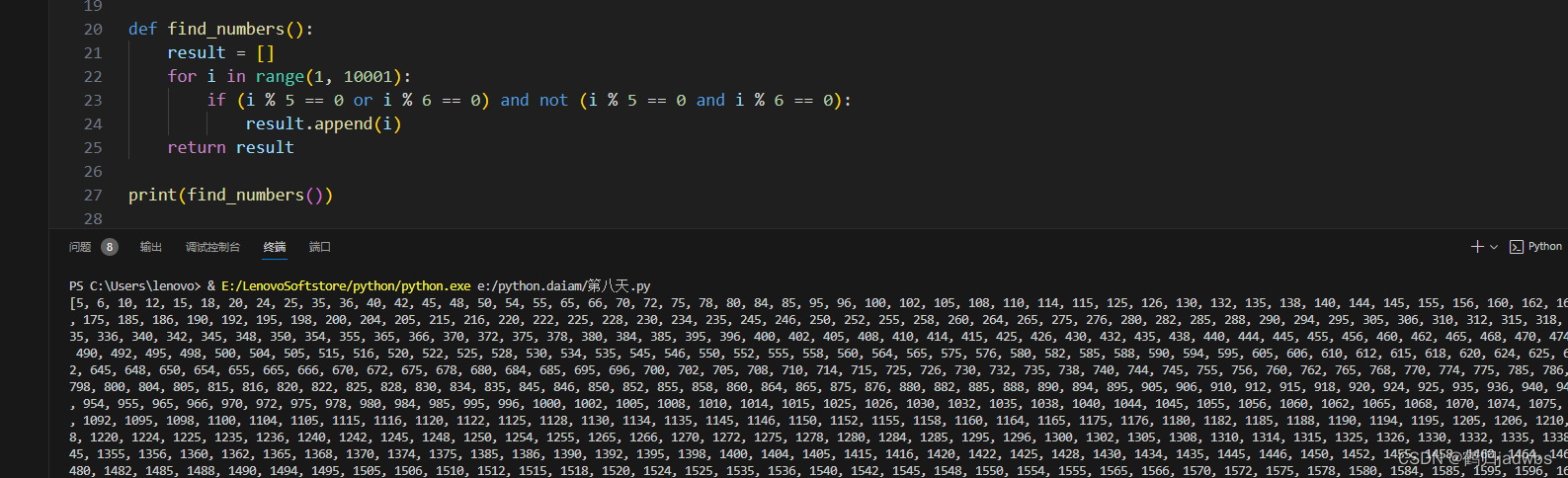
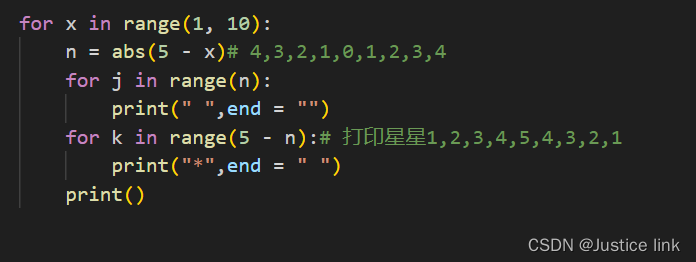
大家好,小编来为大家解答以下问题,python作业题百度网盘,python123作业答案,今天让我们一起来看看吧!
完整项目分享:
链接: https://pan.baidu.com/s/1CTMOgLYteLrWRaRnouB0SQ?pwd=12hf 提取码: 12hf
(如果这个项目帮助到你了,麻烦点个赞,谢谢)
1.实现功能:
1.进行简单的日常生活聊天(首先根据输入寻找对应答案,如果未找到对应答案,就结合从百度百科上爬取下的内容进行回答)
2.关于具体电影和音乐话题的聊天(联系上文语境、实现关键词双重查找)
附加部分:
为机器人增加了语音播报功能
实现了一个简单的GUI,实现了交互功能
机器人对话均为中文对话
2.功能演示
日常聊天部分:
1.进行简单的对话
点击开始按钮,在内部对程序进行初始化

将想要输入的部分输入到发送框中,然后点击发送

2.对于特定的关键词知道进行搜索

当然,如果想要的数据更精确,也可以直接行驶查询功能

特定话题部分:
流程:
首先需要输入“聊电影”
然后利用特定的输入来激活到某个更具体的话题
比如输入的“知道恋恋笔记本这部电影吗?”,“知道陈可辛吗?”,然后就可以就这个部分进行话题的探讨
需要退出具体话题的聊天,可以直接输入exit实现退出,返回到日常生活中的聊天。
首先是激活到对应的具体话题部分
我们先输入“聊电影”
然后再看“激活特定话题用关键词.txt”文件中的内容,选择一个输入
这里输入的是“你知道陈可辛吗?”就正式进入这个话题下的聊天了

找到对应部分后,就可以输入对话了python简单图案代码。这里利用了双层的关键词查找和联系上下问语境

双层关键词
联系上下文语境
前面先聊到“梁家辉”,此时的话题就记住了关键词“梁家辉”,然后再问出生日期,聊天机器人就会在“梁家辉”对应的词条下面寻找。后来又聊到了“陈可辛”,此时的语境就会切换成陈可辛,你再问机器人,机器人就会在结合陈可辛的语境进行回答。
3.实现过程:
实现所用到库
jieba: 用于中文分词。方便将对话输入拆分关键词,便于查找
tkinter:用于实现GUI交互界面
json:用于读取json格式的语料库文件
pyttsx3:用于实现机器人的语音播报
实现思路:
整体思路是结合预料库进行正则匹配。
首先是整个字符串进行匹配,如果找到就可以直接进行输出
然后是关键词逐个匹配,在上一种情况没有匹配的情况下,将输入的话进行关键词的拆分和组合,再进行关键词的匹配。
扩展部分思路
这部分是结合语境以及关键词多重匹配
结合了具体话题的语料库的性质。
这个语料库的关键词分为三层。
第一层适用于我们激活到更加具体的话题,比如说提问“知道陈可辛吗?”,这一整句话就是第一层关键词,保证回答不会跳出这个话题。
第二层关键词就适用于语境了,每次找到新回答后,这个语境关键词都会被更新。
第三层关键词用于查找具体的回答。
结合语境:
每次找到新回答后就会更新语境,下一次再要寻找回答时,会优先匹配之前的语境下的第三层关键词,如果匹配成功了,那就直接输出。如果没有在之前的语境关键词下匹配成功。就跳转到使用关键词的多重匹配。
关键词多重匹配:
利用jieba库对输入的话进行关键词拆分和组合,得到我们实际想知道的关键词的所有可能。
先用所有的关键词可能匹配第二层关键词,如果匹配成功了就再匹配这个语境关键词下的所有第三层关键词,一旦匹配成功就可以输出了。举例:
输入“梁家辉主要成就”
将关键词拆分组合成“梁家辉”“梁家辉成就”,“梁家辉主要”,“梁家梁家辉成就”,“梁家梁家辉主要”,“梁家梁家辉”,“梁家成就”,“梁家主要成就”,“梁家主要”。
利用这些关键词逐个匹配第二层关键词,发现“梁家辉”这个关键词匹配成功了
在“梁家辉”这个语境关键词下,再次利用所有的关键词可能匹配第三层关键词,发现匹配成功了“主要成就”,就将对应结果输出了。
实现所用函数的解释:
query(content):
输入:要查询的词条
输出:查询的结果
功能:爬取百度百科content的搜索内容
StrSplit(String):
输入:要拆分的字符串
输出:所有可能字符子串的数组
功能:将输入的内容进行关键词拆分和组合,返回形成字符串数组。
query_find(String):
输入:要检查的字符串
输出:返回是否符合查找的格式,和查询的结果
功能:检查输入的String是不是符合“知道xx吗”的形式,如果是,就调用query进行查找,并且更改返回值。
MatchSiple(path, String):
输入:语料库的路径,要查询的字符串
输出:返回是否找到结果以及结果
功能:检查String是否在path对应的文件内容中有直接的完全符合的匹配,如果有就修改返回值
MatchHeight(path, String_lt):
输入:语料库的路径,分割好后的字符串数组
输出:是否查询到结果,查询的结果
功能:逐个检查String_lt字符串数组中的字符串是否在path对应文件有完全的匹配,如有有匹配,就对应答案该返回值。
ai_movie_MatSiple(data,String oeder):
与MatchSiple(path,String)类似,只是使用的语料库切换成了具体话题的语料库。
ai_movie_MatchHeight(data, String_lt,order,name):同上。
ai_films_Matchname(data,String):
输入:具体话题的语料库,输入的字符串
输出:查询的结果,是否查询到结果,查询到的第一个关键词
功能:确定好第一个关键词。
films(engine,file,string):
输入:语音播报,打开的语料库文件,要检测的字符串
输出:无返回值,直接将内容输出到GUI上,同时进行语音播报
功能:根据前后全局变量的信息,有针对性调用前面所说的函数,找到对应的结果。
chat_bot(String):
输入:要询问的部分
输出: 无返回值,直接将内容输出到GUI上,同时进行语音播报。
功能:根据几个全局变量的信息,有针对性的调用上述函数,找到最终的结果
send():
这个函数是被按钮“发送”所调用的,会调用chat_bot()函数,寻找返回的字符串,同时将输入的内容有人插入到GUI的文本框中。
begin():
对所有的信息进行初始化,这个函数是由“开始”按钮所调用的
代码中全局变量的解释
global tag1:用于表示当前机器人的状态是不是在“聊电影”这个特殊的话题上
global tag2:用于表示当前机器人的状态是不是在“聊音乐”这个特殊的话题上
global name:用于记录在“聊电影”和“聊音乐”上的第一个关键词
global path:用于记录日常聊天的语料库的路径
global engine:用于记录语音播报
global file1:记录“聊电影”的语料库文件
global file2:记录“聊音乐”的语料库文件
global data:记录打开的具体话题对应文件转化成的dirt
global ord:记录在“聊电影”或者“聊音乐”这两个具体部分中,第一个关键词对应的位置。还是方便后续的查找
##4.实验总结:
本次实验的主题思路是实现关键词的提取和匹配,根据已经有的语料库进行针对性的回答。
在一般的完全匹配上,增加了关键词的拆分重新组合,增加了结合语境,增加了关键词双重匹配,增加了不知道结果时可以从百度百科上爬取答案。同时增加了交互界面和语音播报。
实现了可以简单的一问一答,具体话题下的更具体的回答。
但是由于语料库的欠缺,在实现具体话题下问答时需要用特殊的话来进行激活,这一点是有待改进。同时这次大作业,借鉴了网络上的一些思路,表示感谢。
import tkinter
import tkinter as tk
from tkinter import scrolledtext
import jieba
import urllib.request
import urllib.parse
from lxml import etree
import json
import pyttsx3
