祝福这个快要漫出来的杯子吧,让杯里的水变得金光灿烂地流出,把反映你的喜悦的光送往各处!
🎵 罗老师《查拉图斯特拉的前言_漾水》
在网络爬虫开发中,合理使用User-Agent(UA)是绕过服务器反爬策略的常见做法之一。Scrapy框架通过中间件(Middleware)机制提供了灵活的方式来修改请求和响应,包括自定义UA。本文将介绍如何在Scrapy项目中配置随机UA中间件,以及如何与Scrapy默认的UA中间件配合使用。
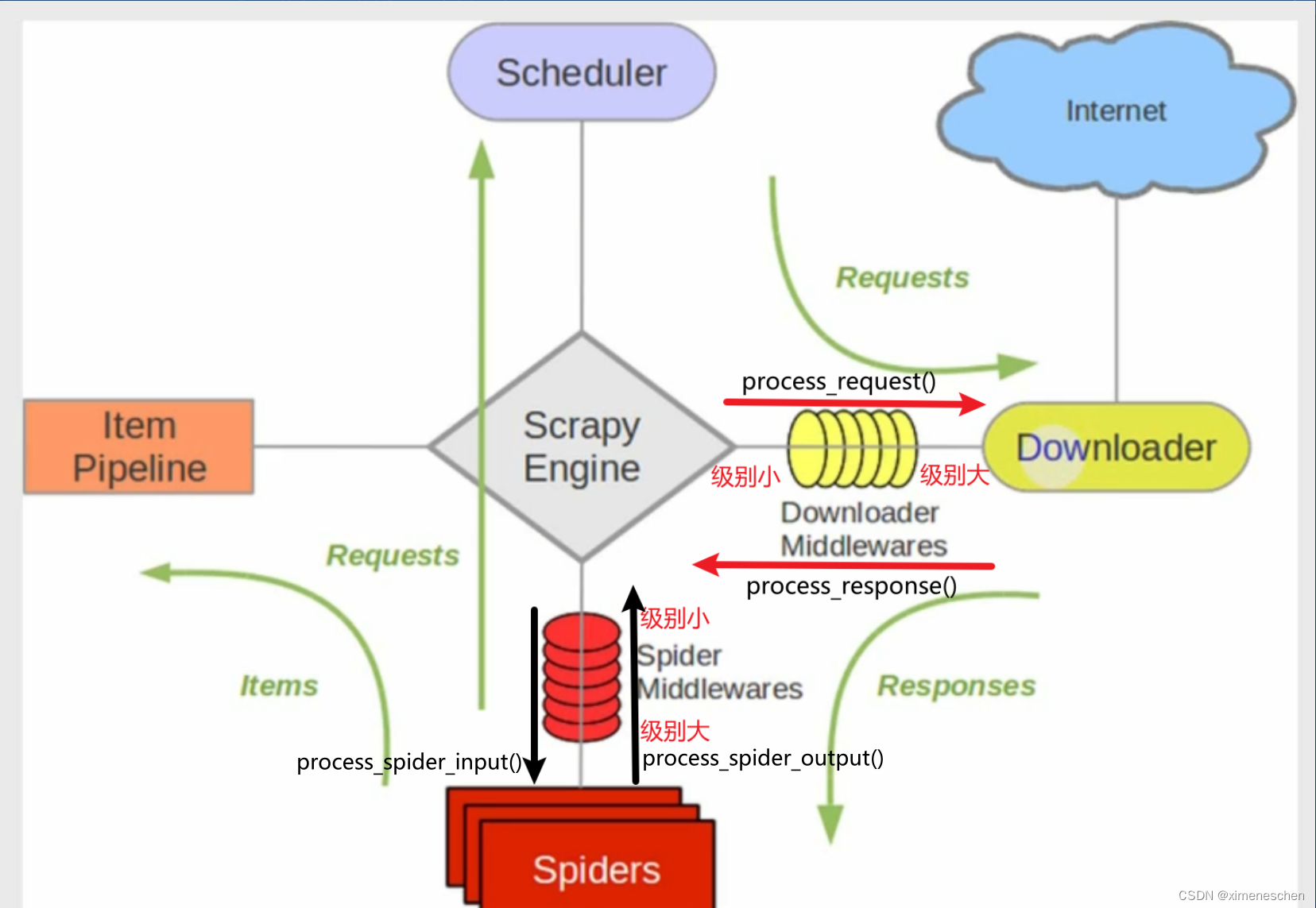
Scrapy的中间件机制
Scrapy使用中间件来处理请求和响应,这些中间件可以修改、丢弃、延迟或者重新生成请求和响应。在Scrapy设置(settings.py)中,DOWNLOADER_MIDDLEWARES字典定义了中间件及其优先级。优先级决定了中间件的执行顺序,数值越小的中间件越早执行。
默认User-Agent中间件
Scrapy提供了默认的UserAgentMiddleware,用于设置请求的UA。如果没有特别指定,Scrapy会使用预定义的UA字符串,或者可以在settings.py中通过USER_AGENT设置全局UA。
# settings.py
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
自定义随机UA中间件
为了更进一步模拟真实用户的行为,我们可以创建一个中间件来为每个请求随机设置不同的UA。以下是实现随机UA中间件的步骤:
-
- 安装fake_useragent
首先,安装fake_useragent库,它提供了一个大量常见浏览器UA的列表,支持随机获取UA。
pip install fake_useragent - 安装fake_useragent
-
- 创建随机UA中间件
在Scrapy项目的middlewares.py文件中,创建一个新的中间件类RandomUserAgentMiddleware。
from fake_useragent import UserAgent from scrapy import signals class RandomUserAgentMiddleware(object): def __init__(self): self.ua = UserAgent(use_cache_server=False) self.ua.update() def process_request(self, request, spider): # 为每个请求随机设置一个UA request.headers.setdefault('User-Agent', self.ua.random) - 创建随机UA中间件
-
- 配置中间件
在settings.py中,禁用默认的UserAgentMiddleware,并添加RandomUserAgentMiddleware到DOWNLOADER_MIDDLEWARES。
DOWNLOADER_MIDDLEWARES = { 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, 'myproject.middlewares.RandomUserAgentMiddleware': 400, } - 配置中间件
确保RandomUserAgentMiddleware的优先级设置允许它在发送请求前执行,例如设置为400。同时,通过将UserAgentMiddleware设置为None禁用它,确保不会与自定义中间件冲突。
总结
通过自定义中间件,Scrapy提供了极大的灵活性来处理请求和响应。使用fake_useragent库和自定义中间件,我们能够轻松实现为每个请求随机设置UA的功能,这有助于提高爬虫的隐蔽性和有效性。此外,正确配置中间件的优先级确保了自定义逻辑的正确执行,为Scrapy爬虫的开发提供了强大的支持。



































![[附带黑子定制款鸽鸽版素材包]更改文件夹图标,更改系统音效,更改鼠标指针及样式。](https://img-blog.csdnimg.cn/direct/2274fa92b22643dd98547a81ba10a44d.png)


