大家好,我是水滴~~
本篇文章主要介绍 Python 的 urllib 模块,主要内容有:urllib库的基本使用、使用 urllib.request 模块获取网页内容及下载文件、使用 urllib.parse 解析 URL 地址、使用 urllib.error 模块处理请求异常、使用 urllib.robotparser 模块解析 robots.txt 文件等。
文章中包含大量的示例代码,希望能够帮助新手同学快速入门。
文章目录
Python中的urllib库是一个强大的工具,它提供了处理URL、发送网络请求和获取数据的功能。本教程将详细介绍urllib库的使用方法,并提供一些代码示例来帮助您快速上手。
1. urllib库的基本功能
urllib库提供了以下功能:
URL解析:可以解析URL,提取出其中的协议、主机、路径等信息。
网络请求:可以发送HTTP请求(GET、POST等),获取服务器的响应数据。
数据获取:可以根据URL获取网页内容、下载文件等。
2. urllib库的模块
urllib库包含以下几个模块:
urllib.request:用于发送HTTP请求和获取响应数据。
urllib.parse:用于解析和处理URL。
urllib.error:用于处理请求过程中的错误。
urllib.robotparser:用于解析并处理robots.txt文件。
本教程将重点介绍urllib.request模块的使用方法。
3. urllib.request模块
3.1 urlopen函数
urlopen 是 urllib.request 模块中的一个函数,用于打开一个 URL 并返回一个http.client.HTTPResponse对象。
这个函数的语法如下:
def urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
*, cafile=None, capath=None, cadefault=False, context=None):
参数说明:
url:需要打开的 URL字符串或Request对象。data:可选参数,用于发送 POST 请求时的数据。timeout:可选参数,设置超时时间,单位为秒。cafile:可选参数,指定 CA 证书的路径。capath:可选参数,指定 CA 证书的目录路径。cadefault:可选参数,指定是否使用默认的 CA 证书。context:可选参数,指定 SSL 上下文。
该函数返回一个http.client.HTTPResponse对象,可以通过该对象的方法和属性来获取响应的内容、状态码等信息。
代码示例:
import urllib.request
# 发送 GET 请求,并将响应结果赋值给 response 变量
response = urllib.request.urlopen('http://www.baidu.com')
# 获取响应的类型
print(type(response))
输出结果:
<class 'http.client.HTTPResponse'>
3.2 HTTPResponse对象
3.2.1 获取状态行
我们可以获取HTTPResponse对象的响应码,协议版本号等信息。
代码示例:
import urllib.request
# 发送 GET 请求,并将响应结果赋值给 response 变量
response = urllib.request.urlopen('http://www.baidu.com')
# 获取响应的 Status-Code
print(response.status)
# 获取响应的 Status-Code
print(response.getcode())
# 获取响应的 HTTP-Version,11表示为HTTP/1.1
print(response.version)
输出结果:
200
11
text/html; charset=utf-8
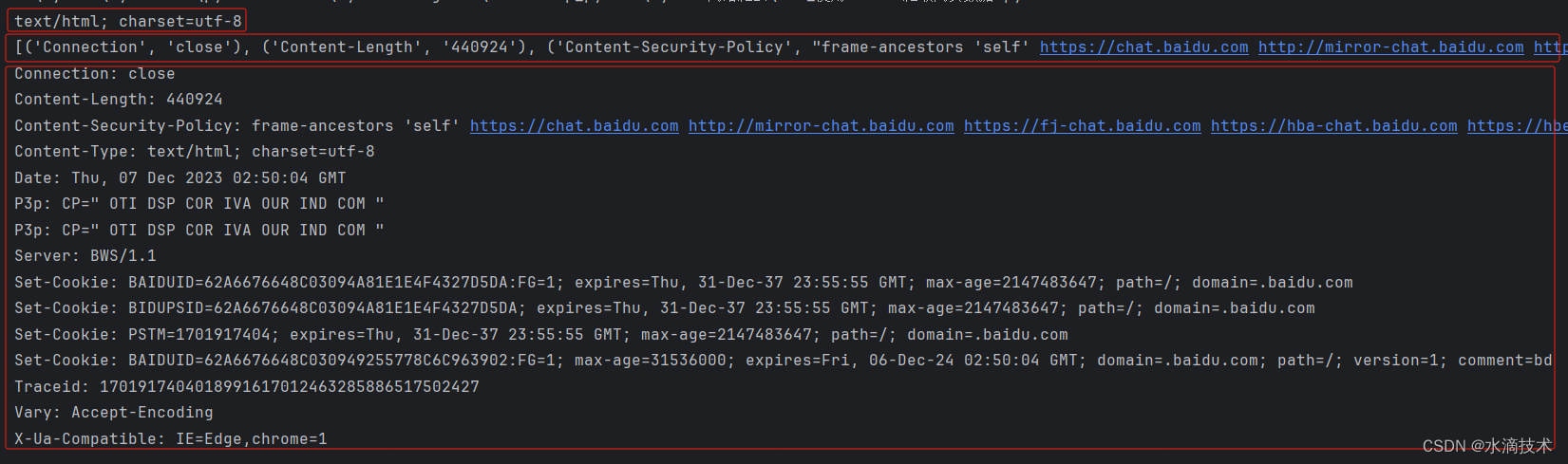
3.2.2 获取响应头
获取响应头有三种方法,分别用于获取指定的响应头,获取响应头列表,获取格式化后的响应头信息。
代码示例:
import urllib.request