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~全局变量~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
global tag1
global tag2
global name
global path
global engine
global file1
global file2
global data
global ord
tag1 = 0
tag2 = 0
name = None
# 标记两个tag,一个tag表示当前的选择是一般性回答还是film,另一个tag是在film中表示是不是第一次使用film的库
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~日常对话部分查找~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def query(content):
# 请求地址
url = 'https://baike.baidu.com/item/' + urllib.parse.quote(content)
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method='GET')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode('utf-8')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到匹配字符串列表
sen_list = html.xpath('//div[contains(@class,"lemma-summary") or contains(@class,"lemmaWgt-lemmaSummary")]//text()')
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip('\n') for item in sen_list]
# 将字符串列表连成字符串并返回
return ''.join(sen_list_after_filter)
def query_find(String):
back = None
find = 0
if '知道' in String: # 符合”知道XX吗“的格式,直接调用query对结果进行爬虫
find = 1
f1 = String.split('知道')
f1 = f1[1].split('吗')
back = query(f1[0])
if len(back) < 2:
back = '这个小蜗也不知道哎'
lt_ms = [back, find]
return lt_ms
def StrSplit(String):
"""
Decompose the string into a list # 将字符串分解为一个列表
:param String: The string to be decomposed # 要分解的字符串
:return: String_lt # 分解后的字符串列表
"""
String_lt = jieba.lcut(String, cut_all=True) # 要引入jieba库
String1 = jieba.lcut(String, cut_all=True)
String2 = jieba.lcut(String, cut_all=True)
String3 = jieba.lcut(String, cut_all=True)
String3.append('')
for Str1 in String1:
String_lt.append(Str1)
String2.remove(Str1)
for Str2 in String2:
String_lt.append(Str2) # 要添加分出来的关键词
try:
String3.remove(Str1)
except:
pass
try:
String3.remove(Str2)
except:
pass
for Str3 in String3:
String_lt.append(Str3)
String_lt.append(Str1 + Str2 + Str3) # 添加组合成的关键词
String_lt = sorted(String_lt, reverse=True)
return String_lt
def MatchSiple(path, String):
"""
Matches the dictionary to a single string # 将字典匹配到单个字符串
:param path: The dictionary to match # 匹配的字典
:param String: The string to match # 要匹配的字符串
:return: lt_ms # 匹配结果与判断(1有/0无)的列表
"""
errow_matchsplit = 0
back = None
f1 = String.split(':')[0]
if f1 == '查询':
errow_matchsplit = 1
back = query(String.split(':')[1])
lt_ms = [back, errow_matchsplit]
return lt_ms
with open(path, 'r', encoding='utf-8') as f: # 注意编码
while errow_matchsplit == 0:
f1 = f.readline().split('\n')[0]
f2 = f.readline().split('\n')[0]
f3 = f.readline()
if String == f1:
back = f2
errow_matchsplit = 1
break
if f1 == '' or f2 == '':
break
lt_ms = [back, errow_matchsplit]
if errow_matchsplit == 0:
lt_ms = query_find(String)
return lt_ms
def MatchHeight(path, String_lt):
"""
Matches the dictionary with a list of strings # 用字符串列表匹配字典
:param path: The dictionary to match # 匹配的字典
:param String_lt: List of strings to match # 要匹配的字符串列表
:return: lt_mh # 匹配结果与判断(1有/0无)的列表
"""
errow_matchheight = 0
back = None
with open(path, 'r', encoding='utf-8') as f: # 注意编码
while errow_matchheight == 0:
f1 = f.readline().split('\n')[0]
f2 = f.readline().split('\n')[0]
f3 = f.readline()
for String in String_lt:
if String == f1:
back = f2
errow_matchheight = 1
break
if f1 == '' or f2 == '':
break
lt_mh = [back, errow_matchheight]
return lt_mh
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def study(path, study_start, study_end):
"""
Open the dictionary and write the match statement and the match result # 打开字典并编写匹配语句和匹配结果
:param path: The dictionary to open # 要查的字典
:param study_start: Dictionary matching statements # 词典匹配语句
