一、实验目的:
理解卷积神经网络的基本概念和原理;了解卷积神经网络处理文本数据的基本方法;掌握卷积神经网络处理文本数据的实践方法,并实现新闻文本的分类任务。
- 实验要求:
使用Keras框架定义并训练卷积神经网络模型,并进行新闻文本的分类。
import csv
import tensorflow as tf # 使用 tensorflow 的 Keras
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from nltk.corpus import stopwords
import nltk
# 其他代码保持不变
# 添加 NLTK 数据路径
nltk.data.path.append(r'D:\pythonProje_NLP\第7章_data\nltk_data')
# 下载 NLTK 停用词
nltk.download('stopwords')
STOPWORDS = set(stopwords.words('english'))
print(STOPWORDS)
# 读取数据
articles = []
labels = []
with open("bbc-text.csv", 'r') as csvfile:
reader = csv.reader(csvfile, delimiter=',')
next(reader) # 跳过标题行
for row in reader:
labels.append(row[0])
article = row[1]
# 去除停用词
for word in STOPWORDS:
token = ' ' + word + ' '
article = article.replace(token, ' ')
article = article.replace(' ', ' ')
articles.append(article)
print(len(articles), len(labels))
print("新闻内容: ", articles[1])
print("分类标签: ", labels[1])
# 创建词典
vocab_size = 5000
oov_tok = '<OOV>'
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(articles)
word_index = tokenizer.word_index
print(dict(list(word_index.items())[0:10]))
# 将文本转换为数字序列
text_sequences = tokenizer.texts_to_sequences(articles)
print(text_sequences[0])
# 填充和截断
max_length = 200
padding_type = 'post'
trunc_type = 'post'
padded_sequences = pad_sequences(text_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
print(len(text_sequences[0]))
print(len(padded_sequences[0]))
print(len(text_sequences[1]))
print(len(padded_sequences[1]))
print(padded_sequences[1])
# 划分数据集
training_portion = 0.8
train_size = int(len(articles) * training_portion)
train_sequences = padded_sequences[0: train_size]
train_labels = labels[0: train_size]
validation_sequences = padded_sequences[train_size:]
validation_labels = labels[train_size:]
print(len(train_sequences))
print(len(train_labels))
print(len(validation_sequences))
print(len(validation_labels))
# 将标签转换为数字
label_tokenizer = Tokenizer()
label_tokenizer.fit_on_texts(labels)
word_index = label_tokenizer.word_index
print(np.unique(labels))
print(dict(list(word_index.items())))
training_label_seq = np.array(label_tokenizer.texts_to_sequences(train_labels))
validation_label_seq = np.array(label_tokenizer.texts_to_sequences(validation_labels))
print(train_labels[0], training_label_seq[0])
print(train_labels[1], training_label_seq[1])
print(training_label_seq.shape)
print(validation_labels[0], validation_label_seq[0])
print(validation_labels[1], validation_label_seq[1])
print(validation_label_seq.shape)
# 定义模型
embedding_dim = 64
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Conv1D(256, 3, padding='same', strides=1, activation='relu'),
tf.keras.layers.GlobalMaxPooling1D(),
tf.keras.layers.Dense(embedding_dim, activation='relu'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(6, activation='softmax')
])
model.summary()
# 训练模型
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
num_epochs = 10
history = model.fit(train_sequences, training_label_seq, epochs=num_epochs,
validation_data=(validation_sequences, validation_label_seq), verbose=2)
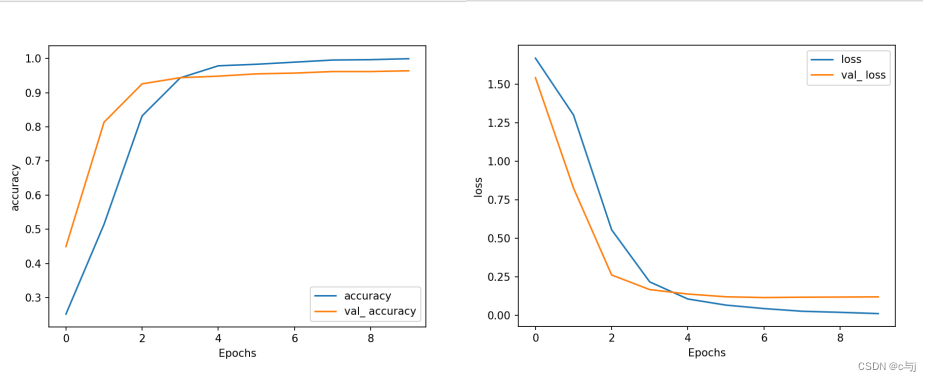
# 训练过程可视化
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_' + string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_ ' + string])
plt.show()
# 调用函数
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")
NLTK中停用词stopwords库需要自己去官网下载安装,NLTK库只是一个外壳,pycharm并没有下载相关的依赖。
可视化结果: