(true_labels, axis=0)
accuracy = accuracy_score(flat_true_labels, flat_predictions)
return average_loss, accuracy
# 训练和评估循环
for epoch in range(3): # 假设训练3个周期
train_loss = train(model, train_dataloader, optimizer, loss_fn, device)
val_loss, val_accuracy = evaluate(model, val_dataloader, loss_fn, device)
print(f"Epoch {
epoch+1}")
print(f"Train Loss: {
train_loss:.3f}")
print(f"Validation Loss: {
val_loss:.3f}, Accuracy: {
val_accuracy:.3f}")
# 在测试集上评估模型性能
test_loss, test_accuracy = evaluate(model, test_dataloader, loss_fn, device)
print(f"Test Loss: {
test_loss:.3f}, Accuracy: {
test_accuracy:.3f}")
#保存模型
torch.save(model.state_dict(), "./model/bert_multiclass_imdb_model.pt")
7.模型预测
from transformers import BertModel
import torch
def predict(texts, model, tokenizer, device, max_len=128):
# 将文本编码为BERT的输入格式
def encode_texts(tokenizer, texts, max_len):
input_ids = []
attention_masks = []
for text in texts:
encoded = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=max_len,
pad_to_max_length=True,
return_attention_mask=True,
return_tensors='pt',
)
input_ids.append(encoded['input_ids'])
attention_masks.append(encoded['attention_mask'])
return torch.cat(input_ids, dim=0), torch.cat(attention_masks, dim=0)
model.eval() # 将模型设置为评估模式
predictions = []
input_ids, attention_masks = encode_texts(tokenizer, texts, max_len)
input_ids = input_ids.to(device)
attention_masks = attention_masks.to(device)
with torch.no_grad():
outputs = model(input_ids, attention_mask=attention_masks)
logits = outputs.detach().cpu().numpy()
predictions = np.argmax(logits, axis=1)
return predictions
# 示例文本
texts = ["I very like the movie", "the movie is so bad"]
# 调用预测函数
# 初始化模型
device = torch.device("cuda:0")
model = BertForMultiLabelClassification()
model.to(device)
# 加载模型状态
model.load_state_dict(torch.load('./model/bert_multiclass_imdb_model.pt'))
# 将模型设置为评估模式
model.eval()
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('./bert_pretrain')
predictions = predict(texts, model, tokenizer, device)
# 输出预测结果
for text, pred in zip(texts, predictions):
print(f"Text: {
text}, Predicted category: {
pred}")