# 发送 GET 请求,并将响应结果赋值给 response 变量
response = urllib.request.urlopen('http://www.baidu.com')
# 获取指定的响应头
print(response.getheader('Content-Type'))
# 获取所有响应头,结果为列表
print(response.getheaders())
# 获取格式化后的响应头
print(response.info())
输出结果:
3.2.3 获取响应体
HTTPResponse 对象的 read() 和 readline() 方法都用于从响应中读取内容,但它们之间有一些区别。
read(): 这个方法用于一次性读取整个响应的内容。它会返回一个字节串(bytes),包含了整个响应的内容。你可以使用 read(size) 指定要读取的字节数,或者省略 size 参数以一次性读取整个内容。如果没有更多的内容可读,read() 方法将返回一个空的字节串。
示例用法:
import urllib.request
# 发送 GET 请求,并将响应结果赋值给 response 变量
response = urllib.request.urlopen('http://www.baidu.com')
# 读取响应体内容,一次性读取所有内容
print(response.read())
输出内容(部分截图):

readline(): 这个方法用于逐行读取响应的内容。它会返回一个字节串(bytes),包含了当前行的内容,不包括行尾符。每次调用 readline() 方法都会读取下一行的内容,直到到达响应的末尾。如果没有更多的内容可读,readline() 方法将返回一个空的字节串。
示例用法:
import urllib.request
# 发送 GET 请求,并将响应结果赋值给 response 变量
response = urllib.request.urlopen('http://www.baidu.com')
# 读取响应体内容,一行一行的读取
line = response.readline()
while line:
print(line)
line = response.readline()
输出结果(部分截图):

无论是read() 还是 readline() 方法,它们返回的结果都是一个字节串,需要转码后才是我们想要的内容,转码时也要指定编码格式,编码格式可以通过查看目标网页的源码获取,即:的 content属性
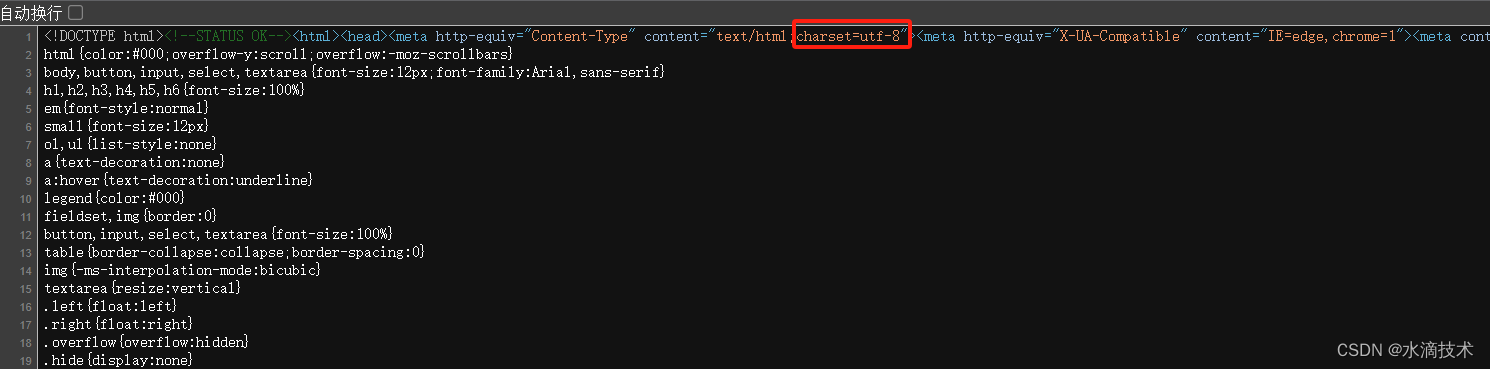
示例代码:
import urllib.request
# 发送 GET 请求,并将响应结果赋值给 response 变量
response = urllib.request.urlopen('http://www.baidu.com')
# 读取响应内容,并赋值给 content 变量
content = response.read()
# 解码
print(content.decode('utf-8'))
输出结果(部分截图):

3.3 urlretrieve函数
urlretrieve 是 urllib.request 模块的一个函数,用于从一个 URL 下载文件并保存到本地。
以下是 urlretrieve 函数的语法:
def urlretrieve(url, filename=None, reporthook=None, data=None)
url: 要下载文件的 URL。filename(可选): 要保存到的本地文件路径。如果未提供该参数,urlretrieve函数将根据响应中的信息自动生成一个临时文件名并返回给你。reporthook(可选): 一个回调函数,用于在下载过程中提供进度报告。可以用于显示下载进度或执行其他操作。data(可选): 如果要向服务器发送一个请求体(request body),可以将请求体的数据作为参数传递给data参数。默认为None。
示例用法:
import urllib.request
url = "https://www.baidu.com/robots.txt"
filename = "local_file.txt"
urllib.request.urlretrieve(url, filename)