:param study_end: The dictionary returns the result # 字典返回结果
:return: None # 无返回
"""
with open(path, 'a', encoding='utf-8') as f: # 注意编码
f.write(study_start+'\n')
f.write(study_end+'\n')
f.write('\n')
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~具体话题查找~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def ai_movie_MatchSiple(data, String, order):
errow_movie_match = 0
back = None
name = None
f1 = String.split(':')[0]
if f1 == '查询':
errow_matchsplit = 1
back = query(String.split(':')[1])
lt_ms = [back, errow_matchsplit,name]
return lt_ms
for i in range(len(data[order]['messages'])):
if data[order]['messages'][i]['message'] == String:
back = data[order]['messages'][i+1]['message']
name = data[order]['messages'][i+1]['attrs'][0]['name']
errow_movie_match = 1
break
lt_ms = [back, errow_movie_match, name]
return lt_ms
def ai_movie_MatchHeight(data, String_lt, order, name):
errow_movie_matchH = 0
back = None
find = 0
for i in range(len(data[order]['messages'])): # 优先根据结果进行检查
if errow_movie_matchH == 1:
break
if len(data[order]['messages'][i]) == 2:
for String in String_lt:
if errow_movie_matchH == 1:
break
# print(String, ' ', data[order]['messages'][i]['attrs'][0]['name'])
for j in range(len(data[order]['messages'][i]['attrs'])): #判断是否普找到
if String == data[order]['messages'][i]['attrs'][j]['name']:
find = 1
break
if find == 1:
for j in range(len(data[order]['messages'][i]['attrs'])):
if errow_movie_matchH == 1:
break
for String in String_lt:
if String == data[order]['messages'][i]['attrs'][j]['attrname']:
back = data[order]['messages'][i]['attrs'][j]['name']+','+data[order]['messages'][i]['attrs'][j]['attrname']+':'+data[order]['messages'][i]['attrs'][j]['attrvalue']
name = data[order]['messages'][i]['attrs'][j]['name']
errow_movie_matchH = 1
break
for i in range(len(data[order]['messages'])): # 优先根据结果进行检查
if errow_movie_matchH == 1:
break
if len(data[order]['messages'][i]) == 2:
for String in String_lt:
#if len(data[order]['messages'][i]['attrs'][0]) == 1:
#说明有不止一个attr
for j in range(len(data[order]['messages'][i]['attrs'])):
if String == data[order]['messages'][i]['attrs'][j]['attrname']:
if name == data[order]['messages'][i]['attrs'][j]['name']: # 首先对name 进行检验,不过这时候的name要换成String,进行三重检测
back = data[order]['messages'][i]['attrs'][j]['name']+','+data[order]['messages'][i]['attrs'][j]['attrname']+':'+data[order]['messages'][i]['attrs'][j]['attrvalue']
errow_movie_matchH = 1
break
for i in range(len(data[order]['messages'])):
if errow_movie_matchH == 1:
break
if len(data[order]['messages'][i]) == 2:
for String in String_lt:
for j in range(len(data[order]['messages'][i]['attrs'])):
if String == data[order]['messages'][i]['attrs'][j]['attrname']:
back = data[order]['messages'][i]['attrs'][j]['name']+','+data[order]['messages'][i]['attrs'][j]['attrname']+':'+data[order]['messages'][i]['attrs'][j]['attrvalue']
name = data[order]['messages'][i]['attrs'][j]['name']
errow_movie_matchH = 1
break
lt_mh = [back, errow_movie_matchH, name]
return lt_mh
def ai_films_Matchname(data,String):
errow_matchsplit = 0
back = 0
name = None
for i in range(149):
if data[i]['messages'][0]['message'] == String:
errow_matchsplit = 1
name = data[i]['messages'][1]['attrs'][0]['name']
back = i
break
lt_ms = [back, errow_matchsplit, name]
return lt_ms
def films(engine, file,String): ##聊电影对应的模块
global tag1
global tag2
global name
global data
global ord
if tag2 == 0: ##说明刚刚进入到这个模块当中
data = json.load(file)
order = ai_films_Matchname(data, String)
name = order[2]
