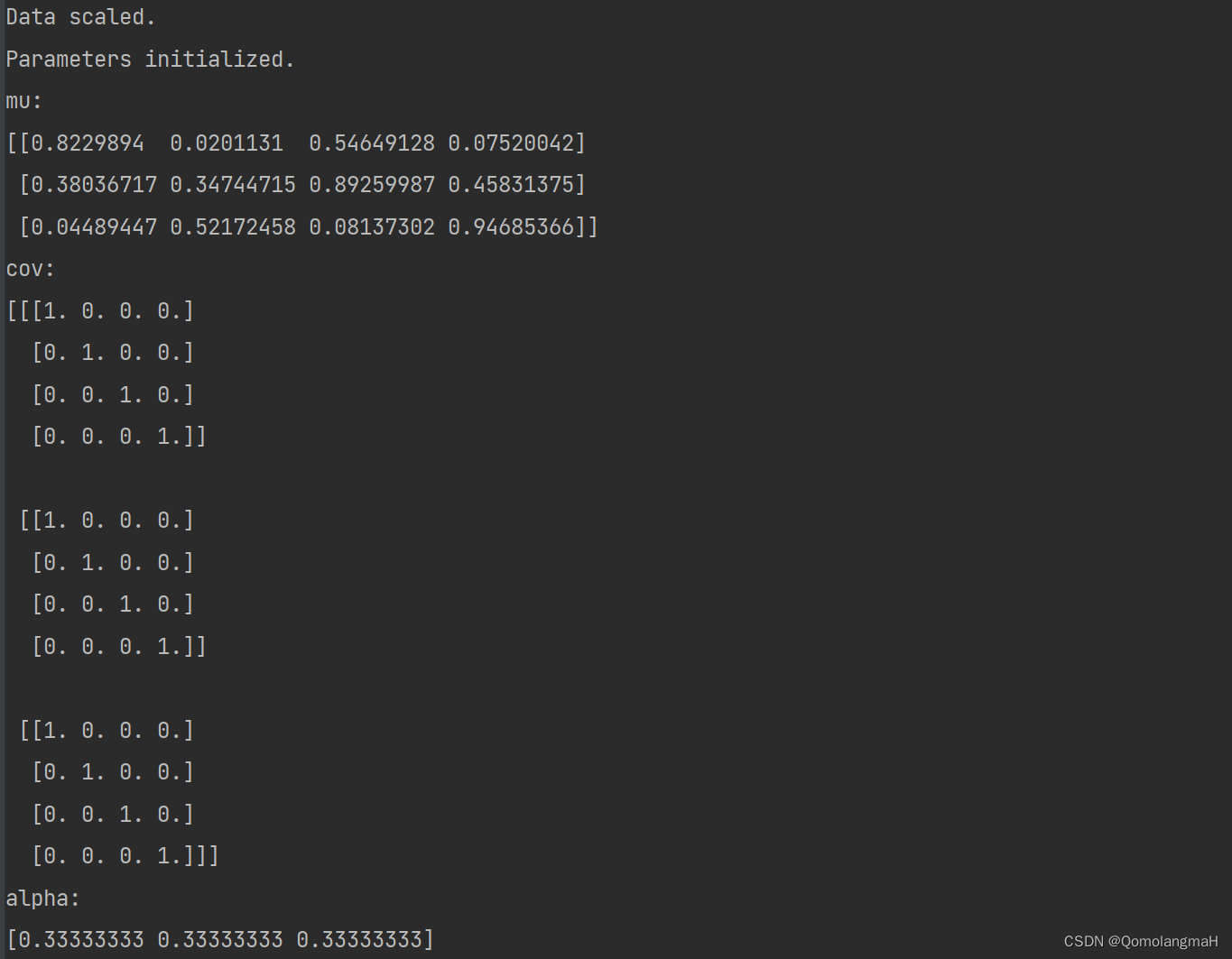
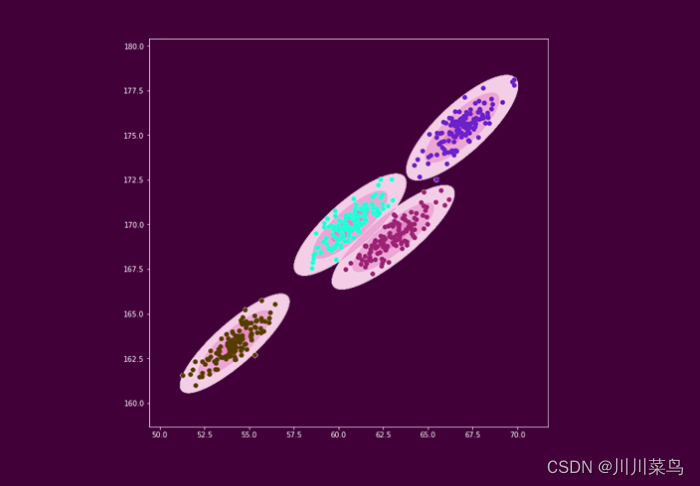
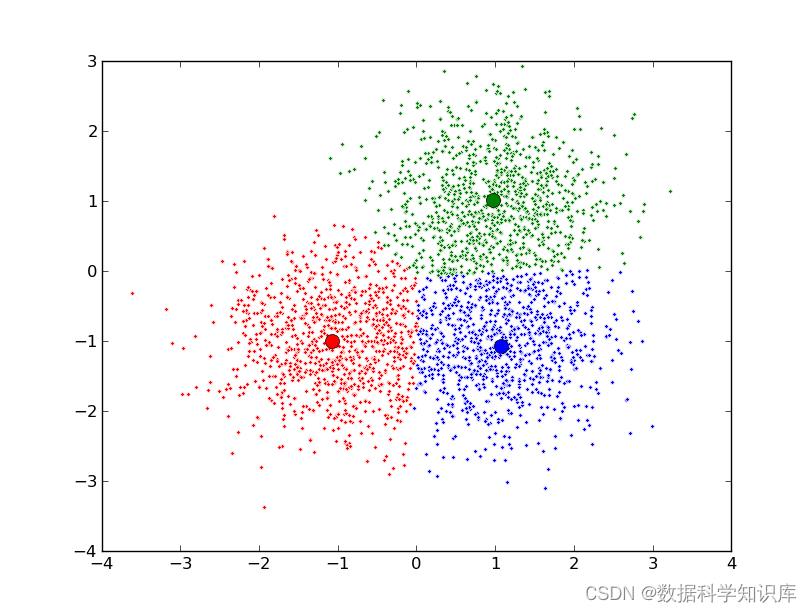
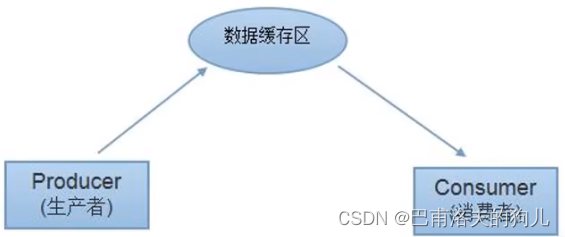
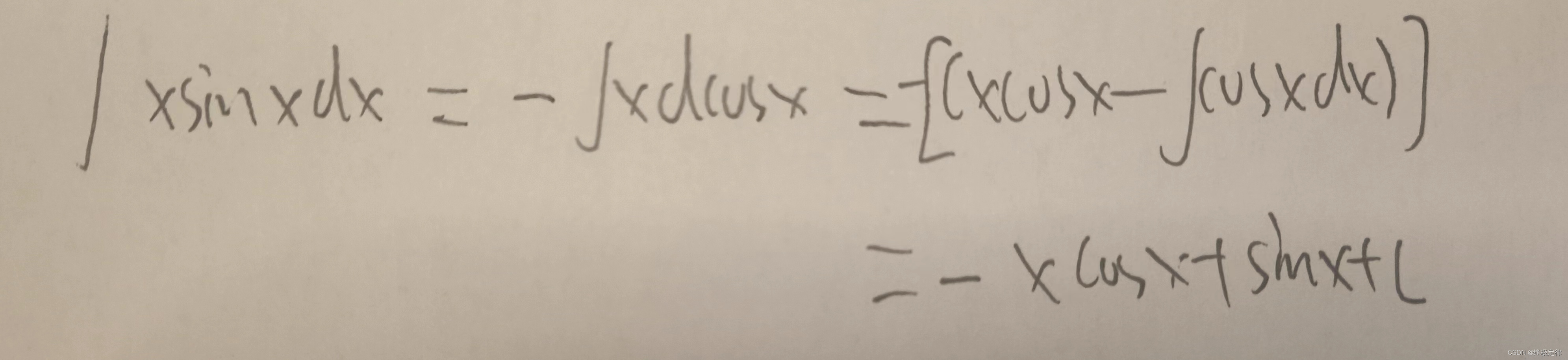1. 指定k个高斯分布參数
导包
import math
import copy
import numpy as np
import matplotlib.pyplot as plt
isdebug = False全局变量 isdebug可以用来控制是否打印调试信息。当 isdebug 为 True 时,代码中的一些调试信
息将被打印出来,方便进行调试。
初始化:
def ini_data(Sigma,Mu1,Mu2,k,N):
global X
global Mu
global Expectations
X = np.zeros((1,N))
Mu = np.random.random(2)
Expectations = np.zeros((N,k))
for i in range(0,N):
if np.random.random(1) > 0.5:
X[0,i] = np.random.normal()*Sigma + Mu1
else:
X[0,i] = np.random.normal()*Sigma + Mu2
if isdebug:
print("***********")
print(u"初始观測数据X:")
print(X)在函数内部,首先使用 numpy 创建了一个形状为 (1, N) 的全零数组 X,用于存储观测数据。然
后,使用 numpy 的 random 模块生成了两个随机数作为均值 Mu 的初始值。接着,创建了一个形
状为 (N, k) 的全零数组 Expectations,用于存储期望值。接下来,使用 for 循环遍历了 N 次,对于
