说明:
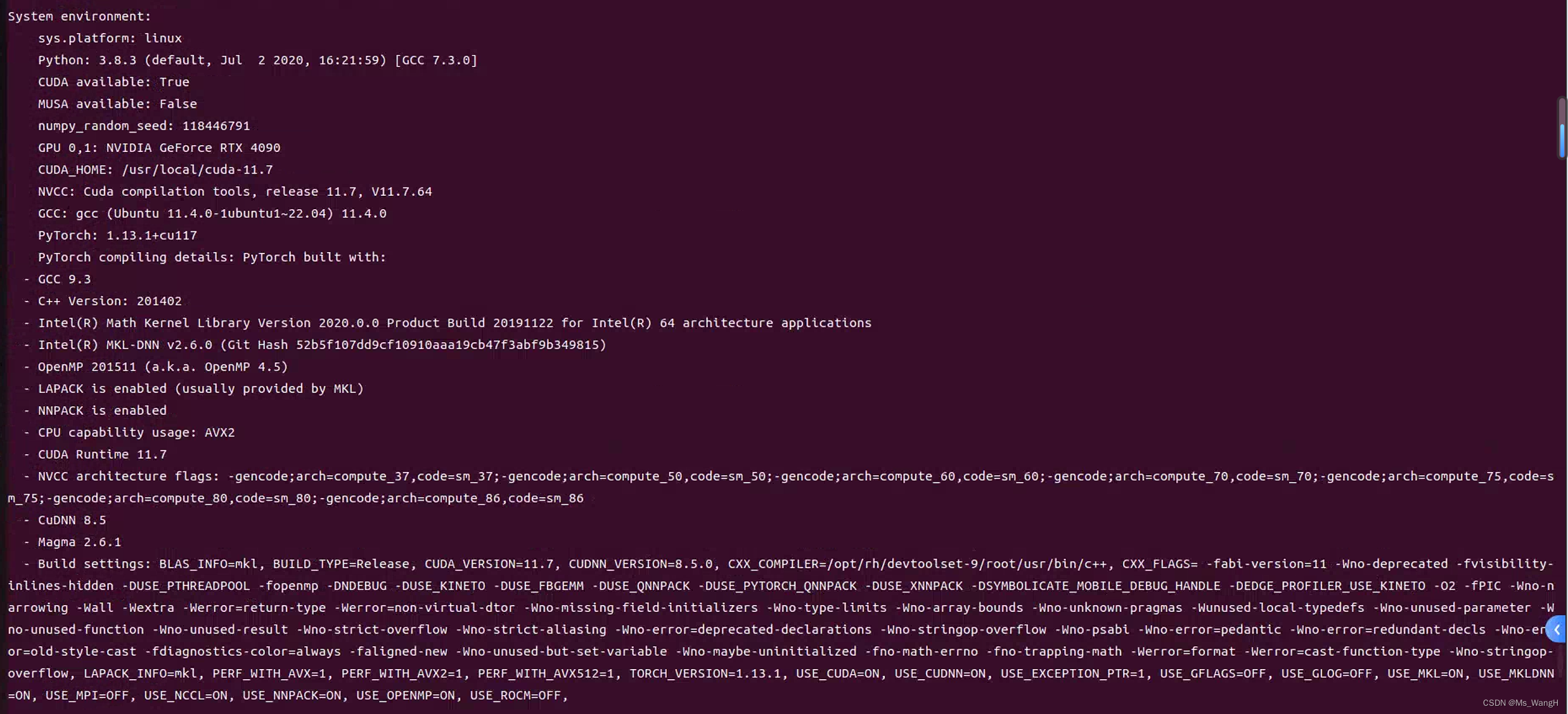
[root@node101 ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[root@node101 ~]# gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/libexec/gcc/x86_64-redhat-linux/4.8.5/lto-wrapper
Target: x86_64-redhat-linux
Configured with: ../configure --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap --enable-shared --enable-threads=posix --enable-checking=release --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu --enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin --enable-initfini-array --disable-libgcj --with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install --with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install --enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-redhat-linux
Thread model: posix
gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC)
[root@node101 ~]# which mpirun
/opt/gpuApp/ompi/bin/mpirun
[root@node101 ~]# which icc
/opt/intel/compilers_and_libraries_2020.1.211/linux/bin/intel64/icc
[root@node101 ~]# which nvcc
/usr/local/cuda-12.3/bin/nvcc
[root@node101 ~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Thread(s) per core: 2
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: AuthenticAMD
CPU family: 23
Model: 49
Model name: AMD EPYC 7302 16-Core Processor
Stepping: 0
CPU MHz: 1500.000
CPU max MHz: 3000.0000
CPU min MHz: 1500.0000
BogoMIPS: 6000.34
Virtualization: AMD-V
L1d cache: 32K
L1i cache: 32K
L2 cache: 512K
L3 cache: 16384K
NUMA node0 CPU(s): 0-31
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc art rep_good nopl nonstop_tsc extd_apicid aperfmperf eagerfpu pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_l2 cpb cat_l3 cdp_l3 hw_pstate sme retpoline_amd ssbd ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip overflow_recov succor smca
[root@node101 ~]# free -g
total used free shared buff/cache available
Mem: 251 5 227 0 18 244
Swap: 127 0 127
[root@node101 ~]#
lammps支持单精度,也支持双精度。受限于4070Ti,其双精度能力很差,故本次使用单精度方式进行使用。
显卡的SM值可以通过cuda自带的工具查询:
[root@node101 tools]#ls /usr/local/cuda/samples/1_Utilities/deviceQuery
deviceQuery deviceQuery.cpp deviceQuery.o Makefile NsightEclipse.xml readme.txt
[root@node101 tools]#cd /usr/local/cuda/samples/1_Utilities/deviceQuery
[root@node101 deviceQuery]#./deviceQuery
1、环境文件
cat << EOF > ~/lammps-gpu-env.sh
#!/bin/bash
source /opt/intel/compilers_and_libraries_2020/linux/bin/compilervars.sh intel64
export PATH=/usr/local/cuda-12.3/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.3/targets/x86_64-linux/lib:$LD_LIBRARY_PATH
export C_INCLUDE_PATH=/usr/local/cuda-12.3/targets/x86_64-linux/include:$C_INCLUDE_PATH
EOF
2、gdrcopy
cd gpu-lammps/
tar -zxvf gdrcopy-2.0.tar.gz
cd gdrcopy-2.0/
mkdir -p /opt/gpuApp/gdrcopy/include
mkdir -p /opt/gpuApp/gdrcopy/lib64
make PREFIX=/opt/gpuApp/gdrcopy lib lib_install
cat << EOF >> ~/lammps-gpu-env.sh
export PATH=/opt/gpuApp/gdrcopy/include:\$PATH
export CPATH=/opt/gpuApp/gdrcopy/include:\$CPATH
export LD_LIBRARY_PATH=/opt/gpuApp/gdrcopy/lib64:\$LD_LIBRARY_PATH
EOF
3、ucx
cd ~/gpu-lammps/
tar -zxvf ucx-1.7.0.tar.gz
cd ucx-1.7.0/
./configure --prefix=/opt/gpuApp/ucx --enable-optimizations --disable-logging --disable-debug --disable-assertions --disable-params-check --disable-doxygen-doc --with-cuda=/usr/local/cuda --with-gdrcopy=/opt/gpuApp/gdrcopy/ --with-verbs --with-rdmacm
……………………………….
configure: =========================================================
configure: UCX build configuration:
configure: Preprocessor flags: -DCPU_FLAGS="|avx" -I${abs_top_srcdir}/src -I${abs_top_builddir} -I${abs_top_builddir}/src
configure: C flags: -O3 -g -Wall -Werror -mavx
configure: C++ flags: -O3 -g -Wall -Werror -mavx
configure: Multi-thread: Disabled
configure: MPI tests: Disabled
configure: Devel headers:
configure: UCT modules: < cuda ib rdmacm cma >
configure: CUDA modules: < gdrcopy >
configure: ROCM modules: < >
configure: IB modules: < >
configure: UCM modules: < cuda >
configure: Perf modules: < cuda >
configure: =========================================================
…………..