ord = order[0]
t.insert('end', '小蜗:'+data[order[0]]['messages'][1]['message']+'\n')
engine.say(data[order[0]]['messages'][1]['message'])
engine.runAndWait()
tag2 = 1
elif String == 'exit':
tag2 = 0
tag1 = 0
else:
a1 = ai_movie_MatchSiple(data=data, String=String, order=ord)
show = a1[0]
errow_matchsimple = a1[1]
if errow_matchsimple == 0: # 说明没有找到直接相匹配的,关键词进行重组,查找对应的关键词
String_lt = StrSplit(String=String)
a2 = ai_movie_MatchHeight(data=data, String_lt=String_lt, order=ord, name=name)
show = a2[0]
errow_matchhight = a2[1]
if errow_matchhight == 0:
t.insert('end', '小蜗:小蜗不知道这个细节唉😔'+'\n')
engine.say("小蜗不知道这个细节唉")
engine.runAndWait()
else:
name = a2[2]
t.insert('end', '小蜗:'+ show+'\n')
engine.say(show)
engine.runAndWait()
else:
name = a1[2]
t.insert('end', '小蜗:' + show + '\n')
engine.say(show)
engine.runAndWait()
return
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ~~~~~~~~~~~~~~~~~~~~~相当于main函数,总调度~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def chat_bot(String):
global tag1
global tag2
global engine
global file1
global file2
global path
if tag1 == 0: #标志现在是在正常的聊天当中
if String == '聊电影':
tag1 = 1
return
elif String == '聊音乐':
tag2 = 2
return
else:
a1 = MatchSiple(path=path, String=String)
show = a1[0]
errow_matchsimple = a1[1]
if errow_matchsimple == 0:
String_lt = StrSplit(String=String) # 对关键词全部进行重新组合
a2 = MatchHeight(path=path, String_lt=String_lt)
show = a2[0]
errow_matchhight = a2[1]
if errow_matchhight == 0:
t.insert('end', '小蜗: 小蜗不知道怎么回答哎'+'\n')
engine.say("小蜗不知道怎么回答哎")
engine.runAndWait()
else:
t.insert('end', '小蜗:'+show+'\n')
engine.say(show)
engine.runAndWait()
else:
t.insert('end', '小蜗:'+show+'\n')
engine.say(show)
engine.runAndWait()
elif tag1 == 1:
films(engine=engine, file=file1, String=String)
elif tag2 == 2:
films(engine=engine, file=file2, String=String)
return
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ~~~~~~~~~~~~~~~~~~~~~~按钮对应函数~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def send():
val = e.get()
e.delete(0, tkinter.END)
t.insert('end', '主人:' + val + '\n') # 将要输出的内容插入到文本框中
chat_bot(String=val)
t.see(tkinter.END)
def begin(): #默认加载学习模块
global engine
global path
global tag1
tag1 = 0
path = r'ai.txt'
engine = pyttsx3.init()
voices = engine.getProperty('voices') # 音色
engine.setProperty('voice', "com.apple,speech.synthesis.voice.meijia")
rate = engine.getProperty('rate') # 速率
engine.setProperty('rate', 180)
volume = engine.getProperty('volume') # 音量
engine.setProperty('volume', 1.0)
global file1
global file2
file1 = open('file.json', 'r', encoding='utf8')
file2 = open('music.json', 'r', encoding='utf8')
# t.insert('end', '-' * 10 + '程序开始' + '-' * 10 + '\n')
t.insert('end', '小蜗: 程序开始了哦'+'\n')
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ~~~~~~~~~~~~~~~GUI部分~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
window = tk.Tk()
window.title('小蜗机器人')
window.geometry('800x200')
l1 = tk.Label(window, text='聊天', font=('Arial', 12), width=15,
height=1)
l2 = tk.Label(window, text='发送框', font=('Arial', 12), width=15,
height=1)
# 直接传入部分对应输出部分
e = tk.Entry(window, width=100)
t = scrolledtext.ScrolledText(window, height=10, width=100)
be = tk.Button(window,text='开始', font=('Arial', 12), width =10,
height=1, command=begin)
b = tk.Button(window, text='发送', font=('Arial', 12), width=10,
height=1, command=send)
# 界面布置
l1.grid(row=0, column=0)
l2.grid(row=1, column=0)
e.grid(row=1, column=1)
t.grid(row=0, column=1)
be.grid(row=2, column=0)
b.grid(row=2, column=1)
window.mainloop()
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
