一、关于中间件
之前文章说过,scrapy有两种中间件:爬虫中间件和下载中间件,他们的作用时间和位置都不一样,具体区别如下:
- 爬虫中间件(Spider Middleware)
作用: 爬虫中间件主要负责处理从引擎发送到爬虫的请求和从爬虫返回到引擎的响应。这些中间件在请求发送给爬虫之前或响应返回给引擎之前可以对它们进行处理。
- 下载中间件(Downloader Middleware)
作用: 下载中间件主要负责处理引擎发送到下载器的请求和从下载器返回到引擎的响应。这些中间件在请求发送给下载器之前或响应返回给引擎之前可以对它们进行处理。
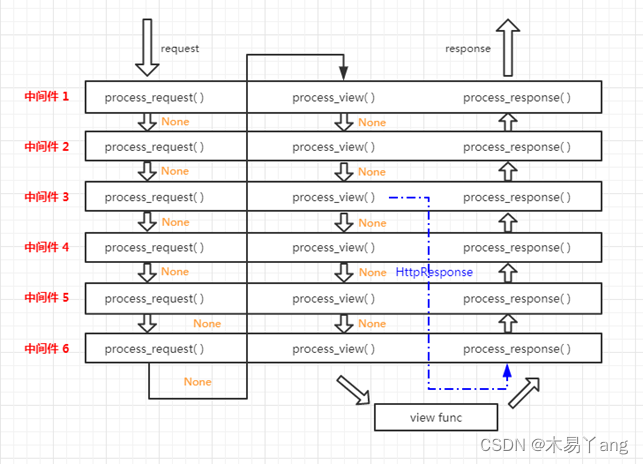
中间件作用优先级
只需要记住,级别越小的越接近scrapy的引擎,结合scrapy的数据流,就能记住每个中间件的作用时机。
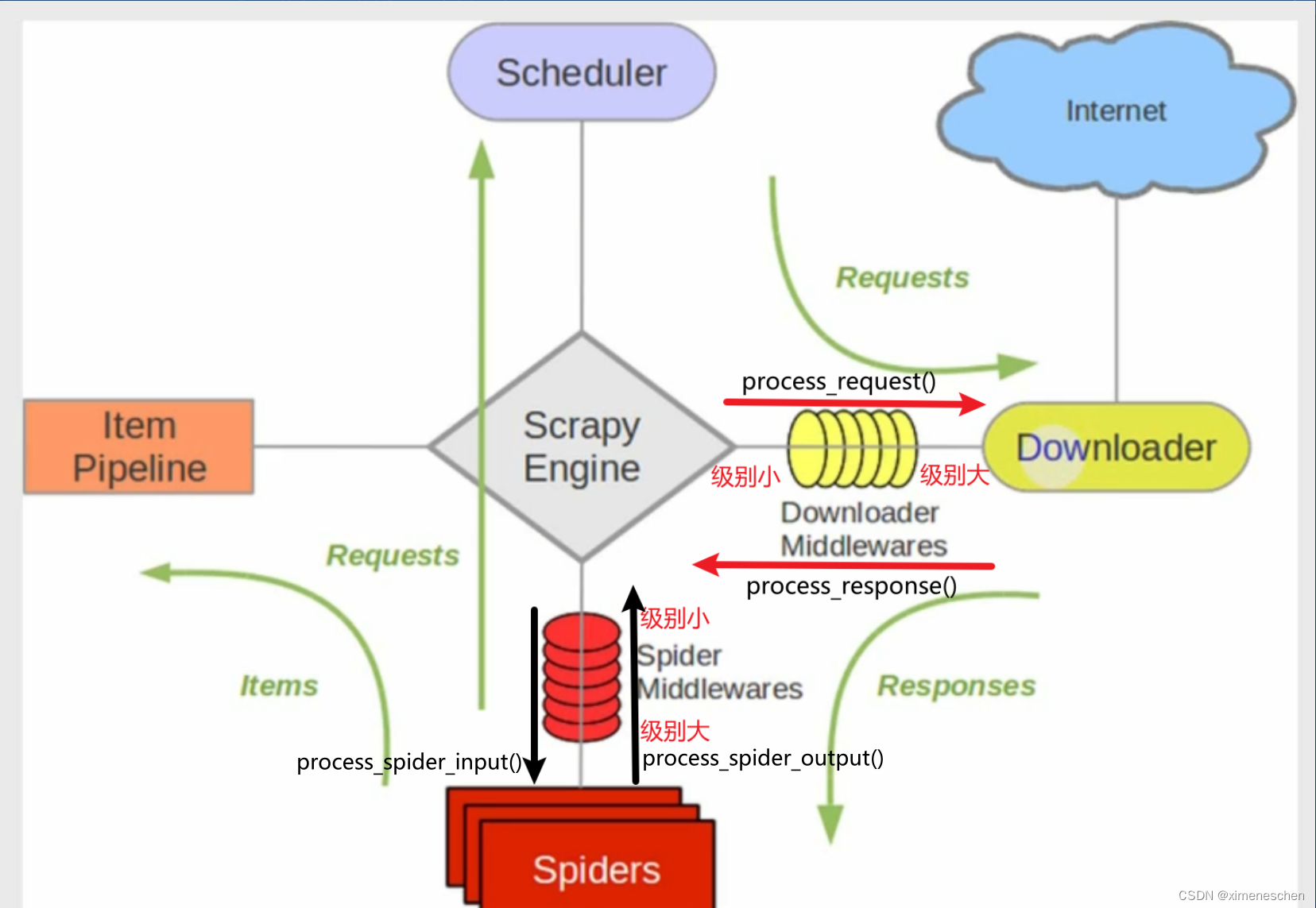
结合图可知:
- 在下载中间件中:
- 对于process_request()来说,优先级数字越小越先被调用;
- 对于process_response()来说,优先级数字越大越先被调用
- 在爬虫中间件中:
- 对于process_spider_input()来说,优先级数字越小越先被调用;
- 对于process_spider_output()来说,优先级数字越大越先被调用
那么哪来的这些方法?
二、定义中间件的通用模板
- 先看一个内置的中间件:UserAgentMiddleware
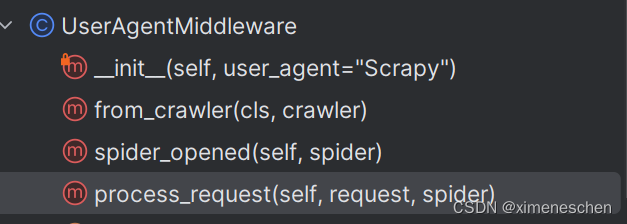
- init: 在这里进行中间件的初始化,可以使用 settings 对象获取配置信息