cat << EOF >> ~/lammps-gpu-env.sh
export PATH=/opt/gpuApp/ucx/bin:\$PATH
export LD_LIBRARY_PATH=/opt/gpuApp/ucx/lib:\$LD_LIBRARY_PATH
EOF
4、openmpi
[root@node101 gpu-lammps]# cd ~/gpu-lammps/
[root@node101 gpu-lammps]# tar -xvf openmpi-4.1.6.tar
[root@node101 gpu-lammps]# cd openmpi-4.1.6/
[root@node101 openmpi-4.1.6]# ./configure --prefix=/opt/gpuApp/ompi --enable-mpirun-prefix-by-default --enable-cuda --enable-dlopen --enable-weak-symbols --enable-heterogeneous --enable-binaries --enable-script-wrapper-compilers --enable-orterun-prefix-by-default --enable-mca-no-build=btl-uct --with-cuda --with-pmix --with-verbs --with-ucx=/opt/gpuApp/ucx
…………
Open MPI configuration:
-----------------------
Version: 4.1.6
Build MPI C bindings: yes
Build MPI C++ bindings (deprecated): no
Build MPI Fortran bindings: mpif.h, use mpi
MPI Build Java bindings (experimental): no
Build Open SHMEM support: yes
Debug build: no
Platform file: (none)
Miscellaneous
-----------------------
CUDA support: yes
HWLOC support: internal
Libevent support: internal
Open UCC: no
PMIx support: Internal
Transports
-----------------------
Cisco usNIC: no
Cray uGNI (Gemini/Aries): no
Intel Omnipath (PSM2): no
Intel TrueScale (PSM): no
Mellanox MXM: no
Open UCX: yes
OpenFabrics OFI Libfabric: no
OpenFabrics Verbs: yes
Portals4: no
Shared memory/copy in+copy out: yes
Shared memory/Linux CMA: yes
Shared memory/Linux KNEM: no
Shared memory/XPMEM: no
TCP: yes
Resource Managers
-----------------------
Cray Alps: no
Grid Engine: no
LSF: no
Moab: no
Slurm: yes
ssh/rsh: yes
Torque: no
OMPIO File Systems
-----------------------
DDN Infinite Memory Engine: no
Generic Unix FS: yes
IBM Spectrum Scale/GPFS: no
Lustre: no
PVFS2/OrangeFS: no
[root@node101 openmpi-4.1.6]# make -j 32
[root@node101 openmpi-4.1.6]# make install
[root@node101 openmpi-4.1.6]# cat << EOF >> ~/lammps-gpu-env.sh
export PATH=/opt/gpuApp/ompi/bin:\$PATH
export LD_LIBRARY_PATH=/opt/gpuApp/ompi/lib:\$LD_LIBRARY_PATH
export INCLUDE=/opt/gpuApp/ompi/include:\$INCLUDE
EOF
[root@node101 openmpi-4.1.6]#
5、lammps-cpu
[root@node101 gpu-lammps]# tar -zxvf lammps-2Aug2023.tar.gz
[root@node101 gpu-lammps]# cd lammps-2Aug2023/src
[root@node101 src]#source ~/lammps-gpu-env.sh
[root@node101 src]# make yes-all
[root@node101 src]# make no-lib
[root@node101 src]# cp MAKE/OPTIONS/Makefile.intel_cpu_openmpi MAKE/Makefile.intel
[root@node101 src]# make -j 32 intel
[root@node101 src]# cp lmp_intel lmp_intel_cpu
6、lammps-gpu
[root@node101 gpu-lammps]# cd lammps-2Aug2023/lib/gpu/
[root@node101 gpu]#source ~/lammps-gpu-env.sh
[root@node101 gpu]# vi Makefile.linux ##修改SM和CUDA_PRECISION[强撞1]
[root@node101 gpu]# make -f Makefile.linux ##编译GPU库
[root@node101 gpu]# ./nvc_get_devices
Found 1 platform(s).
CUDA Driver Version: 12.30
Device 0: "NVIDIA GeForce RTX 4070 Ti"
Type of device: GPU
Compute capability: 8.9
Double precision support: Yes
Total amount of global memory: 11.7281 GB
Number of compute units/multiprocessors: 60
Number of cores: 11520
Total amount of constant memory: 65536 bytes
Total amount of local/shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per block: 1024
Maximum group size (# of threads per block) 1024 x 1024 x 64
Maximum item sizes (# threads for each dim) 2147483647 x 65535 x 65535
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Clock rate: 2.61 GHz
Run time limit on kernels: No
Integrated: No
Support host page-locked memory mapping: Yes
Compute mode: Default
Concurrent kernel execution: Yes
Device has ECC support enabled: No
Device 1: "NVIDIA GeForce RTX 4070 Ti"
Type of device: GPU
Compute capability: 8.9
Double precision support: Yes
Total amount of global memory: 11.7281 GB
Number of compute units/multiprocessors: 60
Number of cores: 11520
Total amount of constant memory: 65536 bytes
Total amount of local/shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per block: 1024
Maximum group size (# of threads per block) 1024 x 1024 x 64
Maximum item sizes (# threads for each dim) 2147483647 x 65535 x 65535
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Clock rate: 2.61 GHz
Run time limit on kernels: No
Integrated: No
Support host page-locked memory mapping: Yes
Compute mode: Default
Concurrent kernel execution: Yes
Device has ECC support enabled: No
Device 2: "NVIDIA GeForce RTX 4070 Ti"
Type of device: GPU
Compute capability: 8.9
Double precision support: Yes
Total amount of global memory: 11.7281 GB
Number of compute units/multiprocessors: 60
Number of cores: 11520
Total amount of constant memory: 65536 bytes
Total amount of local/shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per block: 1024
Maximum group size (# of threads per block) 1024 x 1024 x 64
Maximum item sizes (# threads for each dim) 2147483647 x 65535 x 65535
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Clock rate: 2.61 GHz
Run time limit on kernels: No
Integrated: No
Support host page-locked memory mapping: Yes
Compute mode: Default
Concurrent kernel execution: Yes
Device has ECC support enabled: No
Device 3: "NVIDIA GeForce RTX 4070 Ti"
Type of device: GPU
Compute capability: 8.9
Double precision support: Yes
Total amount of global memory: 11.7281 GB
Number of compute units/multiprocessors: 60
Number of cores: 11520
Total amount of constant memory: 65536 bytes
Total amount of local/shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per block: 1024
Maximum group size (# of threads per block) 1024 x 1024 x 64
Maximum item sizes (# threads for each dim) 2147483647 x 65535 x 65535
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Clock rate: 2.61 GHz
Run time limit on kernels: No
Integrated: No
Support host page-locked memory mapping: Yes
Compute mode: Default
Concurrent kernel execution: Yes
Device has ECC support enabled: No
[root@node101 gpu]# cd ../../src
[root@node101 src]#make package-status
[root@node101 src]#make yes-gpu
[root@node101 src]#make no-amoeba
[root@node101 src]#make clean-all
[root@node101 src]#make clean-machine
[root@node101 src]#make clean-intel
[root@node101 src]#make -j 32 intel
[root@node101 src]#cp lmp_intel lmp_intel_gpu
7、测试
7.1cpu
source /opt/gpuApp/lammps-gpu-env.sh
mpirun -np 12 /opt/gpuApp/lammps/lmp_intel_cpu -in in.NHO
7.2 4core_1gpu
source /opt/gpuApp/lammps-gpu-env.sh
mpirun -np 4 /opt/gpuApp/lammps/lmp_intel_cuda -sf gpu -pk gpu 1 -in in.NHO
GPU状态:

7.3 16core_1gpu
source /opt/gpuApp/lammps-gpu-env.sh
mpirun -np 16 /opt/gpuApp/lammps/lmp_intel_cuda -sf gpu -pk gpu 1 -in in.NHO
GPU状态:

7.4 16core_4gpu
source /opt/gpuApp/lammps-gpu-env.sh
mpirun -np 16 /opt/gpuApp/lammps/lmp_intel_cuda -sf gpu -pk gpu 4 -in in.NHO
GPU状态:

[强撞1]4070Ti为安培架构,SM为86。双精度性能差,PRECISION为-D_SINGLE_SINGLE



![[<span style='color:red;'>AG</span>32VF<span style='color:red;'>407</span>]国产MCU+FPGA Verilog<span style='color:red;'>编写</span>控制<span style='color:red;'>2</span>路gpio输出不同频率方波实验](https://img-blog.csdnimg.cn/direct/e51913b77d024b32bb72615e864d7ff6.png)
![[Mac软件]Adobe Illustrator <span style='color:red;'>2024</span> 28.3 <span style='color:red;'>intel</span>/M1/M<span style='color:red;'>2</span>/M3矢量图制作软件](https://img-blog.csdnimg.cn/img_convert/9fbdf02f4763f294ebb3e44b2d59ca0a.png)