完整项目分享:
链接: https://pan.baidu.com/s/1CTMOgLYteLrWRaRnouB0SQ?pwd=12hf 提取码: 12hf
(如果这个项目帮助到你了,麻烦点个赞,谢谢)
1.实现功能:
1.进行简单的日常生活聊天(首先根据输入寻找对应答案,如果未找到对应答案,就结合从百度百科上爬取下的内容进行回答)
2.关于具体电影和音乐话题的聊天(联系上文语境、实现关键词双重查找)
附加部分:
为机器人增加了语音播报功能
实现了一个简单的GUI,实现了交互功能
机器人对话均为中文对话
2.功能演示
日常聊天部分:
1.进行简单的对话
点击开始按钮,在内部对程序进行初始化
将想要输入的部分输入到发送框中,然后点击发送
2.对于特定的关键词知道进行搜索
当然,如果想要的数据更精确,也可以直接行驶查询功能
特定话题部分:
流程:
首先需要输入“聊电影”
然后利用特定的输入来激活到某个更具体的话题
比如输入的“知道恋恋笔记本这部电影吗?”,“知道陈可辛吗?”,然后就可以就这个部分进行话题的探讨
需要退出具体话题的聊天,可以直接输入exit实现退出,返回到日常生活中的聊天。
首先是激活到对应的具体话题部分
我们先输入“聊电影”
然后再看“激活特定话题用关键词.txt”文件中的内容,选择一个输入
这里输入的是“你知道陈可辛吗?”就正式进入这个话题下的聊天了
找到对应部分后,就可以输入对话了python简单图案代码。这里利用了双层的关键词查找和联系上下问语境
双层关键词
联系上下文语境
前面先聊到“梁家辉”,此时的话题就记住了关键词“梁家辉”,然后再问出生日期,聊天机器人就会在“梁家辉”对应的词条下面寻找。后来又聊到了“陈可辛”,此时的语境就会切换成陈可辛,你再问机器人,机器人就会在结合陈可辛的语境进行回答。
3.实现过程:
实现所用到库
jieba: 用于中文分词。方便将对话输入拆分关键词,便于查找
tkinter:用于实现GUI交互界面
json:用于读取json格式的语料库文件
pyttsx3:用于实现机器人的语音播报
实现思路:
整体思路是结合预料库进行正则匹配。
首先是整个字符串进行匹配,如果找到就可以直接进行输出
然后是关键词逐个匹配,在上一种情况没有匹配的情况下,将输入的话进行关键词的拆分和组合,再进行关键词的匹配。
扩展部分思路
这部分是结合语境以及关键词多重匹配
结合了具体话题的语料库的性质。
这个语料库的关键词分为三层。
第一层适用于我们激活到更加具体的话题,比如说提问“知道陈可辛吗?”,这一整句话就是第一层关键词,保证回答不会跳出这个话题。
第二层关键词就适用于语境了,每次找到新回答后,这个语境关键词都会被更新。
第三层关键词用于查找具体的回答。
结合语境:
每次找到新回答后就会更新语境,下一次再要寻找回答时,会优先匹配之前的语境下的第三层关键词,如果匹配成功了,那就直接输出。如果没有在之前的语境关键词下匹配成功。就跳转到使用关键词的多重匹配。
关键词多重匹配:
利用jieba库对输入的话进行关键词拆分和组合,得到我们实际想知道的关键词的所有可能。
先用所有的关键词可能匹配第二层关键词,如果匹配成功了就再匹配这个语境关键词下的所有第三层关键词,一旦匹配成功就可以输出了。举例:
输入“梁家辉主要成就”
将关键词拆分组合成“梁家辉”“梁家辉成就”,“梁家辉主要”,“梁家梁家辉成就”,“梁家梁家辉主要”,“梁家梁家辉”,“梁家成就”,“梁家主要成就”,“梁家主要”。
利用这些关键词逐个匹配第二层关键词,发现“梁家辉”这个关键词匹配成功了
在“梁家辉”这个语境关键词下,再次利用所有的关键词可能匹配第三层关键词,发现匹配成功了“主要成就”,就将对应结果输出了。
实现所用函数的解释:
query(content):
输入:要查询的词条
输出:查询的结果
功能:爬取百度百科content的搜索内容
StrSplit(String):
输入:要拆分的字符串
输出:所有可能字符子串的数组
功能:将输入的内容进行关键词拆分和组合,返回形成字符串数组。
query_find(String):
输入:要检查的字符串
输出:返回是否符合查找的格式,和查询的结果
功能:检查输入的String是不是符合“知道xx吗”的形式,如果是,就调用query进行查找,并且更改返回值。
MatchSiple(path, String):
输入:语料库的路径,要查询的字符串
输出:返回是否找到结果以及结果
功能:检查String是否在path对应的文件内容中有直接的完全符合的匹配,如果有就修改返回值
MatchHeight(path, String_lt):
输入:语料库的路径,分割好后的字符串数组
输出:是否查询到结果,查询的结果
功能:逐个检查String_lt字符串数组中的字符串是否在path对应文件有完全的匹配,如有有匹配,就对应答案该返回值。
ai_movie_MatSiple(data,String oeder):
与MatchSiple(path,String)类似,只是使用的语料库切换成了具体话题的语料库。
ai_movie_MatchHeight(data, String_lt,order,name):同上。
ai_films_Matchname(data,String):
输入:具体话题的语料库,输入的字符串
输出:查询的结果,是否查询到结果,查询到的第一个关键词
功能:确定好第一个关键词。
films(engine,file,string):
输入:语音播报,打开的语料库文件,要检测的字符串
输出:无返回值,直接将内容输出到GUI上,同时进行语音播报
功能:根据前后全局变量的信息,有针对性调用前面所说的函数,找到对应的结果。
chat_bot(String):
输入:要询问的部分
输出: 无返回值,直接将内容输出到GUI上,同时进行语音播报。
功能:根据几个全局变量的信息,有针对性的调用上述函数,找到最终的结果
send():
这个函数是被按钮“发送”所调用的,会调用chat_bot()函数,寻找返回的字符串,同时将输入的内容有人插入到GUI的文本框中。
begin():
对所有的信息进行初始化,这个函数是由“开始”按钮所调用的
代码中全局变量的解释
global tag1:用于表示当前机器人的状态是不是在“聊电影”这个特殊的话题上
global tag2:用于表示当前机器人的状态是不是在“聊音乐”这个特殊的话题上
global name:用于记录在“聊电影”和“聊音乐”上的第一个关键词
global path:用于记录日常聊天的语料库的路径
global engine:用于记录语音播报
global file1:记录“聊电影”的语料库文件
global file2:记录“聊音乐”的语料库文件
global data:记录打开的具体话题对应文件转化成的dirt
global ord:记录在“聊电影”或者“聊音乐”这两个具体部分中,第一个关键词对应的位置。还是方便后续的查找
##4.实验总结:
本次实验的主题思路是实现关键词的提取和匹配,根据已经有的语料库进行针对性的回答。
在一般的完全匹配上,增加了关键词的拆分重新组合,增加了结合语境,增加了关键词双重匹配,增加了不知道结果时可以从百度百科上爬取答案。同时增加了交互界面和语音播报。
实现了可以简单的一问一答,具体话题下的更具体的回答。
但是由于语料库的欠缺,在实现具体话题下问答时需要用特殊的话来进行激活,这一点是有待改进。同时这次大作业,借鉴了网络上的一些思路,表示感谢。
import tkinter
import tkinter as tk
from tkinter import scrolledtext
import jieba
import urllib.request
import urllib.parse
from lxml import etree
import json
import pyttsx3
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~全局变量~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
global tag1
global tag2
global name
global path