- from_crawler:在这里通过 crawler 对象创建中间件的实例,可以获取全局配置信息
- spider_opened(可选): 在这里执行爬虫启动时的初始化操作,例如打开文件、连接数据库等
- process_request(可选): 在这里对请求进行预处理,例如修改请求头、添加代理等
- 那么同理process_response(可选)
- 爬虫中间件模板
class MySpiderMiddleware(object):
def __init__(self, settings):
# 在这里进行中间件的初始化,可以使用 settings 对象获取配置信息
pass
@classmethod
def from_crawler(cls, crawler):
# 在这里通过 crawler 对象创建中间件的实例,可以获取全局配置信息
settings = crawler.settings
return cls(settings)
def process_spider_input(self, response, spider):
# 在这里处理从下载器传递给爬虫的响应对象
return response
def process_spider_output(self, response, result, spider):
# 在这里处理爬虫生成的结果,例如对结果进行过滤或修改
return result
def process_spider_exception(self, response, exception, spider):
# 在这里处理爬虫产生的异常
pass
- 下载中间件模板
class MyDownloaderMiddleware(object):
def __init__(self, settings):
# 在这里进行中间件的初始化,可以使用 settings 对象获取配置信息
pass
@classmethod
def from_crawler(cls, crawler):
# 在这里通过 crawler 对象创建中间件的实例,可以获取全局配置信息
settings = crawler.settings
return cls(settings)
def process_request(self, request, spider):
# 在这里对请求进行预处理,例如修改请求头、添加代理等
return None # 返回 None 表示继续处理请求,或者返回一个新的请求对象
def process_response(self, request, response, spider):
# 在这里对响应进行处理,例如修改响应内容、判断是否重新发送请求等
return response # 返回响应对象,或者返回一个新的响应对象
def process_exception(self, request, exception, spider):
# 在这里处理请求异常,例如记录日志、发送通知等
pass
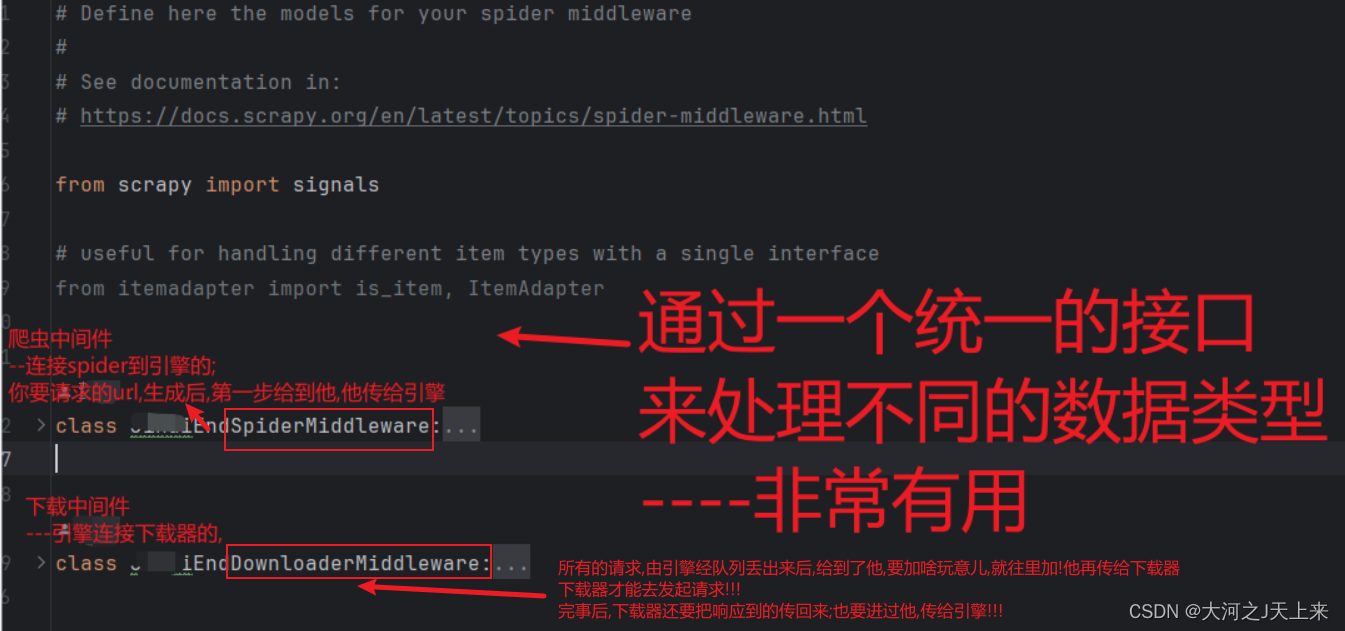
三、位置

我们自定义的中间件在middlewares.py中编写类就可以



























![[Android]AlertDialog对话框](https://img-blog.csdnimg.cn/069916bda50044698456f1b622fd35b6.png)