支持向量机方法
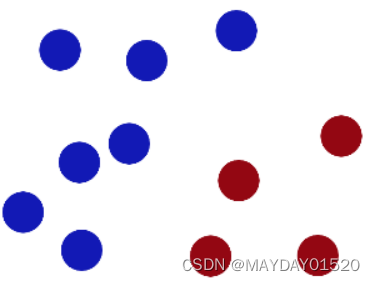
支持向量机(Support Vector Machine,SVM)是一种常用的机器学习算法,主要用于分类和回归问题。SVM的目标是找到一个最优的超平面,将不同类别的样本点分隔开来,使得两个类别的间隔最大化。具体来说,SVM通过寻找支持向量(即距离超平面最近的样本点),确定决策边界,并根据支持向量的位置进行分类。
SVM方法的具体步骤如下:
1. 数据准备:收集并准备用于训练的数据集,确保数据集包含标记好的样本点。
2. 特征选择:根据问题的特点选择合适的特征,并对特征进行预处理(如归一化、标准化等)。
3. 模型训练:利用训练数据集,通过优化算法找到最优的超平面,使得间隔最大化。
4. 模型评估:使用测试数据集评估模型的性能,通常使用准确率、精确率、召回率等指标进行评估。
5. 模型调优:根据评估结果,调整模型参数或选择合适的核函数,以提高模型的性能。
6. 模型应用:使用训练好的模型对新样本进行分类或回归预测。
SVM方法具有以下优点:
- 在高维空间中表现良好,适用于处理复杂的非线性问题。
- 通过间隔最大化准则,具有较好的泛化能力。
- 可以通过选取不同的核函数来适应不同类型的数据。
然而,SVM方法也存在一些限制:
- 对大规模数据集和高维数据处理较为困难。
- 对于数据噪声敏感,需要进行数据预处理和参数调优。
- 训练时间较长,特别是在大规模数据集上。
总而言之,SVM方法是一种强大且广泛应用于机器学习领域的算法,通过最大化间隔来实现分类和回归任务。
decisionProcedure |
字符串,默认:“投票” | 用于分类的决策过程。“投票”或“保证金”。不用于回归。 |
svmType |
字符串,默认:“C_SVC” | 支持向量机类型。“C_SVC”、“NU_SVC”、“ONE_CLASS”、“EPSILON_SVR”或“NU_SVR”之一。 |
kernelType |
字符串,默认:“LINEAR” | 内核类型。LINEAR (u′×v)、POLY ((γ×u′×v + coef₀)ᵈᵉᵍʳᵉᵉ)、RBF (exp(-γ×|uv|²)) 或 SIGMOID (tanh(γ×u′×v +系数₀))。 |
shrinking |
布尔值,默认:true | 是否使用收缩启发式。 |
degree |
整数,默认:null | 多项式的次数。对 POLY 内核有效。 |
gamma |
浮点数,默认:null | 核函数中的伽马值。默认为特征数量的倒数。对于 POLY、RBF 和 SIGMOID 内核有效。 |
coef0 |
浮点数,默认:null |