global engine
global file1
global file2
global data
global ord
tag1 = 0
tag2 = 0
name = None
# 标记两个tag,一个tag表示当前的选择是一般性回答还是film,另一个tag是在film中表示是不是第一次使用film的库
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~日常对话部分查找~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def query(content):
# 请求地址
url = 'https://baike.baidu.com/item/' + urllib.parse.quote(content)
# 请求头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 利用请求地址和请求头部构造请求对象
req = urllib.request.Request(url=url, headers=headers, method='GET')
# 发送请求,获得响应
response = urllib.request.urlopen(req)
# 读取响应,获得文本
text = response.read().decode('utf-8')
# 构造 _Element 对象
html = etree.HTML(text)
# 使用 xpath 匹配数据,得到匹配字符串列表
sen_list = html.xpath('//div[contains(@class,"lemma-summary") or contains(@class,"lemmaWgt-lemmaSummary")]//text()')
# 过滤数据,去掉空白
sen_list_after_filter = [item.strip('\n') for item in sen_list]
# 将字符串列表连成字符串并返回
return ''.join(sen_list_after_filter)
def query_find(String):
back = None
find = 0
if '知道' in String: # 符合”知道XX吗“的格式,直接调用query对结果进行爬虫
find = 1
f1 = String.split('知道')
f1 = f1[1].split('吗')
back = query(f1[0])
if len(back) < 2:
back = '这个小蜗也不知道哎'
lt_ms = [back, find]
return lt_ms
def StrSplit(String):
"""
Decompose the string into a list # 将字符串分解为一个列表
:param String: The string to be decomposed # 要分解的字符串
:return: String_lt # 分解后的字符串列表
"""
String_lt = jieba.lcut(String, cut_all=True) # 要引入jieba库
String1 = jieba.lcut(String, cut_all=True)
String2 = jieba.lcut(String, cut_all=True)
String3 = jieba.lcut(String, cut_all=True)
String3.append('')
for Str1 in String1:
String_lt.append(Str1)
String2.remove(Str1)
for Str2 in String2:
String_lt.append(Str2) # 要添加分出来的关键词
try:
String3.remove(Str1)
except:
pass
try:
String3.remove(Str2)
except:
pass
for Str3 in String3:
String_lt.append(Str3)
String_lt.append(Str1 + Str2 + Str3) # 添加组合成的关键词
String_lt = sorted(String_lt, reverse=True)
return String_lt
def MatchSiple(path, String):
"""
Matches the dictionary to a single string # 将字典匹配到单个字符串
:param path: The dictionary to match # 匹配的字典
:param String: The string to match # 要匹配的字符串
:return: lt_ms # 匹配结果与判断(1有/0无)的列表
"""
errow_matchsplit = 0
back = None
f1 = String.split(':')[0]
if f1 == '查询':
errow_matchsplit = 1
back = query(String.split(':')[1])
lt_ms = [back, errow_matchsplit]
return lt_ms
with open(path, 'r', encoding='utf-8') as f: # 注意编码
while errow_matchsplit == 0:
f1 = f.readline().split('\n')[0]
f2 = f.readline().split('\n')[0]
f3 = f.readline()
if String == f1:
back = f2
errow_matchsplit = 1
break
if f1 == '' or f2 == '':
break
lt_ms = [back, errow_matchsplit]
if errow_matchsplit == 0:
lt_ms = query_find(String)
return lt_ms
def MatchHeight(path, String_lt):
"""
Matches the dictionary with a list of strings # 用字符串列表匹配字典
:param path: The dictionary to match # 匹配的字典
:param String_lt: List of strings to match # 要匹配的字符串列表
:return: lt_mh # 匹配结果与判断(1有/0无)的列表
"""
errow_matchheight = 0
back = None
with open(path, 'r', encoding='utf-8') as f: # 注意编码
while errow_matchheight == 0:
f1 = f.readline().split('\n')[0]
f2 = f.readline().split('\n')[0]
f3 = f.readline()
for String in String_lt:
if String == f1:
back = f2
errow_matchheight = 1
break
if f1 == '' or f2 == '':
break
lt_mh = [back, errow_matchheight]
return lt_mh
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def study(path, study_start, study_end):
"""
Open the dictionary and write the match statement and the match result # 打开字典并编写匹配语句和匹配结果
:param path: The dictionary to open # 要查的字典
:param study_start: Dictionary matching statements # 词典匹配语句