每个观测数据,根据随机生成的概率值,使用 np.random.normal 生成服从正态分布的随机数,并
将其赋值给 X。最后,如果 isdebug 为 True,就打印出初始观测数据 X。
2. EM算法:步骤1,计算E[zij]
def e_step(Sigma,k,N):
global Expectations
global Mu
global X
for i in range(0,N):
Denom = 0
for j in range(0,k):
Denom += math.exp((-1/(2*(float(Sigma**2))))*(float(X[0,i]-Mu[j]))**2)
for j in range(0,k):
Numer = math.exp((-1/(2*(float(Sigma**2))))*(float(X[0,i]-Mu[j]))**2)
Expectations[i,j] = Numer / Denom
if isdebug:
print("***********")
print(u"隐藏变量E(Z):")
print(Expectations)在这段代码中,首先使用两个嵌套的 for 循环遍历观测数据集中的每个样本。在内部的第一个循环
中,计算了分母 Denom,它是高斯分布密度函数的归一化项,用于计算每个样本属于每个分布的
概率。在内部的第二个循环中,计算了分子 Numer,它是样本属于某个分布的概率。然后,将
Numer 除以 Denom,得到每个样本属于每个分布的概率,将这些概率值存储在 Expectations 数组
中。最后,如果 isdebug 为 True,就打印出隐藏变量的期望值 Expectations。
3. EM算法:步骤2,求最大化E[zij]的參数Mu
def m_step(k,N):
global Expectations
global X
for j in range(0,k):
Numer = 0
Denom = 0
for i in range(0,N):
Numer += Expectations[i,j]*X[0,i]
Denom +=Expectations[i,j]