在这个示例中,我们使用 urlretrieve 函数从 url 指定的地址下载文件,并将其保存为 filename 指定的本地文件。
urlretrieve 函数会返回一个元组 (filename, headers),其中 filename 是保存到本地的文件名,headers 是响应的头信息。
3.4 Request对象
Request 是 urllib.request 模块的一个类,用于创建一个HTTP 请求对象。
Request 类允许你指定各种请求的属性,如 URL、请求方法、请求头、请求体等。这样,你可以更加灵活地构建和发送 HTTP 请求。
以下是 Request 类的构造函数的语法:
urllib.request.Request(url, data=None, headers={
}, origin_req_host=None, unverifiable=False, method=None)
url: 请求的 URL。data(可选): 要发送的请求体数据,默认为None。headers(可选): 请求头信息,一个字典形式的键值对,默认为空字典。origin_req_host(可选): 请求的原始主机名,默认为None。unverifiable(可选): 标志请求是否是不可验证的,默认为False。method(可选): 请求方法,如 GET、POST、PUT 等,默认为None。
示例用法:
import urllib.request
url = "http://www.example.com/endpoint"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
}
req = urllib.request.Request(url, headers=headers, method="GET")
response = urllib.request.urlopen(req)
content = response.read()
print(content)
在这个示例中,我们使用 Request 类创建了一个请求对象 req,指定了 URL、请求头和请求方法。然后,我们使用 urlopen() 函数发送这个请求,并获取响应。最后,我们读取响应的内容并打印出来。
urllib.request.Request 类提供了更灵活的方式来定制和发送 HTTP 请求,特别适用于需要自定义请求头、请求方法或请求体的情况。
4. urllib.parse模块
urllib.parse模块提供了解析和处理URL的功能。下面是一个示例,演示如何解析URL并获取其中的各个部分:
import urllib.parse
url = 'http://www.example.com:80/search?q=python&page=1'
# 解析URL
parsed_url = urllib.parse.urlparse(url)
# 获取URL的各个部分
print('协议:', parsed_url.scheme)
print('域名:', parsed_url.netloc)
print('路径:', parsed_url.path)
print('参数:', parsed_url.query)
print('主机:', parsed_url.hostname)
print('端口:', parsed_url.port)
输出结果:
协议: http
域名: www.example.com:80
路径: /search
参数: q=python&page=1
主机: www.example.com
端口: 80
上述代码使用urlparse函数解析了一个URL,并将其各个部分存储在parsed_url变量中。然后,可以通过访问相应的属性来获取URL的协议、主机、路径和查询参数等信息。
5. urllib.error模块
urllib库的urllib.error模块提供了处理请求过程中的错误的功能。下面是一个示例,演示如何处理网络请求的异常情况:
import urllib.request
import urllib.error
try:
response = urllib.request.urlopen('http://www.1.com')
data = response.read()
print(data.decode('utf-8'))