:param study_end: The dictionary returns the result # 字典返回结果
:return: None # 无返回
"""
with open(path, 'a', encoding='utf-8') as f: # 注意编码
f.write(study_start+'\n')
f.write(study_end+'\n')
f.write('\n')
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~具体话题查找~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def ai_movie_MatchSiple(data, String, order):
errow_movie_match = 0
back = None
name = None
f1 = String.split(':')[0]
if f1 == '查询':
errow_matchsplit = 1
back = query(String.split(':')[1])
lt_ms = [back, errow_matchsplit,name]
return lt_ms
for i in range(len(data[order]['messages'])):
if data[order]['messages'][i]['message'] == String:
back = data[order]['messages'][i+1]['message']
name = data[order]['messages'][i+1]['attrs'][0]['name']
errow_movie_match = 1
break
lt_ms = [back, errow_movie_match, name]
return lt_ms
def ai_movie_MatchHeight(data, String_lt, order, name):
errow_movie_matchH = 0
back = None
find = 0
for i in range(len(data[order]['messages'])): # 优先根据结果进行检查
if errow_movie_matchH == 1:
break
if len(data[order]['messages'][i]) == 2:
for String in String_lt:
if errow_movie_matchH == 1:
break
# print(String, ' ', data[order]['messages'][i]['attrs'][0]['name'])
for j in range(len(data[order]['messages'][i]['attrs'])): #判断是否普找到
if String == data[order]['messages'][i]['attrs'][j]['name']:
find = 1
break
if find == 1:
for j in range(len(data[order]['messages'][i]['attrs'])):
if errow_movie_matchH == 1:
break
for String in String_lt:
if String == data[order]['messages'][i]['attrs'][j]['attrname']:
back = data[order]['messages'][i]['attrs'][j]['name']+','+data[order]['messages'][i]['attrs'][j]['attrname']+':'+data[order]['messages'][i]['attrs'][j]['attrvalue']
name = data[order]['messages'][i]['attrs'][j]['name']
errow_movie_matchH = 1
break
for i in range(len(data[order]['messages'])): # 优先根据结果进行检查
if errow_movie_matchH == 1:
break
if len(data[order]['messages'][i]) == 2:
for String in String_lt:
#if len(data[order]['messages'][i]['attrs'][0]) == 1:
#说明有不止一个attr
for j in range(len(data[order]['messages'][i]['attrs'])):
if String == data[order]['messages'][i]['attrs'][j]['attrname']:
if name == data[order]['messages'][i]['attrs'][j]['name']: # 首先对name 进行检验,不过这时候的name要换成String,进行三重检测
back = data[order]['messages'][i]['attrs'][j]['name']+','+data[order]['messages'][i]['attrs'][j]['attrname']+':'+data[order]['messages'][i]['attrs'][j]['attrvalue']
errow_movie_matchH = 1
break
for i in range(len(data[order]['messages'])):
if errow_movie_matchH == 1:
break
if len(data[order]['messages'][i]) == 2:
for String in String_lt:
for j in range(len(data[order]['messages'][i]['attrs'])):
if String == data[order]['messages'][i]['attrs'][j]['attrname']:
back = data[order]['messages'][i]['attrs'][j]['name']+','+data[order]['messages'][i]['attrs'][j]['attrname']+':'+data[order]['messages'][i]['attrs'][j]['attrvalue']
name = data[order]['messages'][i]['attrs'][j]['name']
errow_movie_matchH = 1
break
lt_mh = [back, errow_movie_matchH, name]
return lt_mh
def ai_films_Matchname(data,String):
errow_matchsplit = 0
back = 0
name = None
for i in range(149):
if data[i]['messages'][0]['message'] == String:
errow_matchsplit = 1
name = data[i]['messages'][1]['attrs'][0]['name']
back = i
break
lt_ms = [back, errow_matchsplit, name]
return lt_ms
def films(engine, file,String): ##聊电影对应的模块
global tag1
global tag2
global name
global data
global ord
if tag2 == 0: ##说明刚刚进入到这个模块当中
data = json.load(file)
order = ai_films_Matchname(data, String)
name = order[2]
ord = order[0]
t.insert('end', '小蜗:'+data[order[0]]['messages'][1]['message']+'\n')
engine.say(data[order[0]]['messages'][1]['message'])
engine.runAndWait()
tag2 = 1
elif String == 'exit':
tag2 = 0
tag1 = 0
else:
a1 = ai_movie_MatchSiple(data=data, String=String, order=ord)
show = a1[0]
errow_matchsimple = a1[1]
if errow_matchsimple == 0: # 说明没有找到直接相匹配的,关键词进行重组,查找对应的关键词
String_lt = StrSplit(String=String)
a2 = ai_movie_MatchHeight(data=data, String_lt=String_lt, order=ord, name=name)
show = a2[0]
errow_matchhight = a2[1]
if errow_matchhight == 0:
t.insert('end', '小蜗:小蜗不知道这个细节唉😔'+'\n')
engine.say("小蜗不知道这个细节唉")
engine.runAndWait()
else:
name = a2[2]
t.insert('end', '小蜗:'+ show+'\n')
engine.say(show)
engine.runAndWait()
else:
name = a1[2]
t.insert('end', '小蜗:' + show + '\n')
engine.say(show)
engine.runAndWait()
return
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ~~~~~~~~~~~~~~~~~~~~~相当于main函数,总调度~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def chat_bot(String):
global tag1
global tag2
global engine
global file1
global file2
global path
if tag1 == 0: #标志现在是在正常的聊天当中
if String == '聊电影':
tag1 = 1
return
elif String == '聊音乐':
tag2 = 2
return
else:
a1 = MatchSiple(path=path, String=String)
show = a1[0]
errow_matchsimple = a1[1]
if errow_matchsimple == 0:
String_lt = StrSplit(String=String) # 对关键词全部进行重新组合
a2 = MatchHeight(path=path, String_lt=String_lt)
show = a2[0]
errow_matchhight = a2[1]
if errow_matchhight == 0:
t.insert('end', '小蜗: 小蜗不知道怎么回答哎'+'\n')
engine.say("小蜗不知道怎么回答哎")
engine.runAndWait()
else:
t.insert('end', '小蜗:'+show+'\n')
engine.say(show)
engine.runAndWait()
else:
t.insert('end', '小蜗:'+show+'\n')
engine.say(show)
engine.runAndWait()
elif tag1 == 1:
films(engine=engine, file=file1, String=String)
elif tag2 == 2:
films(engine=engine, file=file2, String=String)
return
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ~~~~~~~~~~~~~~~~~~~~~~按钮对应函数~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
def send():
val = e.get()
e.delete(0, tkinter.END)
t.insert('end', '主人:' + val + '\n') # 将要输出的内容插入到文本框中
chat_bot(String=val)
t.see(tkinter.END)
def begin(): #默认加载学习模块
global engine
global path
global tag1
tag1 = 0
path = r'ai.txt'
engine = pyttsx3.init()
voices = engine.getProperty('voices') # 音色
engine.setProperty('voice', "com.apple,speech.synthesis.voice.meijia")
rate = engine.getProperty('rate') # 速率
engine.setProperty('rate', 180)
volume = engine.getProperty('volume') # 音量
engine.setProperty('volume', 1.0)
global file1
global file2
file1 = open('file.json', 'r', encoding='utf8')
file2 = open('music.json', 'r', encoding='utf8')
# t.insert('end', '-' * 10 + '程序开始' + '-' * 10 + '\n')
t.insert('end', '小蜗: 程序开始了哦'+'\n')
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
# ~~~~~~~~~~~~~~~GUI部分~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
window = tk.Tk()
window.title('小蜗机器人')
window.geometry('800x200')
l1 = tk.Label(window, text='聊天', font=('Arial', 12), width=15,
height=1)
l2 = tk.Label(window, text='发送框', font=('Arial', 12), width=15,
height=1)
# 直接传入部分对应输出部分
e = tk.Entry(window, width=100)
t = scrolledtext.ScrolledText(window, height=10, width=100)
be = tk.Button(window,text='开始', font=('Arial', 12), width =10,
height=1, command=begin)
b = tk.Button(window, text='发送', font=('Arial', 12), width=10,
height=1, command=send)
# 界面布置
l1.grid(row=0, column=0)
l2.grid(row=1, column=0)
e.grid(row=1, column=1)
t.grid(row=0, column=1)
be.grid(row=2, column=0)
b.grid(row=2, column=1)
window.mainloop()
# ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~