Mu[j] = Numer / Denom 在这段代码中,首先使用一个外部的 for 循环遍历每个分布。在内部的两个嵌套的 for 循环中,分
别计算了 Numer 和 Denom。Numer 是根据每个样本对应的隐藏变量的期望值来加权计算得到的
均值的分子部分,Denom 是对应的分母部分,它是所有样本对应的隐藏变量的期望值的总和。然
后,将 Numer 除以 Denom,得到了更新后的均值 Mu[j]。
4. 迭代过程
def run(Sigma,Mu1,Mu2,k,N,iter_num,Epsilon):
ini_data(Sigma,Mu1,Mu2,k,N)
print(u"初始<u1,u2>:", Mu)
for i in range(iter_num):
Old_Mu = copy.deepcopy(Mu)
e_step(Sigma,k,N)
m_step(k,N)
print(i,Mu)
if sum(abs(Mu-Old_Mu)) < Epsilon:
break
if __name__ == '__main__':
run(6,40,20,2,1000,1000,0.0001)
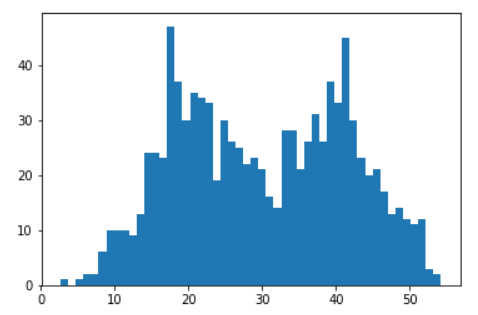
plt.hist(X[0,:],50)
plt.show()该函数用于运行期望最大化(EM)算法来拟合高斯混合模型。函数的参数包括了高斯分布的标准
差 Sigma,两个高斯分布的均值 Mu1 和 Mu2,混合模型中的分布数量 k,观测数据的数量 N,迭
代次数 iter_num 以及精度 Epsilon。在函数内部,首先调用了 ini_data 函数来初始化观测数据 X、
均值 Mu 和期望 Expectations。然后,进入一个 for 循环,循环次数为 iter_num。在每次迭代中,
记录下当前的均值 Mu,然后执行 E 步骤和 M 步骤,即调用 e_step 和 m_step 函数来更新隐藏变
量的期望值和更新每个分布的均值。在每次迭代后,打印出当前的均值 Mu。最后,如果当前迭代
的均值变化小于设定的精度 Epsilon,就跳出循环,算法结束。