except urllib.error.URLError as e:
print('请求出错:', e.reason)
输出结果:
请求出错: Bad Gateway
在上述代码中,我们使用try-except语句块来捕获可能发生的异常。如果请求出错,会抛出URLError异常,我们可以通过访问其reason属性来获取错误原因并进行处理。
6. urllib.urlretrieve模块
urllib.robotparser 模块用于解析 robots.txt 文件。robots.txt 是一个遵循 Robot Exclusion Protocol(机器人排除协议)的文件,用于指示网络爬虫如何访问一个网站的内容。
urllib.robotparser 模块提供了 RobotFileParser 类,用于解析和处理 robots.txt 文件。这个类可以帮助你确定一个特定的用户代理(爬虫)是否被允许访问某个 URL。
以下是 RobotFileParser 类的一些常用方法:
set_url(url): 设置要解析的 robots.txt 的 URL。read(): 从指定的 URL 下载并解析 robots.txt 文件。parse(lines): 解析给定的文本行列表,用于处理自定义的 robots.txt 内容。can_fetch(useragent, url): 检查给定的用户代理(爬虫)是否被允许访问指定的 URL。mtime(): 返回上次读取或下载 robots.txt 文件的时间戳。modified(): 检查 robots.txt 文件是否已更改。
示例用法:
import urllib.robotparser
# 读取百度的robots.txt文件
rp = urllib.robotparser.RobotFileParser()
rp.set_url("http://www.baidu.com/robots.txt")
rp.read()
# 判断该代理是否允许抓取指定的URL
useragent = "Baiduspider"
urls = [
'http://www.baidu.com/link/page.html',
'http://www.baidu.com/aa/page.html'
]
for url in urls:
if rp.can_fetch(useragent, url):
print("允许抓取该URL:", url)
else:
print("不允许抓取该URL:", url)
输出结果:
不允许抓取该URL: http://www.baidu.com/link/page.html
允许抓取该URL: http://www.baidu.com/aa/page.html
在这个示例中,我们创建了一个 RobotFileParser 对象,并设置要解析的 robots.txt 的 URL。然后,我们使用 read() 方法下载并解析了 robots.txt 文件。最后,我们使用 can_fetch() 方法检查指定的用户代理是否被允许访问指定的 URL。
urllib.robotparser 模块使得解析和处理 robots.txt 文件变得简单,可以帮助你编写符合规范的网络爬虫代码。请注意,这个模块只能解析和处理 robots.txt 文件,不执行任何实际的网络请求。
7. 总结
urllib库是Python中一个功能强大的网络请求和数据获取工具。本教程介绍了urllib库的基本功能和几个模块的使用方法,包括发送HTTP请求、解析URL、处理请求错误以及文件下载等。通过掌握urllib库的使用,您可以轻松地在Python中进行网络请求和数据获取的相关操作。希望本教程能够帮助您更好地理解和应用urllib库,从而提升您的编程效率和网络数据处理能力。























![[论文阅读]Sparse Fuse Dense](https://img-blog.csdnimg.cn/direct/e51d986e00714f84835419cebd007564.png)

![[⑧ADRV902x]: Digital Pre-Distortion (DPD)学习笔记](https://img-blog.csdnimg.cn/direct/7a538af28fca44b8a4045e0e7839c26d.png)